Foreword
Today is the last to bring crawling system to obtain transcripts of the Senate version of sisters - crawling Dean individual semester curriculum.
tool
Use pycharm editor, install selenium library, beautifulsoup library, csv library, of course, you need to download the corresponding version chromedriver corresponding download link Download
Need access interface
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.select import Select
from bs4 import BeautifulSoup
import time
import csv
Setting parameters
#模拟登陆终端文件路径
driver_path = r'E:\py\chromedriver\chromedriver.exe'
#生成csv文件路径
csv_file_path = r'E://py//个人学期课程表.csv'
#登录教务系统的账号与密码
UserId = '账号'
PassWord = '密码'
#实现后台登陆浏览器
chrome_options = Options()
chrome_options.add_argument('--disable-gpu') #关闭GPU对网页的加速,防止网页过多卡住
chrome_options.add_argument('--headless')#进行无头后台运行浏览器
#更改代理ip防反爬虫
#chrome_options.add_argument(f"--proxy-server=121.52.208.200:808")
driver = webdriver.Chrome(executable_path = driver_path, chrome_options=chrome_options)
Login simulation
Analog Log, and then find the corresponding input box enter the account password with the position of the driver find_element_by_ ×, click log page transition series of operations, driver.implicitly_wait(1)is too slow to prevent the page loads, resulting in the next step directly crawl errors, particularly self Baidu
driver.get('http://jwgln.zsc.edu.cn/jsxsd/')
driver.implicitly_wait(1)
#输入登录账号
try:
driver.find_element_by_id("userAccount").send_keys(UserId)
print('输入账号成功!')
except:
print('输入账号失败!')
# 输入登录密码
try:
driver.find_element_by_id("userPassword").send_keys(PassWord)
print('输入密码成功!')
except:
print('输入密码失败!')
# 点击登录
try:
driver.find_element_by_xpath('//*[@id="btnSubmit"]').click() # 用click模拟浏览器点击
print('正在登录...')
except:
print('登录失败!')
driver.implicitly_wait(1)
if '用户名或密码错误' in driver.page_source:
print('登录失败,用户名或密码错误,请查证账号密码是否准确。')
exit(0)
else:
print('登录成功!')
# 点击学业情况
try:
driver.find_element_by_xpath('//*[@class="block4"]').click()
print('点击培养方案成功!')
except:
print('点击培养方案失败!')
driver.implicitly_wait(1)
#点击课程成绩查询
try:
driver.find_element_by_xpath('//*[@href="/jsxsd/xskb/xskb_list.do"]').click()
time.sleep(1)
print('我的学期课表点击成功!')
except:
print('我的学期课表点击失败!')
Followed by difficulty
Click semester curriculum is no timetable default date will alert pop-ups need to simulate clicks
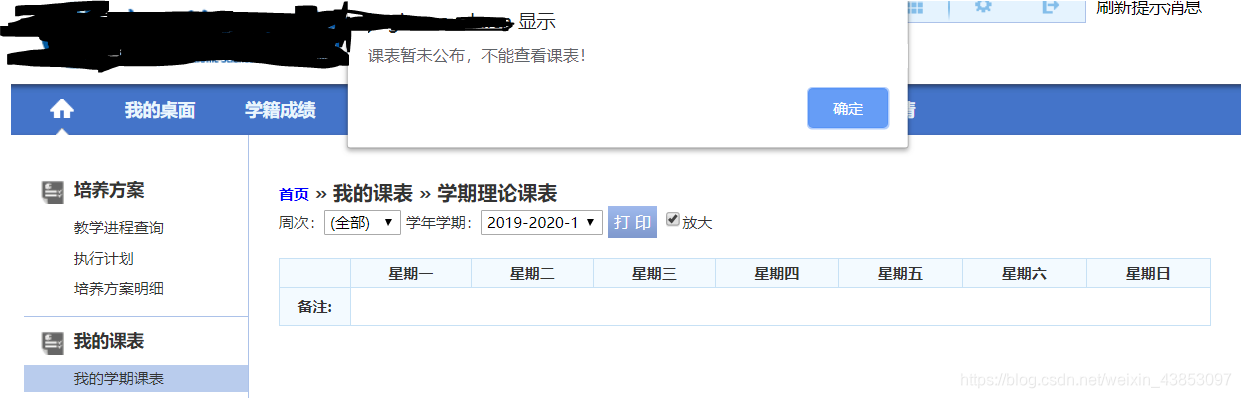
#页面弹窗点击确认
try:
alt = driver.switch_to_alert()
alt.accept()
except:
pass
Followed by a drop-down box to select the date
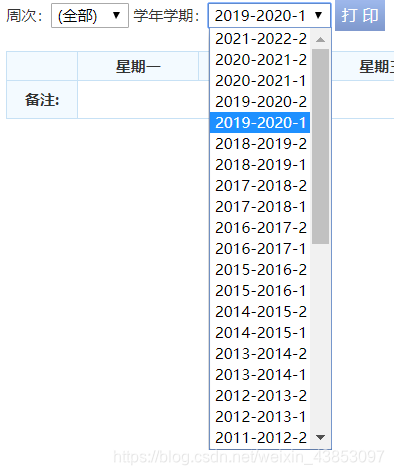
to check the page elements
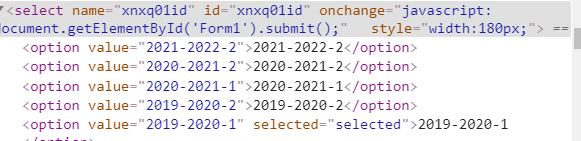
using the Select to select their desired date, click on the code is as follows
#选择准确学期
#driver.find_element_by_xpath(".//*[@id='xnxq01id']/option[4]").click()
