Introduction
Over the past two years, most of the time, I almost have to work at a depth of field of study. It was a very good experience, I participated in this intermediate image and video data multiple projects related.
Before that, I was marginalized, I avoided the deep learning concepts such as object detection and face recognition. Only in-depth study start until the end of 2017. During this time, I encountered a variety of problems. I want to talk about four of the most common problems that most depth study and practice and enthusiasts will encounter in their journey.

If you are involved in deep learning project before, you can quickly understand these barriers. The good news is that they do not overcome so difficult as you think!
In this article, we will adopt a very pragmatic approach. First, we will create four common problems I mentioned above. Then, we will direct Dive Into Python code learning key skills and techniques to combat these challenges and overcome these challenges. There are many things that need to open, let's get started!
table of Contents
- A common problem of deep learning model
- Overview of vehicle classification Case Study
- Understand each puzzle and how to overcome challenges in order to improve the performance of deep learning model
- Case Study: Improving the performance of our vehicle classification model
A common problem of deep learning model
Depth learning model is usually manifested in the most data are very good. In terms of image data, depth learning model, especially convolutional neural network (CNN), better than almost all other models.
My usual approach is to use CNN model in the face of the image related items (such as image classification project).
This method works well, but in some cases, CNN or other deep learning model can not be performed. I have met a few times. My good data architecture model also correctly defined, and loss of function optimization also set correctly, but my model did not meet my expectations.
This is a common problem faced by most of us in the use of deep learning model.
As mentioned above, I will address these four problems:
- Lack of data can be used for training
- Overfitting
- Underfitting
- Long training time
Before depth study and understanding of these problems, let's take a quick look at our will to solve the case studies in this article.
Overview of vehicle classification Case Study
I have been writing this article is a part of PyTorch for beginners series. You can view the first three articles in here (where we quote from some of the content):
- PyTorch Getting Started
- In PyTorch established image classification model uses convolution neural network
- Use PyTorc migration study
We will continue to read the article to see the case study. The purpose here is to image vehicles classified as urgent or non-urgent.
First, let us quickly build a CNN model, and use it as a reference. We will also try to improve the performance of this model. These steps are very simple, in the previous article, we have seen several times.
Therefore, I would not be here every step of depth. Instead, we will focus on the code, you can always check in more detail in my previous article linked above. You can get a data set from here : https: //drive.google.com/file/d/1EbVifjP0FQkyB1axb7KQ26yPtWmneApJ/view.
This is the code to build a complete model of CNN for our vehicle classification project.
Import library
# 导入库
import pandas as pd
import numpy as np
from tqdm import tqdm
# 用于读取和显示图像
from skimage.io import imread
from skimage.transform import resize
import matplotlib.pyplot as plt
%matplotlib inline
# 用于创建验证集
from sklearn.model_selection import train_test_split
# 用于评估模型
from sklearn.metrics import accuracy_score
# PyTorch库和模块
import torch
from torch.autograd import Variable
from torch.nn import Linear, ReLU, CrossEntropyLoss, Sequential, Conv2d, MaxPool2d, Module, Softmax, BatchNorm2d, Dropout
from torch.optim import Adam, SGD
# 预训练模型
from torchvision import modelsLoad data sets
# 加载数据集
train = pd.read_csv('emergency_train.csv')
# 加载训练图片
train_img = []
for img_name in tqdm(train['image_names']):
# 定义图像路径
image_path = '../Hack Session/images/' img_name
# 读取图片
img = imread(image_path)
# 标准化像素值
img = img/255
img = resize(img, output_shape=(224,224,3), mode='constant', anti_aliasing=True)
# 转换为浮点数
img = img.astype('float32')
# 添加图片到列表
train_img.append(img)
# 转换为numpy数组
train_x = np.array(train_img)
train_x.shape
Create a training and validation set
# 定义目标
train_y = train['emergency_or_not'].values
# 创建验证集
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0.1, random_state = 13, stratify=train_y)
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)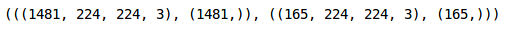
The torch format image is converted into
# 转换训练图片到torch格式
train_x = train_x.reshape(1481, 3, 224, 224)
train_x = torch.from_numpy(train_x)
# 转换目标到torch格式
train_y = train_y.astype(int)
train_y = torch.from_numpy(train_y)
# 转换验证图像到torch格式
val_x = val_x.reshape(165, 3, 224, 224)
val_x = torch.from_numpy(val_x)
# 转换目标到torch格式
val_y = val_y.astype(int)
val_y = torch.from_numpy(val_y)Defined architecture model
torch.manual_seed(0)
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# 定义2D卷积层
Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# 另一个2D卷积层
Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2)
)
self.linear_layers = Sequential(
Linear(32 * 56 * 56, 2)
)
# 前项传播
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return xThe definition of the model parameters
# 定义模型
model = Net()
# 定义优化器
optimizer = Adam(model.parameters(), lr=0.0001)
# 定义损失函数
criterion = CrossEntropyLoss()
# 检查GPU是否可用
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
print(model)
Trainer
torch.manual_seed(0)
# 模型batch大小
batch_size = 128
# epoch数
n_epochs = 25
for epoch in range(1, n_epochs 1):
# 保持记录训练与验证集损失
train_loss = 0.0
permutation = torch.randperm(train_x.size()[0])
training_loss = []
for i in tqdm(range(0,train_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = train_x[indices], train_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs,batch_y)
training_loss.append(loss.item())
loss.backward()
optimizer.step()
training_loss = np.average(training_loss)
print('epoch: \t', epoch, '\t training loss: \t', training_loss)
Forecast on training set
# 训练集预测
prediction = []
target = []
permutation = torch.randperm(train_x.size()[0])
for i in tqdm(range(0,train_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = train_x[indices], train_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction.append(predictions)
target.append(batch_y)
# 训练集精度
accuracy = []
for i in range(len(prediction)):
accuracy.append(accuracy_score(target[i],prediction[i]))
print('training accuracy: \t', np.average(accuracy))
Verify the prediction set
# 验证集预测
prediction_val = []
target_val = []
permutation = torch.randperm(val_x.size()[0])
for i in tqdm(range(0,val_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = val_x[indices], val_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction_val.append(predictions)
target_val.append(batch_y)
# 验证集精度
accuracy_val = []
for i in range(len(prediction_val)):
accuracy_val.append(accuracy_score(target_val[i],prediction_val[i]))
print('validation accuracy: \t', np.average(accuracy_val))
This is our CNN model. Training accuracy of about 88%, verify the accuracy of nearly 70%.
