Scrapy framework
The reason why Scrapy is a framework, not a simple library, the difference is that it has more powerful functions than ordinary libraries, and the most commonly used functions are LinkExtractors, automatic login, and image downloader. .
Link extractors (LinkExtractors)
The crawler generation carrying the link extractor is different from our conventional crawler generation, and it needs to carry more parameters.
scrapy genspider -t crawl 爬虫名字 域名
If you think it is troublesome to create and start a crawler every time, you can build a .py file like me to start and create a crawler

from scrapy import cmdline
class RunItem:
def __init__(self, name, url=None):
# 爬虫名字
self.name = name
# 域名
self.url = url
# 启动爬虫
def start_item(self):
command = ['scrapy', 'crawl', self.name]
print('爬虫已启动')
cmdline.execute(command)
# 新建爬虫
def new_item(self, auto_page=False):
# 创建自动翻页爬虫(此爬虫会自动提取网页中的连接)
if auto_page:
command = ['scrapy', 'genspider', '-t', 'crawl', self.name, self.url]
cmdline.execute(command)
# 创建正常爬虫
else:
command = ['scrapy', 'genspider', self.name, self.url]
cmdline.execute(command)
Just use the class above me, you can also write one more suitable for yourself.
At this time, for example, I like to create a crawler to ask the government official website, a crawler with a link extractor, only need to execute RunItem('yg', 'wz.sun0769.com').new_item(True).
After the creation, we found that the crawler carrying the link extractor is different from the ordinary crawler in two places, one is a rule
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
Another point is that our approach has parsechanged parse_item.
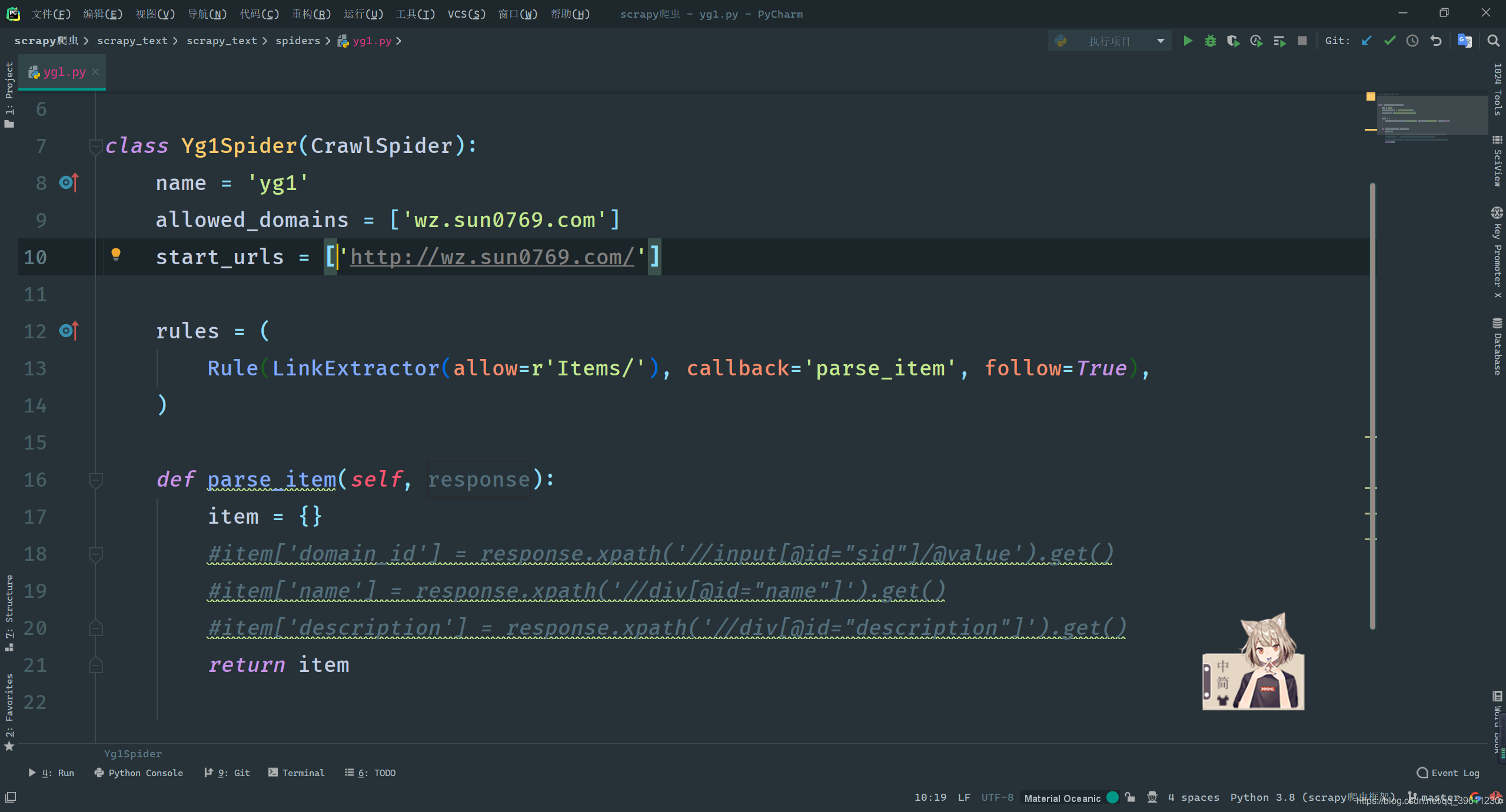
Note: We can't create a def parse(self):method using a crawler that carries a link extractor , because this method is used to write a link extractor. If you use it, you will overwrite the link extractor, which will prevent automatic extraction of links. Unless you want to rewrite the link extractor.
Rule与LinkExtractor
Rules stipulate that those useful links (LinkExtractor) are extracted from the website, and those operations (Rule) are performed after extraction. We can create multiple rules so that each link has different actions.
Let's briefly introduce those commonly used attributes in Rule and LinkExtractor
- Automatically extract connection rules:
Rule(连接提取器, [callback,follow,process_links])- callback: The function of url callback that meets this condition
- follow: Whether to enable circular extraction (extract URLs that meet the conditions from the extracted pages)
- process_links: After obtaining the link from the link_extractor, it will be passed to this function to filter the links that do not need to be crawled.
- In addition to the above commonly used, there are: cb_kwargs, process_request, errback.
- Connection extractor:
LinkExtractor()- allow: Allowed url. All URLs that satisfy this regular expression will be extracted.
- deny: Forbidden URL. All URLs that satisfy this regular expression will not be extracted.
- allow_domains: Allowed domain names. Only the URL of the domain name specified here will be extracted.
- deny_domains: Forbidden domain names. All the URLs of the domain names specified here will not be extracted.
- restrict_xpaths: strict xpath. Filter links with allow.