# 若此时点击后,下拉选项未收回,可点击整个下拉框,收回下拉选项
#driver.find_element_by_xpath(".//*[@id='nr']").click()
try:
Select(driver.find_element_by_id("xnxq01id")).select_by_value("2019-2020-2").click()
except:
pass
Data cleansing
Beautifulsoup is used to filter the data needed
soup = BeautifulSoup(driver.page_source,'lxml')
page = soup.find_all('div',attrs={'class': "kbcontent"})
teachers1,teachers2 = [],[]
weeks1,weeks2= [],[]
classrooms1,classrooms2= [],[]
for i in page:
teachers1.append(i.find('font',attrs={'title':'老师'}))
weeks1.append(i.find('font',attrs={'title':'周次(节次)'}))
classrooms1.append(i.find('font', attrs={'title': '教室'}))
my_detail = list(page)
for i in teachers1:
if i == None:
teachers2.append('\n')
else:
teachers2.append(i.string)
for i in weeks1:
if i == None:
weeks2.append('\n')
else:
weeks2.append('\n'+i.string)
for i in classrooms1:
if i == None:
classrooms2.append('\n')
else:
classrooms2.append('\n'+i.string)
all_data = []
pitch_number = ['(上午)\n第1,2节\n(08:00-08:45)\n(08:55-09:40)','第3,4节\n(10:00-10:45)\n(10:55-11:40)',
'(下午)\n第5,6节\n(14:30-15:15)\n(15:25-16:10)','第7,8节\n(16:20-16:05)\n(17:15-18:00)',
'(晚上)\n第9,10节\n(19:30-20:15)\n(20:25-21:10)','第11,12节','第13,14节']
temp = []
temp.append(pitch_number[0])
num = 0
pnum = 0
for i in range(len(my_detail)):
if my_detail[i].text == '\xa0':
temp.append('\n\n\n')
else:
temp.append(my_detail[i].text.split(teachers2[i])[0]+'\n'+teachers2[i]+weeks2[i]+classrooms2[i])
num = num + 1
if num == 7:
all_data.append(temp)
temp = []
pnum = pnum + 1
temp.append(pitch_number[pnum])
num = 0
page2 = soup.find('td',attrs={'colspan':"7"})
BZ = ['备注:'+page2.text,'\n','\n','\n','\n','\n','\n','\n']
all_data.append(BZ)
Makefile
f = open(csv_file_path, 'w', newline='')
csv_write = csv.writer(f)
csv_write.writerow(['课程时间','星期一','星期二','星期三','星期四','星期五','星期六','星期日'])
#设置列表的头部,就是各个列的列名
#再按列的长度每次输入一个列表进去生成一行
for i in range(len(all_data)):
csv_write.writerow(all_data[i])
f.close()
print('生成csv文件成功')
All codes
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.select import Select
from bs4 import BeautifulSoup
import time
import csv
'''
@author Himit_ZH
Date:2020.01.20
'''
#模拟登陆终端文件路径
driver_path = r'E:\py\chromedriver\chromedriver.exe'
#生成csv文件路径
csv_file_path = r'E://py//个人学期课程表.csv'
#登录教务系统的账号与密码
UserId = '账号'
PassWord = '密码'
#实现后台登陆浏览器
chrome_options = Options()
chrome_options.add_argument('--disable-gpu') #关闭GPU对网页的加速,防止网页过多卡住
chrome_options.add_argument('--headless')#进行无头后台运行浏览器
#更改代理ip防反爬虫
#chrome_options.add_argument(f"--proxy-server=121.52.208.200:808")
driver = webdriver.Chrome(executable_path = driver_path, chrome_options=chrome_options)
driver.get('http://jwgln.zsc.edu.cn/jsxsd/')
driver.implicitly_wait(1)
#输入登录账号
try:
driver.find_element_by_id("userAccount").send_keys(UserId)
print('输入账号成功!')
except:
print('输入账号失败!')
