During the winter vacation, the instructor asked me if I could use a crawler to crawl into the school's educational administration system, and sent a project written by someone else for me to study. But in fact, that code can't successfully log in to our school's educational system, and I don't know about other schools from time to time. During that time, I studied the code of that project for a long time and found no problems. A few days ago, I suddenly recalled this incident, so I tried to climb again, but I didn’t expect it to be successful, so I’ll share it and let’s make progress together!
First, observe the website we want to crawl:
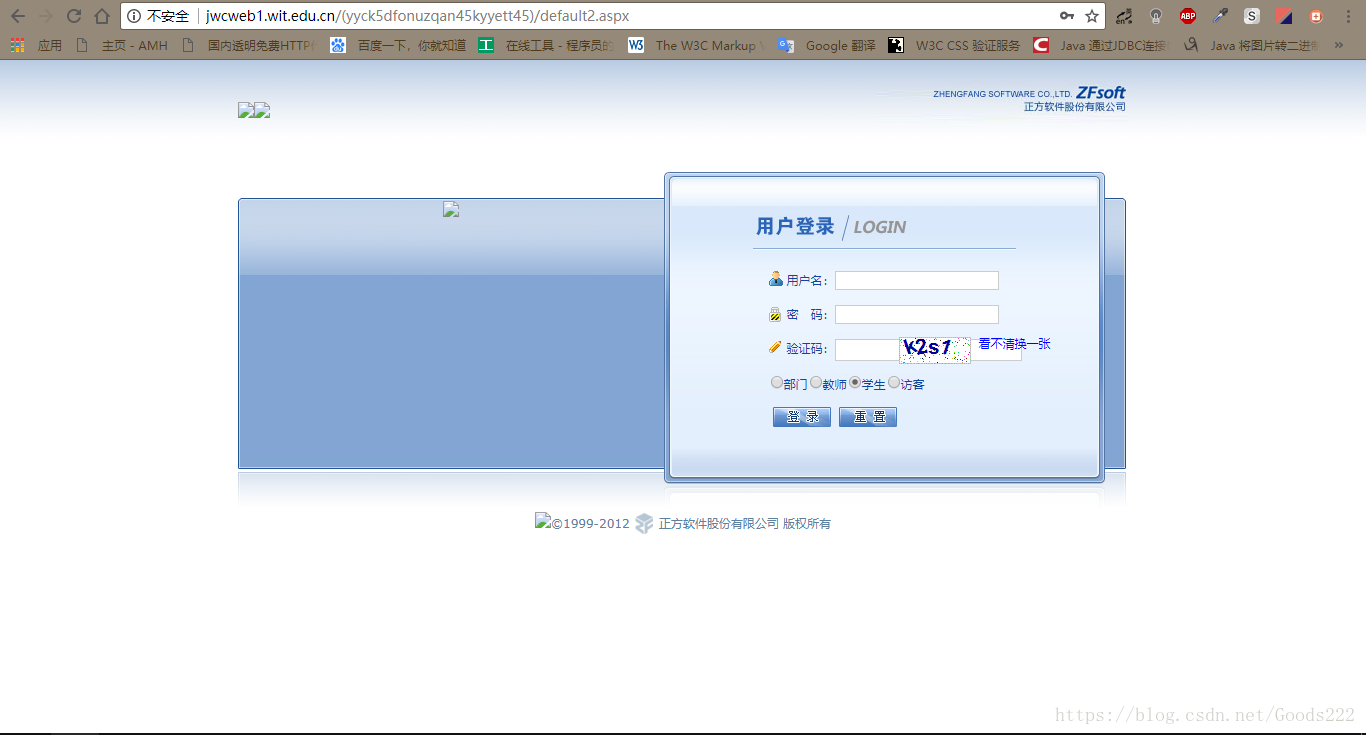
As can be seen from the figure, the website we want to crawl is jwcweb1.wit.edu.cn, and the login page is default2.aspx. The part with brackets in the middle, I didn't pay attention to it when I climbed for the first time, and I couldn't climb it in the end. We will talk about it later.
First, do some routine processing and build a SpiderMain class for the main processing of the crawler.
class Spider:
def __init__(self):
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0",
"Content-Type": "image/Gif; charset=gb2312"
}Observe the html of the login page,

you can see that the verification code is obtained from the CheckCode.aspx page.
So build another class to store the relevant url.
class URL:
urlStart = "http://jwcweb1.wit.edu.cn/"
urlLogin = "default2.aspx"
urlImage = "CheckCode.aspx"
def __init__(self, session):
self.session = session
self.url = self.urlStart + session + "/" + self.urlLogin
self.ImageUrl = self.urlStart + session + "/" + self.urlImage
def getURL(self):
return self.url
def getImageUrl(self):
return self.ImageUrlLet's take a look at the part with brackets in the middle of the login interface address. At first, I didn't deal with it, but added default2.aspx directly. I didn't expect that there would be a problem with climbing. If you think about it, this might be the ID of the session stored by the server. This should be the first time this interface is opened, and the server generates it by itself. After that, I did an experiment. When entering the URL, I created a session ID and sent it to the past, and let the server generate a session for us using this ID as the ID. You might ask, why not get this in the code, but make it yourself. The reason is that I tried, this part is hidden in the URL and cannot be obtained. Well, let's generate another class to generate our own session ID.
import random
class RandomSessionID:
sessionID = "("
def __init__(self):
counter = 24
while counter:
number = int(random.random() * 26)
c = chr(number + 97)
self.sessionID += c
counter -= 1
self.sessionID += ')'
def getSessionID(self):
return self.sessionIDHaha, I use all lowercase, you can also mix uppercase and lowercase numbers, no problem.
Everything is ready, let's start our operation.
Implement a method in the SpiderMain class to log in.
self.stuID = input("请输入你的学号:")
self.stuPSW = input("请输入你的密码:")
s = requests.Session()
post = s.post(self.addr)
soup = BeautifulSoup(post.content, "html.parser")
print(soup.find("title").string)First obtain the student ID and password to log in. Generate another session, and then perform post and get operations in this session. Post first, let the server generate this session. After the connection is made, the content in the title is displayed, which is a sign we use to judge whether it is successful.
Log in again successfully and observe what the data we sent is.
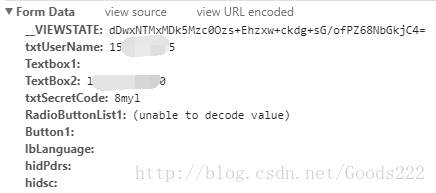
As you can see, this is the content of the data sent in the past. Then, let's download the verification codes, enter them manually, and send them together. Get the title content again, as you can see, it is successful.
self.code = input("请输入验证码:")
RadioButtonList1 = u"学生".encode('gb2312', 'replace')
data = {
"__VIEWSTATE": self.__VIEWSTATE,
"txtUserName": self.stuID,
"Textbox1": "",
"TextBox2": self.stuPSW,
"txtSecretCode": self.code,
"RadioButtonList1": RadioButtonList1,
"Button1": "",
"lbLanguage": "",
"hidPdrs": "",
"hidsc": ""
}
str = self.addr + self.encodeHeader(**data)
req = s.get(str)
soup = BeautifulSoup(req.content, "html.parser")
print(soup.find("span", id="Label3").string + soup.find("span", id="xhxm").string)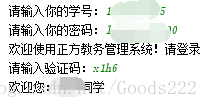
Well, this blog is mainly to record a lesson and experience of my own crawler this time. If I can help you, then I'm glad. The code is not all provided, just to give an idea. If you want to study the full code, you can download it here: https://download.csdn.net/download/goods222/10364139