- In addition to the above common attributes: tags, attrs, canonicalize, unique, process_value, deny_extensions, restrict_css, strip, restrict_text
Practical demonstration
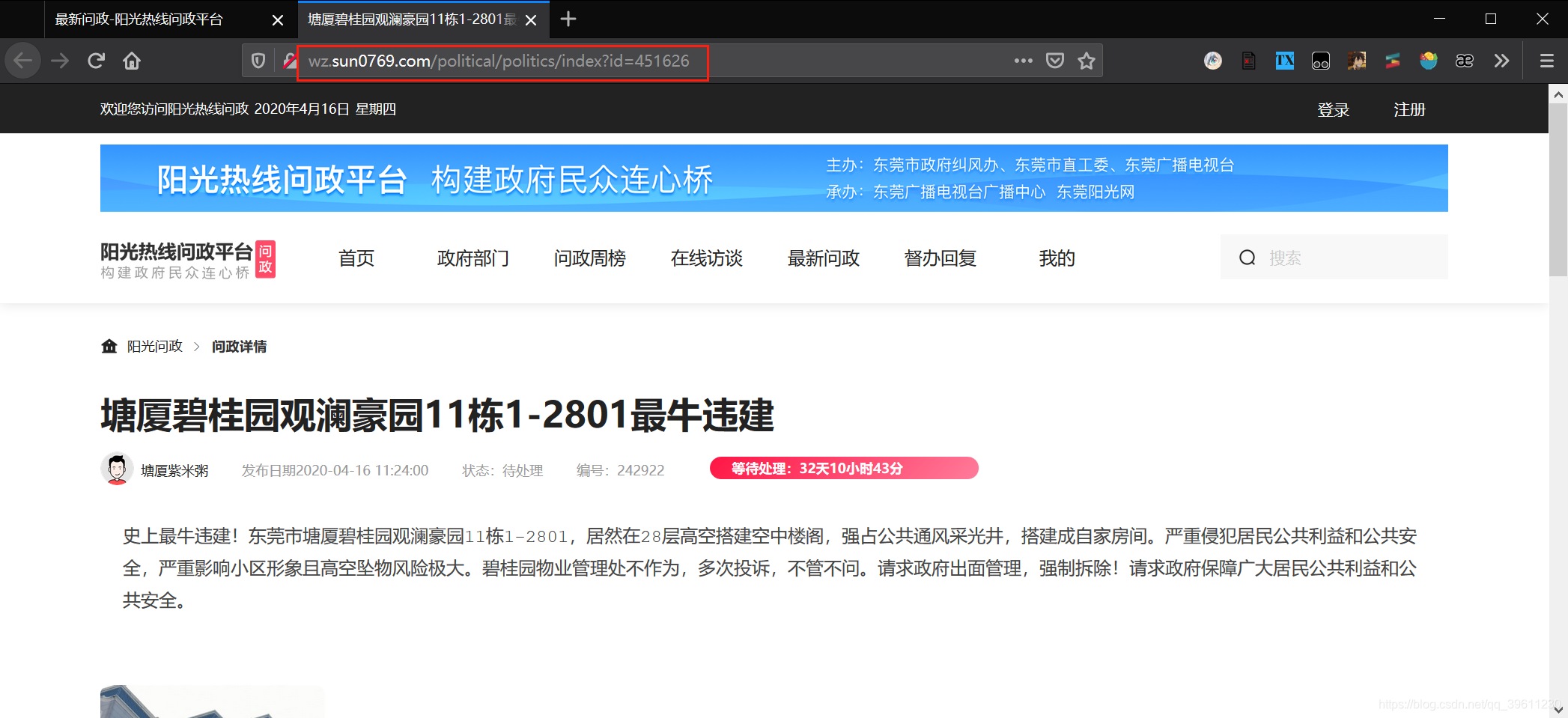
Scrapy link extractor has a very useful place is that we can see through the console that the jump link of this website is not a complete link, but our link extractor will automatically complete it into a complete link After screening!
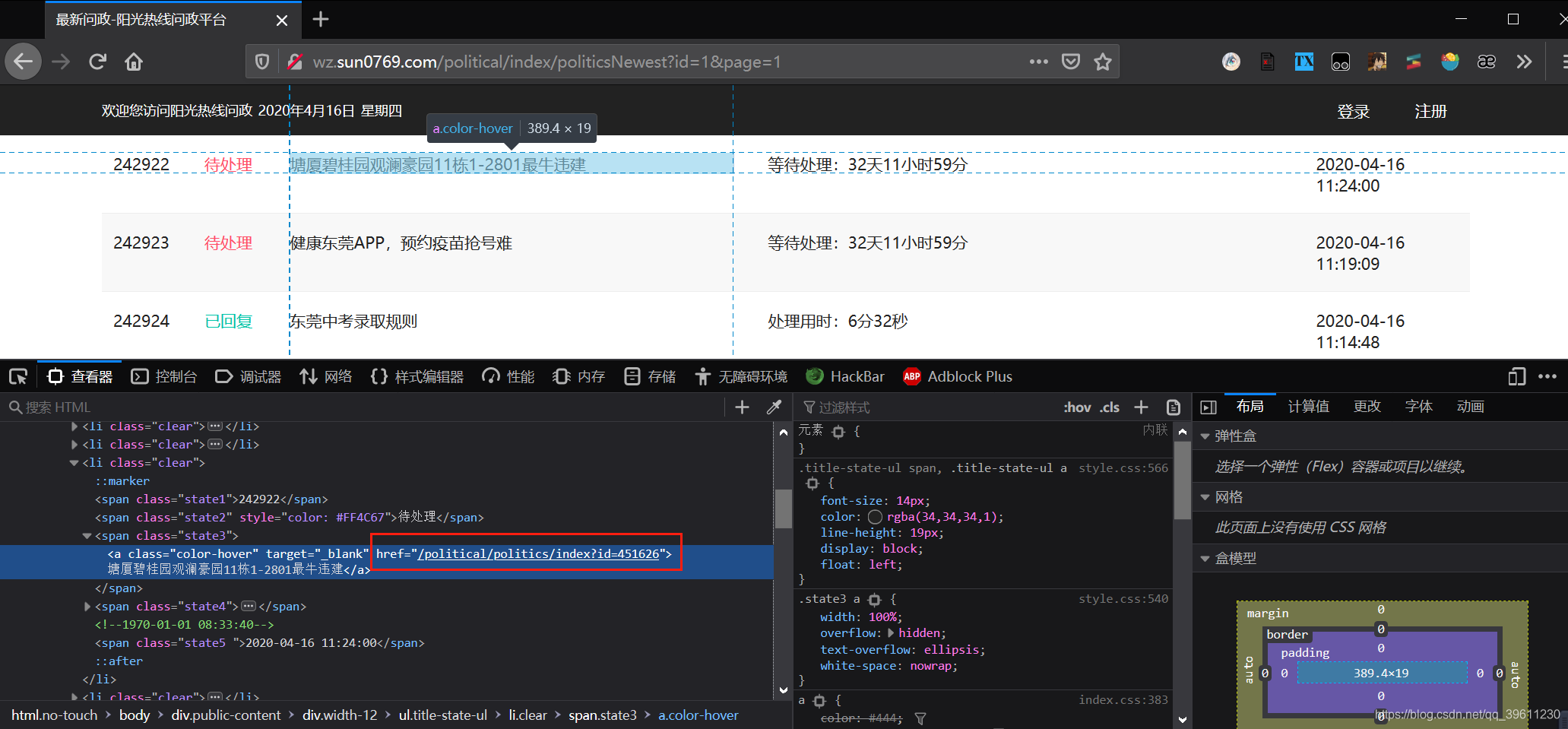
That is, we put a link extractor for regular screening of links based on the link http://wz.sun0769.com/political/politics/index?id=451626rewrite can open multiple pages, we found that only id number will change, then we are simply out to id \d+(regex \ d represents The number + means more than one, and it is connected together to be 'more than one number')
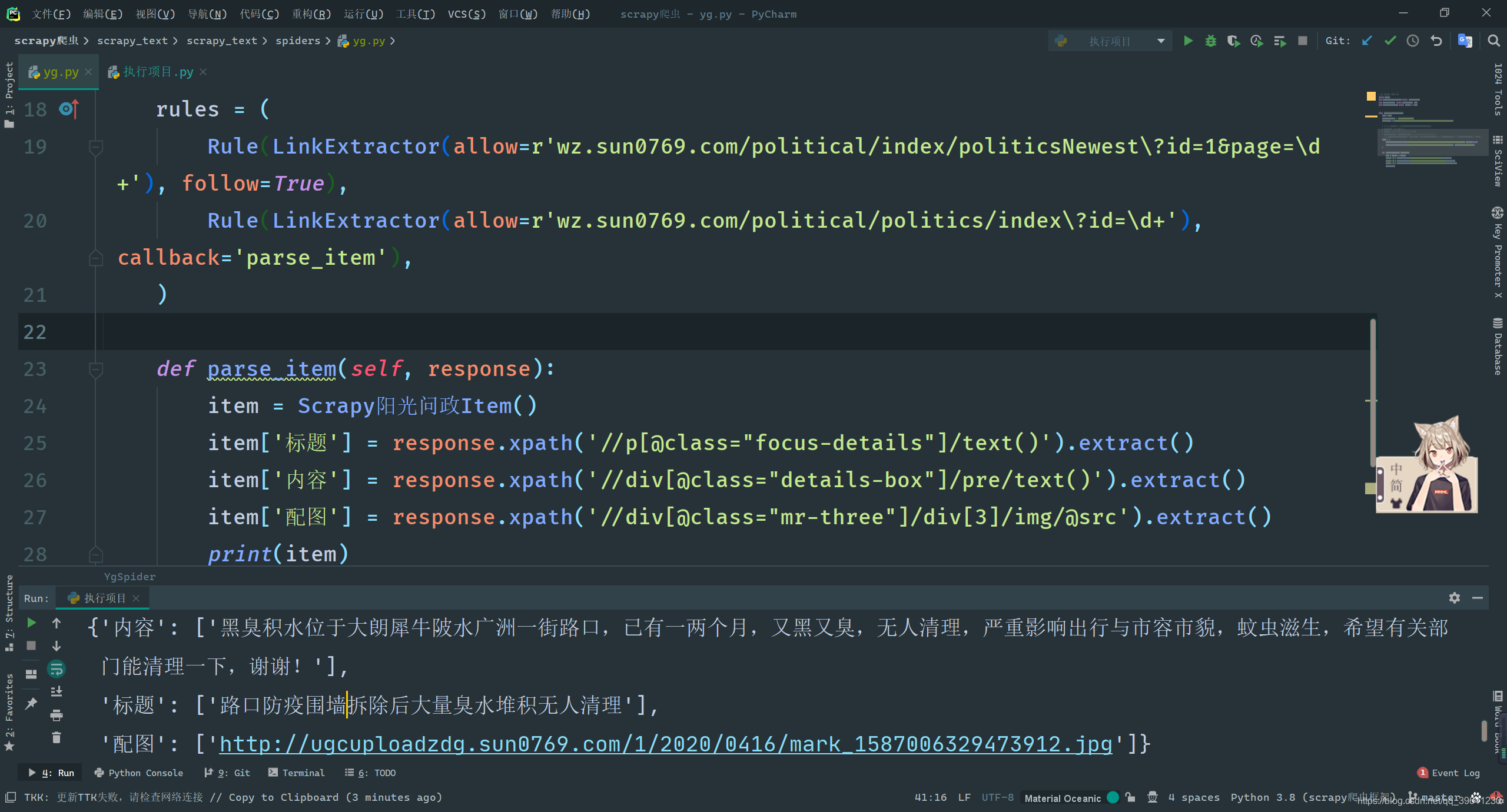
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_text.items import Scrapy阳光问政Item
class YgSpider(CrawlSpider):
name = 'yg'
allowed_domains = ['wz.sun0769.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']
rules = (
# 翻页链接提取(follow:用于重复提取,从提取的新页面中继续寻找符合当前要求的页面)
Rule(LinkExtractor(allow=r'wz.sun0769.com/political/index/politicsNewest\?id=1&page=\d+'), follow=True),
# 详情链接提取(callback:将提取到的详情页面传入parse_item方法进行处理)
Rule(LinkExtractor(allow=r'wz.sun0769.com/political/politics/index\?id=\d+'), callback='parse_item'),
)
def parse_item(self, response):
item = Scrapy阳光问政Item()
item['标题'] = response.xpath('//p[@class="focus-details"]/text()').extract()
item['内容'] = response.xpath('//div[@class="details-box"]/pre/text()').extract()
item['配图'] = response.xpath('//div[@class="mr-three"]/div[3]/img/@src').extract()
print(item)
See crawling the same content without using a link extractor
auto login
There are two methods for the conventional request to realize website login. One is to find the submission form for user login, simulate the user to submit for login, and the other is to carry the logged in cookie.
Both methods can be used by Scrapy, but in addition, scrapy can also automatically search for possible login boxes. After we enter the account password, we can automatically submit and log in. Let's use the steam (https://steamcommunity.com/) login page to demonstrate several login methods.
