First, the machine translation and related technologies
Machine Translation (MT): a piece of text automatically translated from one language to another language, neural network to solve this problem is often called nerve machine translation (NMT). Main features: word sequence is output rather than a single word. The length of the output sequence may be different from the length of the source sequence.
Second, the attention mechanism model and Seq2seq
Attention mechanism
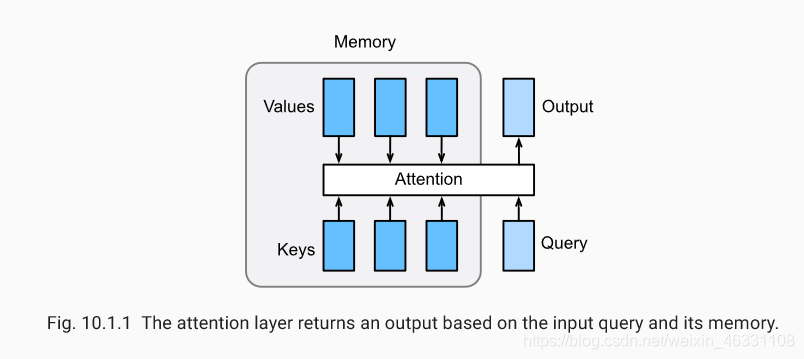
in the "coder - decoder (seq2seq)" ⼀ section ⾥, the decoder the same step at various times dependent variable background (context vector) to obtain sequence information input START. When the encoder is a recurrent neural Open networks, background hidden variables which automatically final time step. The source input information sequence coded in a cyclic state unit, and then passed to the decoder to generate a target sequence. However, this structure there is a problem, especially the problem of the presence of long-range gradients disappear actual RNN mechanisms, for longer sentences, it is difficult to hope that the input sequence is converted into fixed-length vector and save all the useful information, Therefore, with increasing length of the translated sentence is desired, the effect of this structure will be significantly reduced.
At the same time, the target words may be decoded only with some words about the original input, and not related to any input. For example, when the "Hello world" translated "Bonjour le monde", "Hello" mapped "Bonjour", "world" mapped "monde". In seq2seq model, the decoder can implicitly selecting the corresponding information from the final state of the encoder. However, such a mechanism may focus the selection process explicitly modeled.
Three, Transformer
In order to integrate the advantages of RNN and CNN, [Vaswani et al., 2017] innovative use of attentional mechanisms designed the Transformer model. In this model, attention capture mechanism to achieve parallelization of sequence-dependent, and simultaneously processing the location of each sequence of tokens of the advantages of such excellent performance in Transformer model and also reduces training time.
10.3.1 shows the architecture of FIG Transformer model, and the model 9.7 seq2seq similar, also based Transformer encoder - decoder architecture, which differ primarily in the following three points:
Transformer blocks: the seq2seq model for alternative network re-circulation Transformer Blocks, the module comprises a long attention layer (Multi-head Attention Layers) and two position-wise feed-forward networks ( FFN). For the decoder, the other long attention is hidden layer for receiving the encoder.
Add and norm: long focus and output layer feedforward network is supplied to two layers "add and norm" is processed, the layer structure and a layer comprising a residual normalized.
Position encoding: due to self-focus layer sequence does not distinguish between the elements, so that a position of the coding layer is used to add position information to the elements in sequence.

