sequence
Sequence comprises: a string, a tuple, list
Available operations
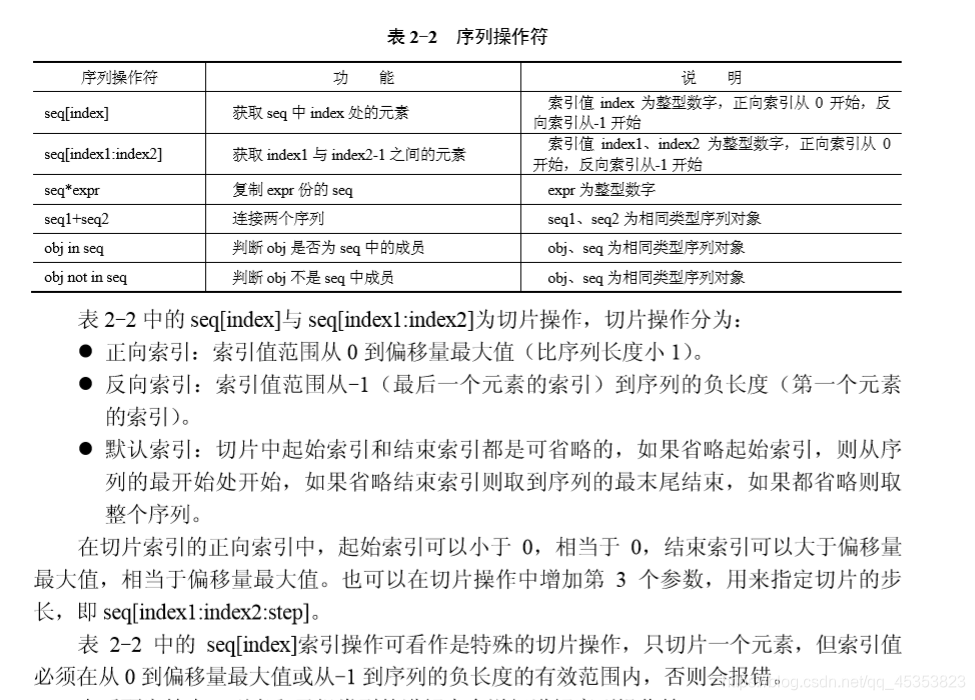
Indexing and slicing
s='hello'
print(s[0])#h
print(s[1:3])#el
print(s[:])#hello
print(s[-5:0])#hello
print(s[-5:-1])#hello
Jointly support the sequence function
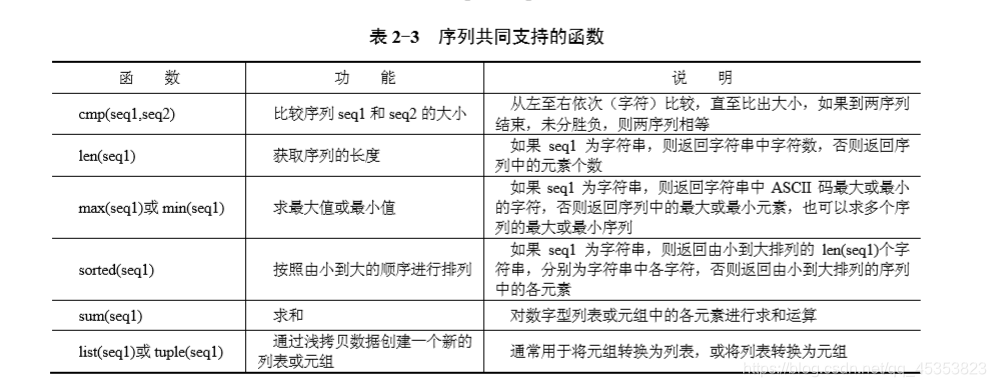
s1="abc"
s2="abd"
s3="das"
s4=[1,2,3]
print(len(s1))# 字符串长度
print(max(s1))#寻找序列中最大的
print(sorted(s3))#['a', 'd', 's']
print(sum(s4))# 求和
The original string
For some string escaped without escaping, but printed out in accordance with the original look
s1="asdd\nsad"
s2=r"asdd\nsad"
print(s1)
print(s2)
Print results:
asdd
SAD
asdd \ NSAD
If the string is not in front of r add, will escape to the escape character, r will be added according to the original character string into the output
Formatting operator
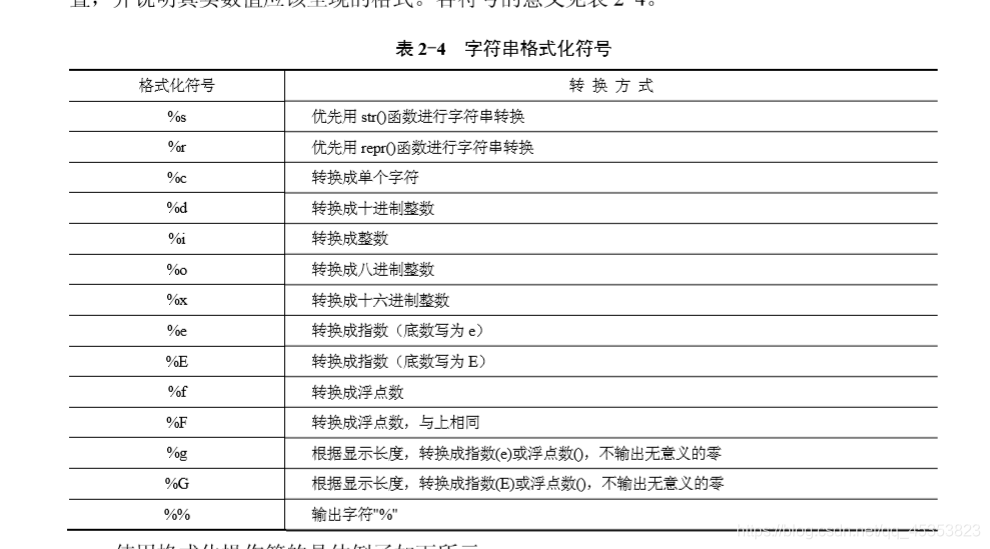
Code:
s='I Love %s'%"China"
print(s)#I Love China
s2="ASCII(%c)-67"%67 # ASCII值为67的为C
print(s2)#ASCII(C)-67
Auxiliary character format
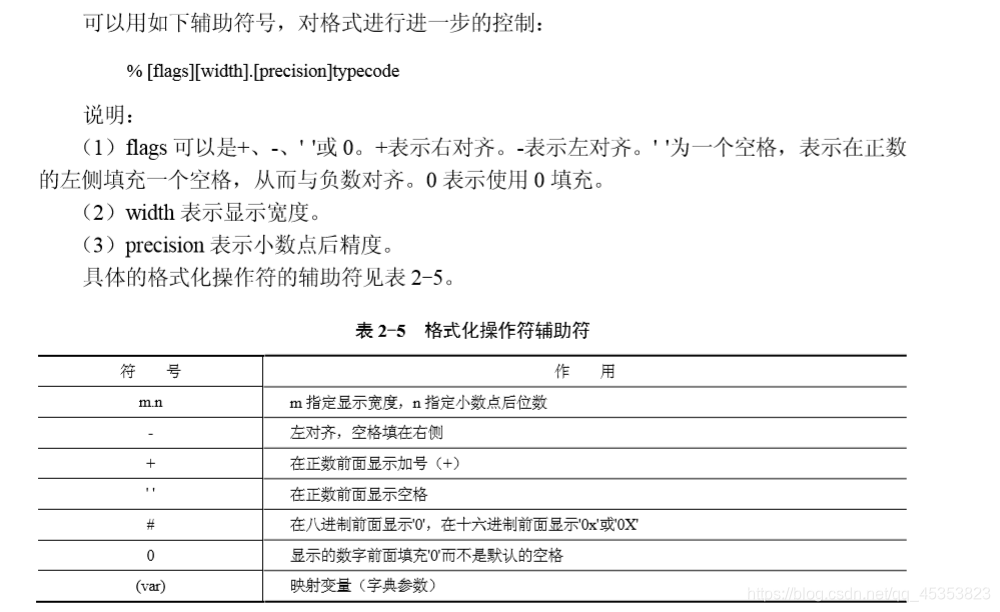
s="%5.2f" %3.1415926
print(s)#3.14
s2="%#x"%45
print(s2)#0x2d
The number n to the number of width m, and can be used after the decimal point (asterisk) into two dynamic variables, in other words the m, n represented by the asterisk, and then later added to, look at the code Experience look, you know, a good understanding of
s="%.*f"%(5,2.3)
print(s)# 2.30000
s2="%*.*f"%(5,2,3.1415)
print(s2)# 3.14
String built-in functions
(1) string to space
s=' abc '
s2='abca'
print(s.strip())#abc
print(s.rstrip())# abc 去除右边的空格
print(s.lstrip())#abc 去除左边的空格
print(s2.strip('a'))# 去除a bc
print(s2.lstrip('a'))# 去除左边的a bca
print(s2.rstrip('a'))# 去除右边的a abc