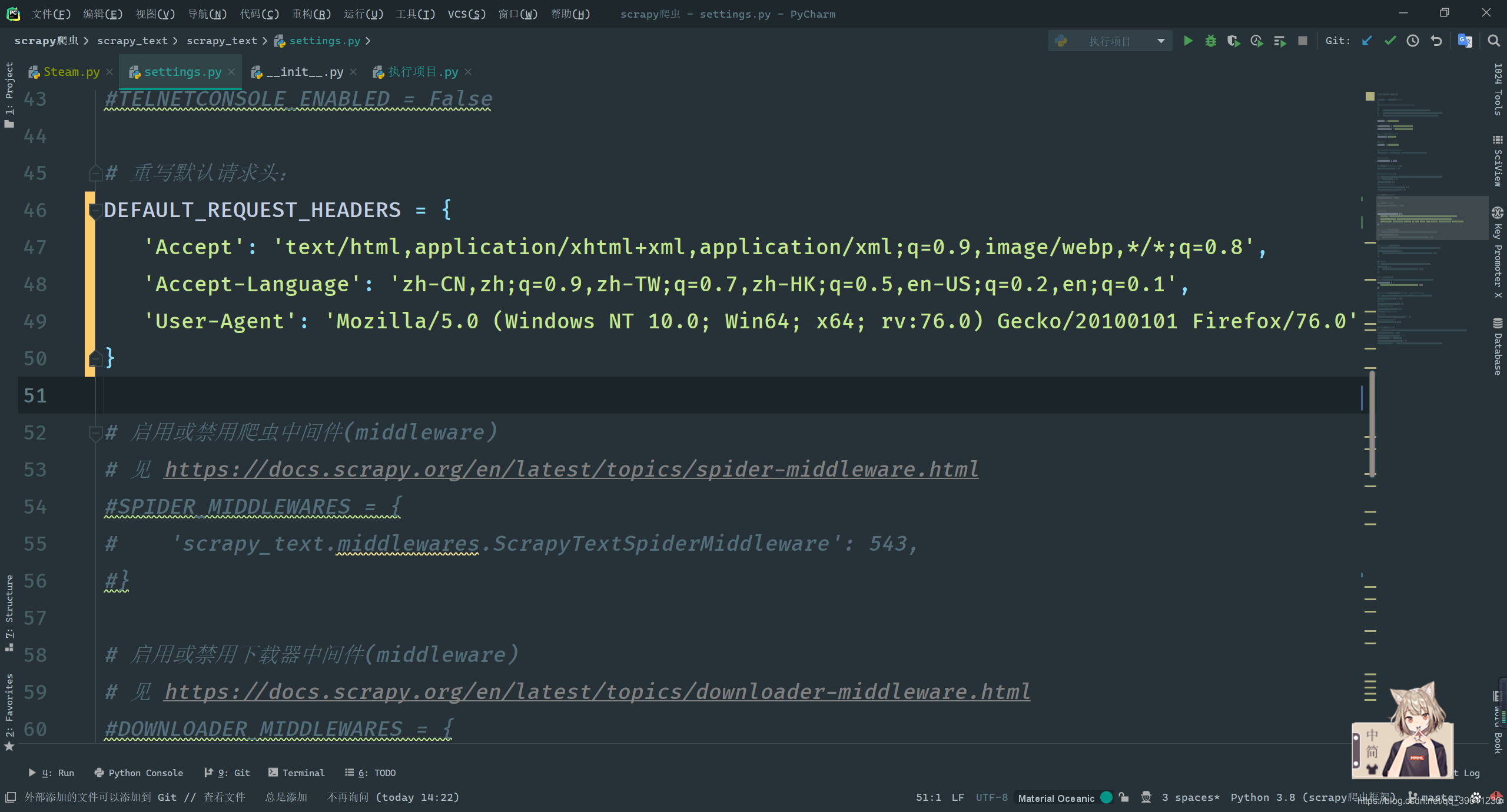
In case of an accident, let's change the request header first
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.2,en;q=0.1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:76.0) Gecko/20100101 Firefox/76.0'
}
The old way-log in with cookies and simulate submitting the login form
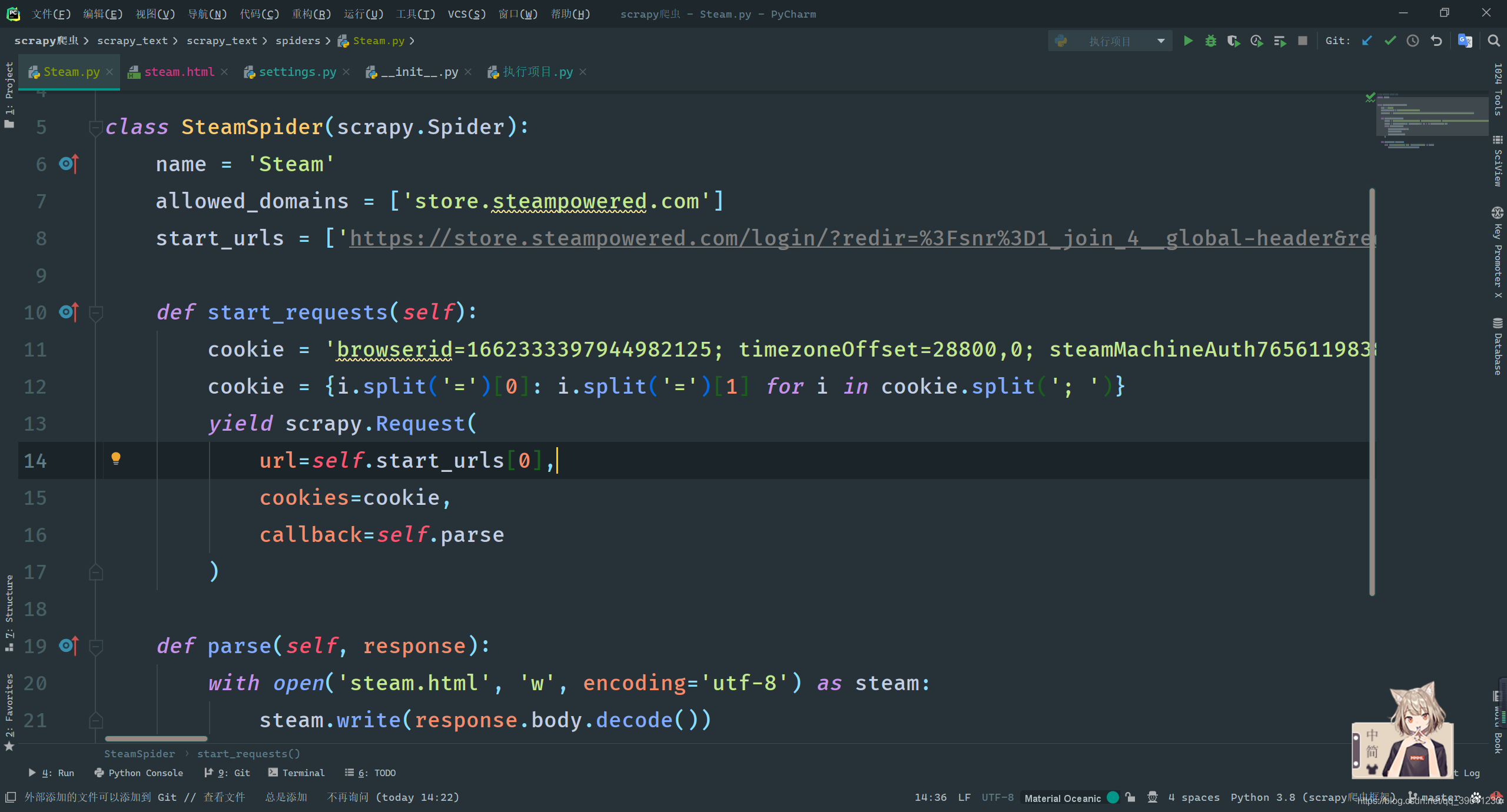
At present, we want to realize that when we initiate a request to the first url page, we bring a cookie to log in, but scrapy will automatically initiate a request to the first url, and this request calls a staet_request()method, which means that we only need to override this method Achieve login with cookies.