# 输入登录密码
try:
driver.find_element_by_id("userPassword").send_keys(PassWord)
print('输入密码成功!')
except:
print('输入密码失败!')
# 点击登录
try:
driver.find_element_by_xpath('//*[@id="btnSubmit"]').click() # 用click模拟浏览器点击
print('正在登录...')
except:
print('登录失败!')
driver.implicitly_wait(1)
if '用户名或密码错误' in driver.page_source:
print('登录失败,用户名或密码错误,请查证账号密码是否准确。')
exit(0)
else:
print('登录成功!')
# 点击学业情况
try:
driver.find_element_by_xpath('//*[@class="block4"]').click()
print('点击培养方案成功!')
except:
print('点击培养方案失败!')
driver.implicitly_wait(1)
#点击课程成绩查询
try:
driver.find_element_by_xpath('//*[@href="/jsxsd/xskb/xskb_list.do"]').click()
time.sleep(1)
print('我的学期课表点击成功!')
except:
print('我的学期课表点击失败!')
#页面弹窗点击确认
try:
alt = driver.switch_to_alert()
alt.accept()
except:
pass
#选择准确学期
#driver.find_element_by_xpath(".//*[@id='xnxq01id']/option[4]").click()
# 若此时点击后,下拉选项未收回,可点击整个下拉框,收回下拉选项
#driver.find_element_by_xpath(".//*[@id='nr']").click()
try:
Select(driver.find_element_by_id("xnxq01id")).select_by_value("2019-2020-2").click()
except:
pass
print('开始进行数据整理')
#对获取的数据进行整理
soup = BeautifulSoup(driver.page_source,'lxml')
page = soup.find_all('div',attrs={'class': "kbcontent"})
teachers1,teachers2 = [],[]
weeks1,weeks2= [],[]
classrooms1,classrooms2= [],[]
for i in page:
teachers1.append(i.find('font',attrs={'title':'老师'}))
weeks1.append(i.find('font',attrs={'title':'周次(节次)'}))
classrooms1.append(i.find('font', attrs={'title': '教室'}))
my_detail = list(page)
for i in teachers1:
if i == None:
teachers2.append('\n')
else:
teachers2.append(i.string)
for i in weeks1:
if i == None:
weeks2.append('\n')
else:
weeks2.append('\n'+i.string)
for i in classrooms1:
if i == None:
classrooms2.append('\n')
else:
classrooms2.append('\n'+i.string)
all_data = []
pitch_number = ['(上午)\n第1,2节\n(08:00-08:45)\n(08:55-09:40)','第3,4节\n(10:00-10:45)\n(10:55-11:40)',
'(下午)\n第5,6节\n(14:30-15:15)\n(15:25-16:10)','第7,8节\n(16:20-16:05)\n(17:15-18:00)',
'(晚上)\n第9,10节\n(19:30-20:15)\n(20:25-21:10)','第11,12节','第13,14节']
temp = []
temp.append(pitch_number[0])
num = 0
pnum = 0
for i in range(len(my_detail)):
if my_detail[i].text == '\xa0':
temp.append('\n\n\n')
else:
temp.append(my_detail[i].text.split(teachers2[i])[0]+'\n'+teachers2[i]+weeks2[i]+classrooms2[i])
num = num + 1
if num == 7:
all_data.append(temp)
temp = []
pnum = pnum + 1
temp.append(pitch_number[pnum])
num = 0
page2 = soup.find('td',attrs={'colspan':"7"})
BZ = ['备注:'+page2.text,'\n','\n','\n','\n','\n','\n','\n']
all_data.append(BZ)
f = open(csv_file_path, 'w', newline='')
csv_write = csv.writer(f)
csv_write.writerow(['课程时间','星期一','星期二','星期三','星期四','星期五','星期六','星期日'])
for i in range(len(all_data)):
csv_write.writerow(all_data[i])
f.close()
print('生成csv文件成功')
driver.close()
driver.quit()
