1Seq2Seq
1.1 Introduction
- For the sequence pair <X,Y>, our goal is to give the input sequence X and expect to generate the target sequence Y through the Encoder-Decoder framework.
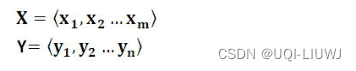
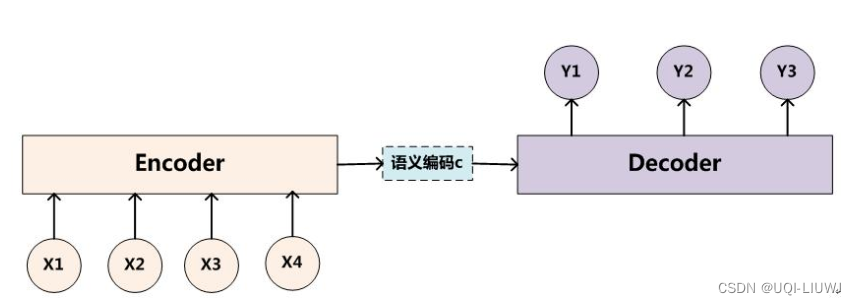
- Encoder encodes the input sequence X and converts the input sequence into an intermediate semantic representation C through non-linear transformation:
- Decoder generates the next value to be generated at time i based on the intermediate semantic representation C of the sequence X and the previously generated historical information y1, y2….yi-1: yi
1.2 Disadvantages
- The Encoder-Decoder framework has an obvious shortcoming.
- Encoder will encode the input sequence X into a fixed-length latent vector (semantic encoding c)
- 1. The size of the latent vector is limited and cannot represent information-rich sequences;
- 2. Due to the characteristics of RNN-type networks, the network will pay more attention to the information behind the sequence and cannot grasp the overall situation.
- Encoder will encode the input sequence X into a fixed-length latent vector (semantic encoding c)
2 attentioned Seq2Seq
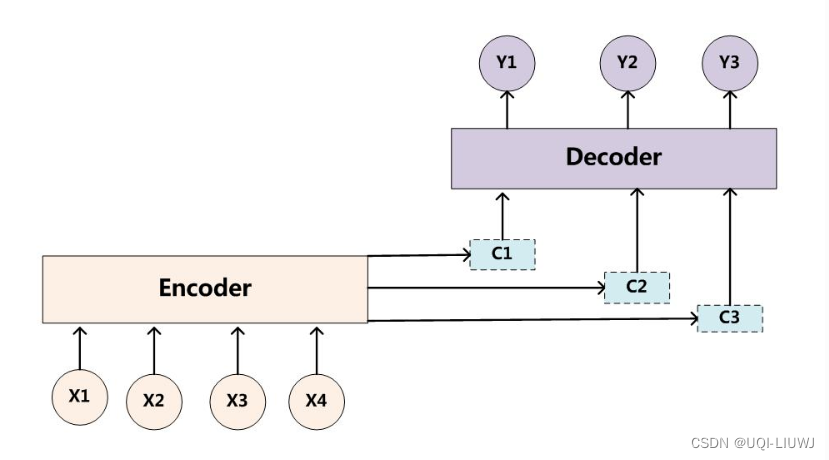
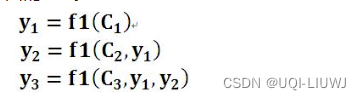
where: the semantic encoding ci of each element:
hj is the hidden state of each element of the encoder, αij is the weighting coefficient
4
st-1 is the output of decoder t-1 position