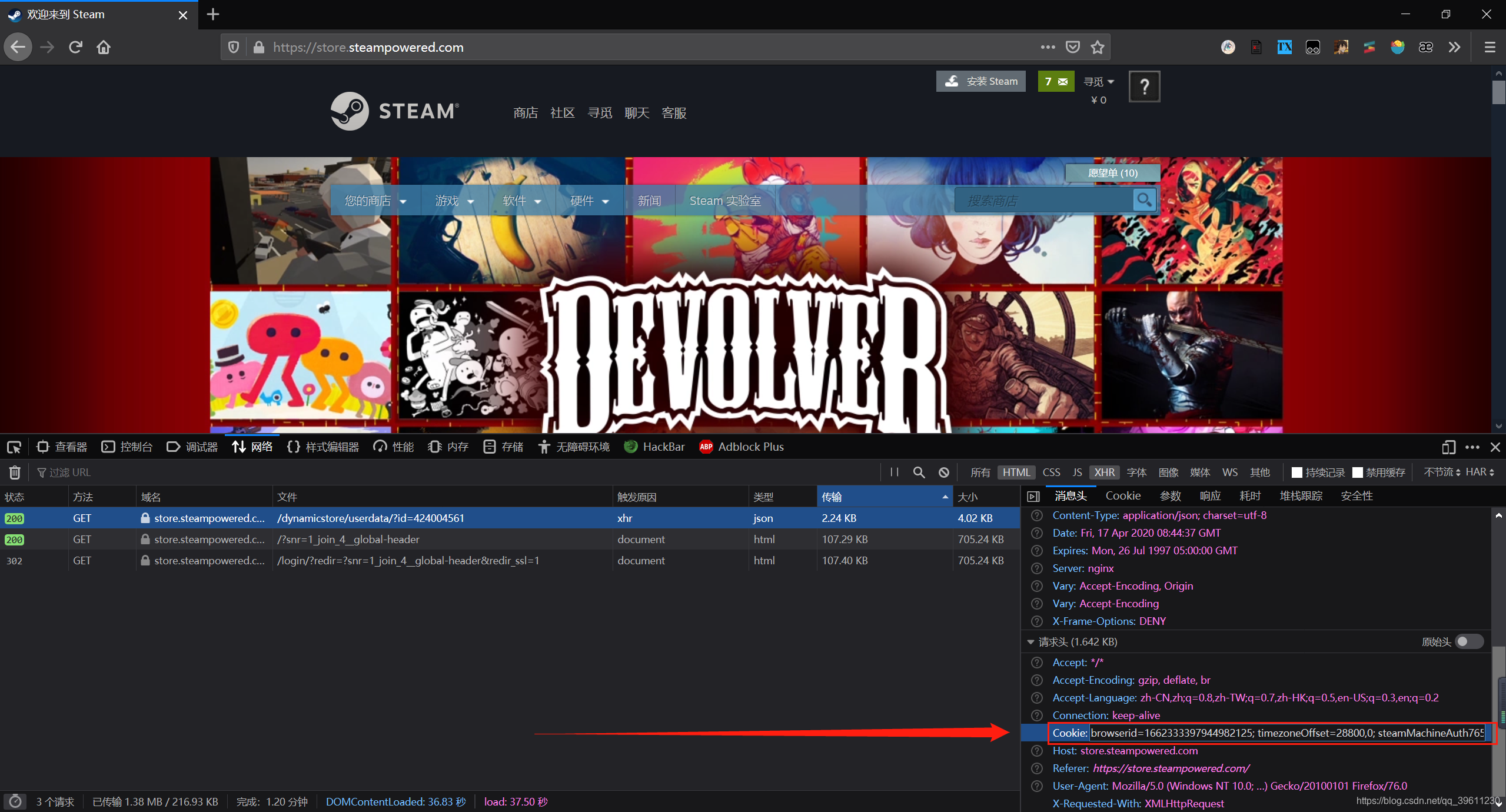
The cookie can be copied directly here, without any processing of the cookie = {i.split('=')[0]: i.split('=')[1] for i in cookie.split('; ')}following code, the cookie will be automatically converted into the required dictionary form here
# -*- coding: utf-8 -*-
import scrapy
class SteamSpider(scrapy.Spider):
name = 'Steam'
allowed_domains = ['store.steampowered.com']
start_urls = ['https://store.steampowered.com/login/?redir=%3Fsnr%3D1_join_4__global-header&redir_ssl=1']
def start_requests(self):
cookie = '把你的cookie复制到这里'
cookie = {i.split('=')[0]: i.split('=')[1] for i in cookie.split('; ')}
yield scrapy.Request(
url=self.start_urls[0],
cookies=cookie,
callback=self.parse
)
def parse(self, response):
with open('steam.html', 'w', encoding='utf-8') as steam:
steam.write(response.body.decode())
The idea of simulating the submission of the login form is to first find the from form and submit it according to the information. The following uses github to simulate. Through observation, we found that when submitting the form not only to submit the account password, but also need to submit some things such as time stamp and secret key.