(2) The connection string
join the distinction +

a="hello"
print(a.join('ab'))#ahellob
print(a)#hello
b="".join('ab')
print(b)# ab
str = "-";
seq = ("a", "b", "c") #字符串序列
print (str.join(seq))#a-b-c
print("%s%s%s"%(a,'ab','cd'))# helloabcd
It is worth noting that the use of non-% dictionaries can convert the string to a string, and it will not join, will complain

(3) a combination of segmentation and
b="I Am a student"
print(b.split(" "))#['I', 'Am', 'a', 'student']
print(b.split(" ",2))#['I', 'Am', 'a student']
print(b.rsplit(" ",2))#['I Am', 'a', 'student']
(3) query
b="I Am a student"
print(b.split(" "))#['I', 'Am', 'a', 'student']
print(b.split(" ",2))#['I', 'Am', 'a student']
print(b.rsplit(" ",2))#['I Am', 'a', 'student']
print(b.find('I'))#0
print(b.find('st'))#7返回第一个查到的字符
print(b.find('s',0,4))#-1 从下表0到4
print(b.index('a'))# 5
print(b.index('a',0,3))#
ValueError: #substring not found
The only difference between the index and find methods that, when the index search, if the error will not find, but can not find the find method will return -1
number (4) statistical character
b="I Am a student heihei"
print(b.count('e'))#3
print(b.count('e',0,12))#1
Character replacement
b="I Am a student heihei"
print(b.replace('e','a'))#I Am a studant haihai
print(b.replace('e','a',1))#替换次数不超过1次 #I Am a studant heihei
The test string, the judging function
To determine whether a character to begin with
b="I Am a student heihei"
print(b.startswith('I'))#True
print(b.startswith('Am',2,4))#True
To determine whether the end of a certain character
b="I Am a student heihei"
print(b.endswith('hei'))#True
print(b.endswith('hie',3,6))#False
Other methods