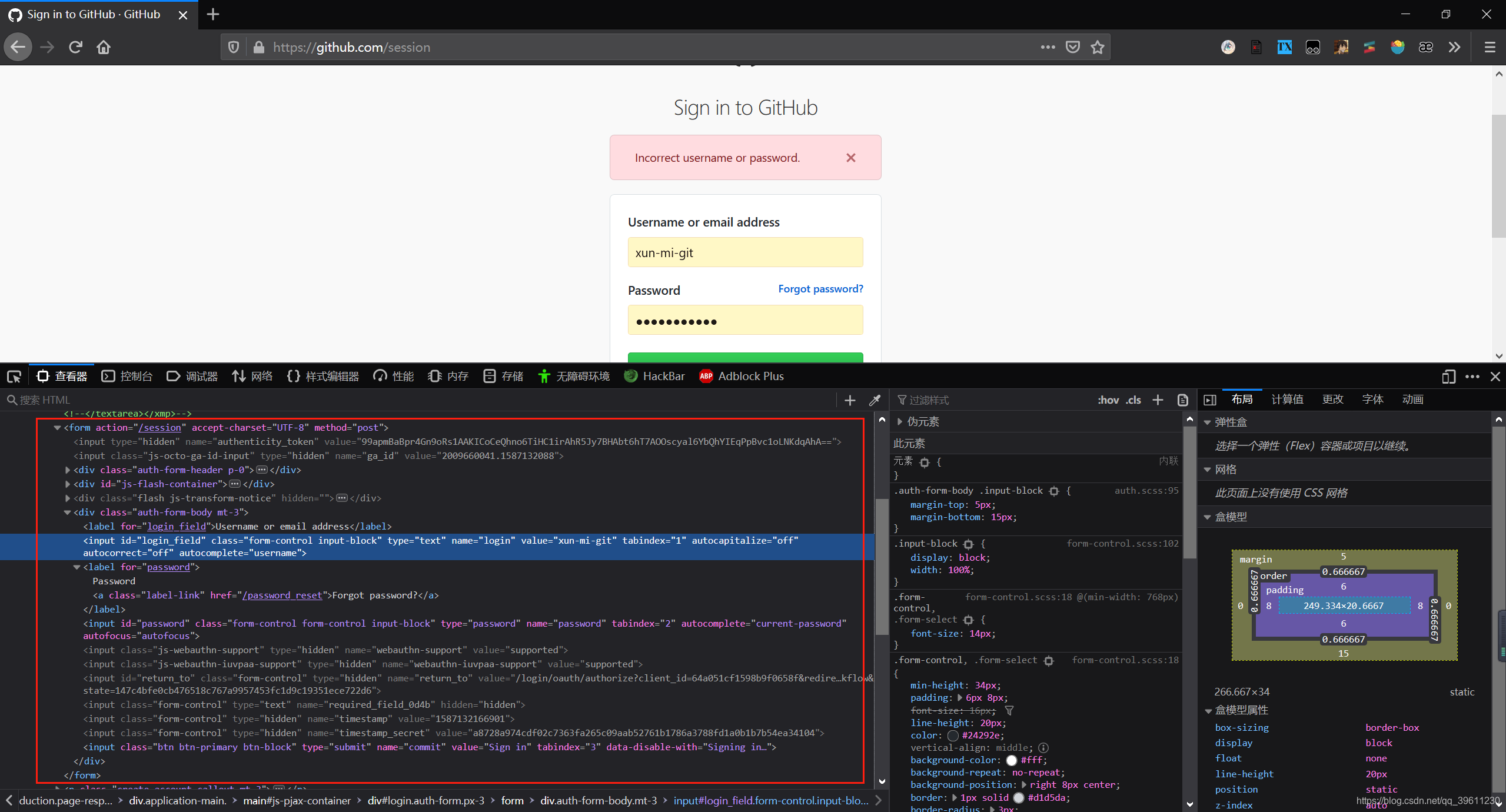
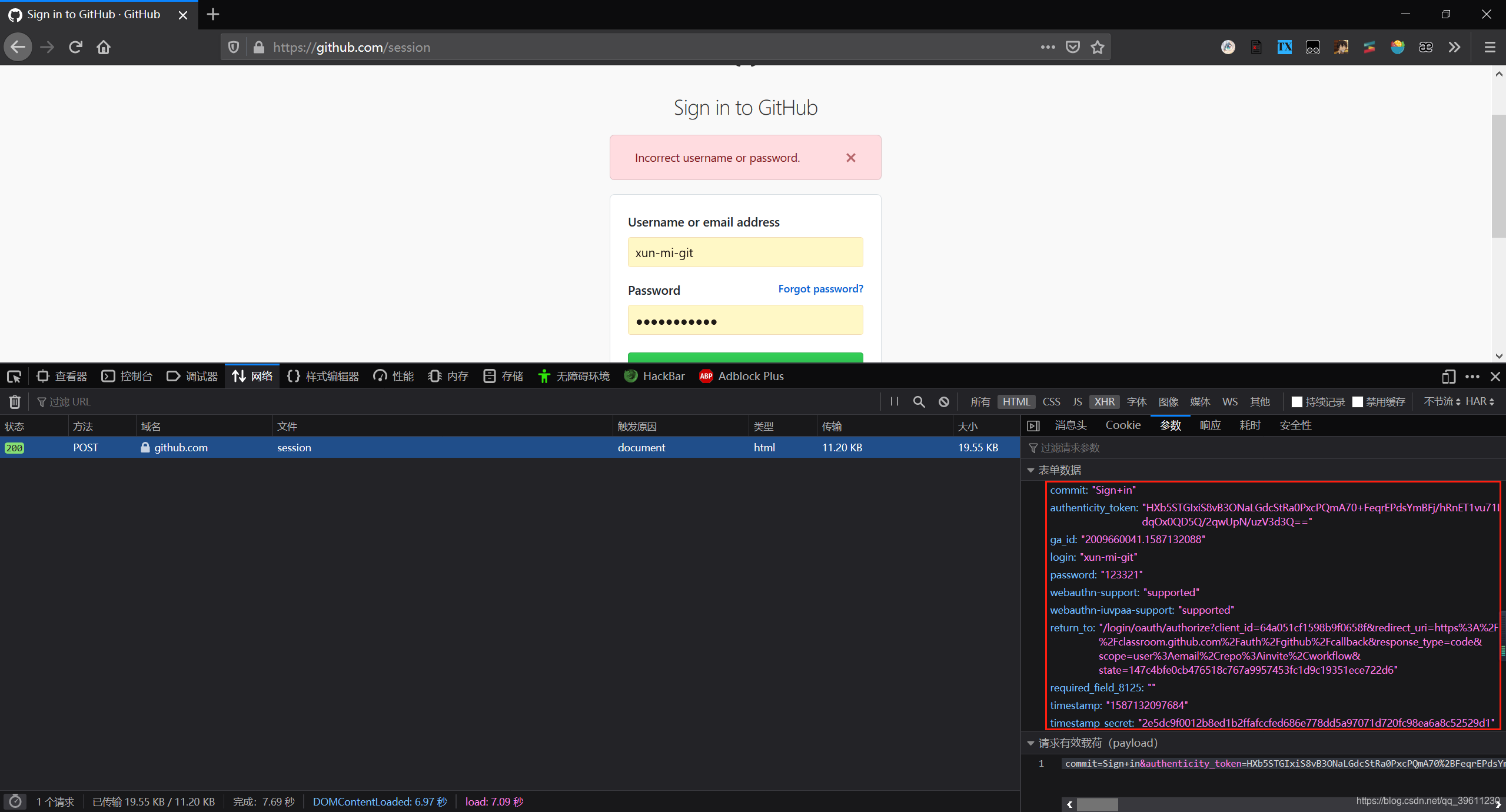
The method used to submit the post request is scrapy.FormRequest()as follows.
# -*- coding: utf-8 -*-
import scrapy
class GithubSpider(scrapy.Spider):
name = 'github'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
commit = 'Sign in'
authenticity_token = response.xpath('//input[@name="authenticity_token"]/@value').extract_first()
ga_id = response.xpath('//input[@name="ga_id"]/@value').extract_first()
login = ''
password = ''
timestamp = response.xpath('//input[@name="timestamp"]/@value').extract_first()
timestamp_secret = response.xpath('//input[@name="timestamp_secret"]/@value').extract_first()
post_data = {
'commit': commit,
'authenticity_token': authenticity_token,
# 'ga_id': ga_id,
'login': login,
'password': password,
'timestamp': timestamp,
'timestamp_secret': timestamp_secret,
'webauthn-support': 'supported',
'webauthn-iuvpaa-support': 'unsupported'
}
# print(post_data)
# 发送post请求
yield scrapy.FormRequest(
url='https://github.com/session',
formdata=post_data,
callback=self.after_login
)
def after_login(self, response):
# print(response)
with open('github.html', 'w', encoding='utf-8') as f:
f.write(response.text)
New method-automatic login
The advantage of automatic login is that scrapy will help us to automatically find the from form, and then automatically fill in what we need to fill in the content (account password) for other verification. We do not need to process to log in
. We need to use here The method isyield scrapy.FormRequest.from_response()
# -*- coding: utf-8 -*-
import scrapy
class GithubautoSpider(scrapy.Spider):
name = 'githubAuto'
allowed_domains = ['github.com']
start_urls = ['https://github.com/login']
def parse(self, response):
yield scrapy.FormRequest.from_response(
response=response,
formdata={"login": "", "password": ""},
callback=self.after_login
)
def after_login(self, response):
with open('github.html', 'w', encoding='utf-8') as f:
f.write(response.text)
.from_response()In addition to being able to log in automatically, he can also be used as a form submission method. For example, when searching, he can use .from_response()form submission. There are multiple forms on the page, you can use the formname, formid, formxpath and other attributes to identify the form
Picture (File) Downloader
The image downloader (Images Pipeline) and file downloader (Files Pipeline) are used in a similar way, but the individual method names are different. The following is only an example of the image downloader.
This time we use the Pacific as a test site, crawling a picture of a mobile phone brand that I prefer. It is
still the same. Let's try to download
it in the original way without using the downloader: although the amount of code in the crawler is not much, but We also need to save the picture in the pipeline
# -*- coding: utf-8 -*-
import scrapy
class PhoneSpider(scrapy.Spider):
name = 'phone'
allowed_domains = ['product.pconline.com.cn']
start_urls = ['https://product.pconline.com.cn/pdlib/1140887_picture_tag02.html']
def parse(self, response):
ul = response.xpath('//div[@id="area-pics"]/div/div/ul/li/a/img')
for li in ul:
item = {'图片': li.xpath('./@src').extract_first()}
item['图片'] = 'https:' + item['图片']
yield item
import os
from urllib import request
class Scrapy图片下载Pipeline(object):
def process_item(self, item, spider):
path = os.path.join(os.path.dirname(__file__), '图片')
name = item['图片'].split('/')[-1]
print(name, item['图片'])
request.urlretrieve(item['图片'], path + "/" + name)
return item
Use the image downloader Images Pipeline
If you use scrapy downloader, you can:
- Avoid re-downloading data that has been downloaded recently
- You can easily specify the file storage path
- You can convert the downloaded pictures into a universal format. Such as: png, jpg
- You can easily generate thumbnails
- Can easily detect the width and height of pictures to ensure that they meet the minimum limit
- Asynchronous download, very efficient
Steps to download files using images pipeline:
- Define an Item, and then define two properties in this item, namely image_urls and images. image_urls is a url link used to store the file to be downloaded, need to give a list

- When the file download is complete, the relevant information about the file download will be stored in the images attribute of the item. Such as download path, downloaded URL and image verification code, etc.
- Configure IMAGES_STORE in the configuration file settings.py, this configuration is used to set the file download path
- Start the pipeline: set 'scrapy.pipelines.images.ImagesPipeline' in ITEM_PIPELINES: 1After
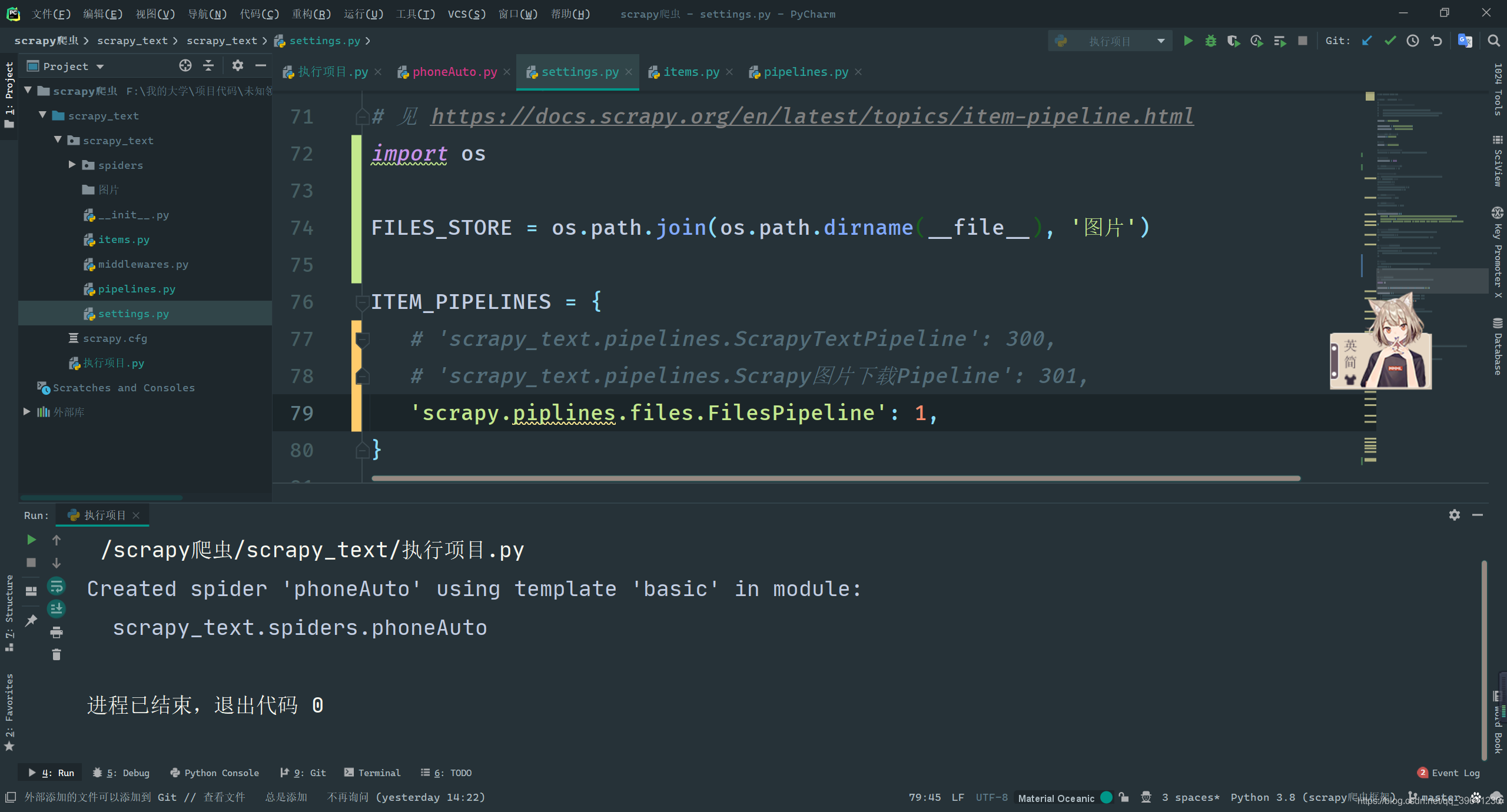
completing the above configuration, execute the following code to achieve image crawling
# -*- coding: utf-8 -*-
import scrapy
from scrapy_text.items import Scrapy图片下载Item
class PhoneautoSpider(scrapy.Spider):
name = 'phoneAuto'
allowed_domains = ['product.pconline.com.cn']
start_urls = ['https://product.pconline.com.cn/pdlib/1140887_picture_tag02.html']
def parse(self, response):
ul = response.xpath('//div[@id="area-pics"]/div/div/ul/li/a/img')
for li in ul:
item = Scrapy图片下载Item()
item['image_urls'] = li.xpath('./@src').extract_first()
item['image_urls'] = ['https:' + item['image_urls']]
yield item
The source code of the image downloader is from scrapy.pipelines.images import ImagesPipelinelocated here, if you are interested you can view it yourself
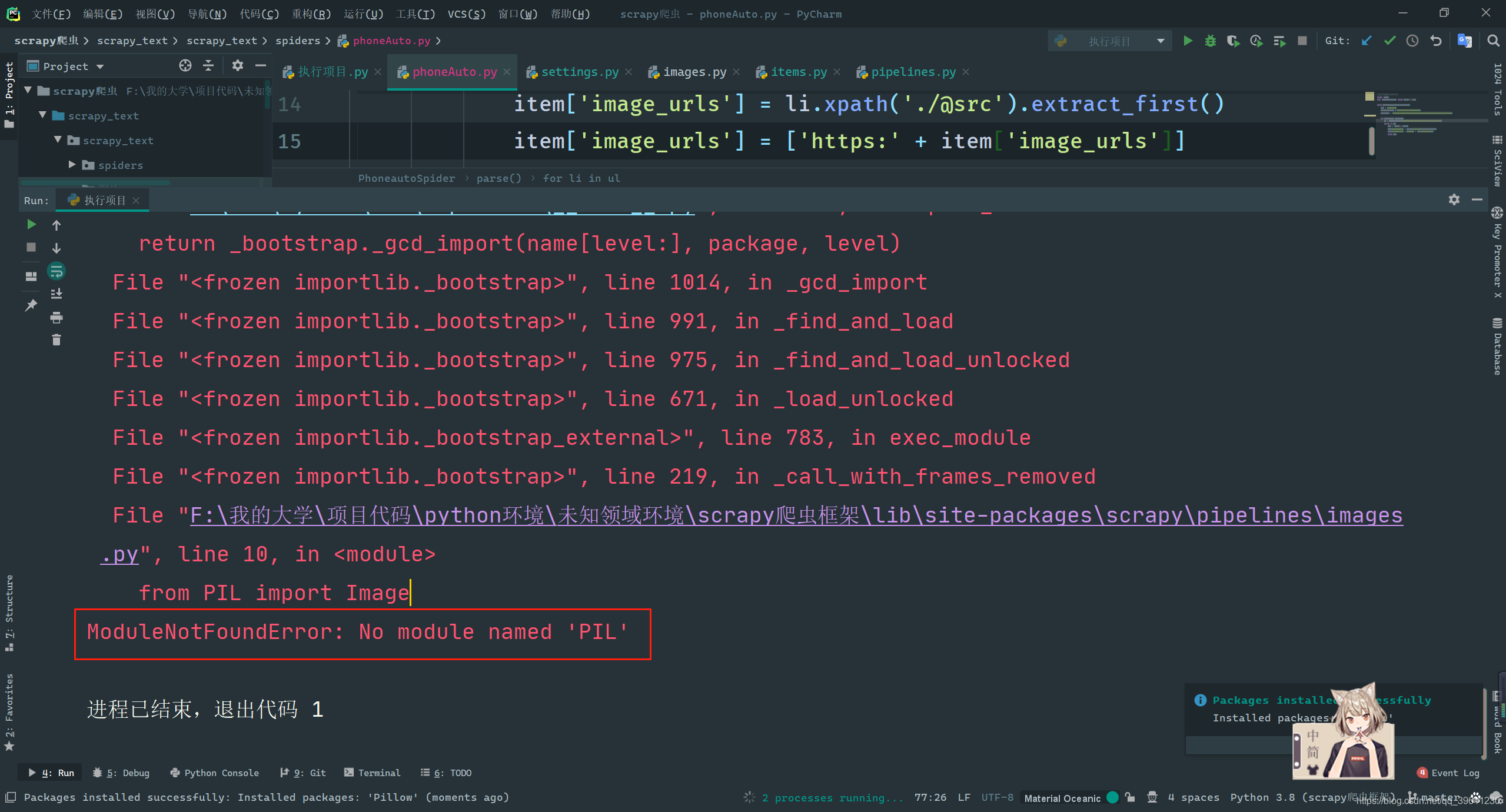
The image downloader prompts ModuleNotFoundError: No module named 'PIL'
Although the error is reported as the lack of the PIL library, but because this library does not have a Python3 version, it has been deprecated, so we need to install the Python version of this library Pillow.
pip install pillow
Use Files Downloader
- Define an Item, and then define two attributes in this item, namely file_urls and files. files_urls is a url link used to store files that need to be downloaded, you need to give a list
- When the file download is complete, the file download related information will be stored in the files attribute of the item. Such as download path, downloaded URL and file verification code, etc.
- Configure FILES_STORE in the configuration file settings.py, this configuration is used to set the file download path
- Start the pipeline: set 'scrapy.piplines.files.FilesPipeline' in ITEM_PIPELINES: 1
The source code is located from scrapy.pipelines.files import FilesPipeline, and the use is similar to the above picture downloader, so it will not be demonstrated here.