We will strive to improve the performance of this model. But before that, let's take a moment to look at the problems, these problems may be the reason for this low performance.
Depth study of the problem
1 depth study of the problem: the lack of available data to train our model
Depth learning model usually requires a lot of training data. In general, the more data, the better the performance of the model. The problem is the lack of data, our deep learning model may not learning mode or function from the data, thus providing a good performance on data that it may not be in the unseen.
If you look at the automobile classification of the case studies, we only have about 1650 pictures, so this model is the poor performance on the validation set. When using computer vision and depth of learning model, fewer data problems are very common.
As you can imagine, manually collected data is a tedious and time-consuming task. Therefore, we can use data enhancement technique instead of spending a few days to collect data.
Data enhancement is, without actually collecting new data to generate new data or add data to train the model of the process.
The image data of plural kinds of data enhancement techniques, enhancement techniques are common rotation, cropping, flips.
这是一个非常好的主题,因此我决定写一篇完整的文章。我的计划是在下一篇文章中讨论这些技术及其在PyTorch中的实现。
我相信你听说过过拟合。这是数据科学家刚接触机器学习时最常见的难题(和错误)之一。但这个问题实际上超越了该领域,它也适用于深度学习。
当一个模型在训练集上执行得非常好,但是在验证集(或不可见的数据)上性能下降时,就会被认为是过拟合。
例如,假设我们有一个训练集和一个验证集。我们使用训练数据来训练模型,并检查它在训练集和验证集上的性能(评估指标是准确性)。训练的准确率是95%而验证集的准确率是62%。听起来熟悉吗?
由于验证精度远低于训练精度,因此可以推断模型存在过拟合问题。下面的例子会让你更好地理解什么是过拟合:

上图中蓝色标记的部分是过拟合模型,因为训练误差非常小并且测试误差非常高。过拟合的原因是该模型甚至从训练数据中学习了不必要的信息,因此它在训练集上的表现非常好。
但是,当引入新数据时,它将无法执行。我们可以向模型的架构中引入Dropout,以解决过拟合的问题。
使用Dropout,我们随机关闭神经网络的某些神经元。假设我们在最初有20个神经元的图层上添加了概率为0.5的Dropout层,因此,这20个神经元中的10个将被抑制,我们最终得到了一个不太复杂的体系结构。
因此,该模型将不会学习过于复杂的模式,可以避免过拟合。现在让我们在架构中添加一个Dropout层,并检查其性能。
模型架构
torch.manual_seed(0)
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# 定义2D卷积层
Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# Dropout层
Dropout(),
#另一个2D卷积层
Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# Dropout层
Dropout(),
)
self.linear_layers = Sequential(
Linear(32 * 56 * 56, 2)
)
# 前向传播
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x在这里,我在每个卷积块中添加了一个Dropout层。默认值为0.5,这意味着一半神经元将被随机关闭。这是一个超参数,你可以选择0到1之间的任何值。
接下来,我们将定义模型的参数,例如损失函数,优化器和学习率。
模型参数
# 定义模型
model = Net()
# 定义优化器
optimizer = Adam(model.parameters(), lr=0.0001)
# 定义损失函数
criterion = CrossEntropyLoss()
# 检查GPU是否可用
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
print(model)
在这里,你可以看到Dropout中的默认值为0.5。最后,让我们在添加Dropout层之后训练模型:
训练模型
torch.manual_seed(0)
# 模型batch大小
batch_size = 128
# epoch数
n_epochs = 25
for epoch in range(1, n_epochs 1):
# 保持记录训练与验证集损失
train_loss = 0.0
permutation = torch.randperm(train_x.size()[0])
training_loss = []
for i in tqdm(range(0,train_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = train_x[indices], train_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs,batch_y)
training_loss.append(loss.item())
loss.backward()
optimizer.step()
training_loss = np.average(training_loss)
print('epoch: \t', epoch, '\t training loss: \t', training_loss)
现在,让我们使用此训练模型检查训练和验证的准确性。
检查模型性能
#
prediction = []
target = []
permutation = torch.randperm(train_x.size()[0])
for i in tqdm(range(0,train_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = train_x[indices], train_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction.append(predictions)
target.append(batch_y)
# 训练集精度
accuracy = []
for i in range(len(prediction)):
accuracy.append(accuracy_score(target[i],prediction[i]))
print('training accuracy: \t', np.average(accuracy))
同样,让我们检查验证集准确性:
# 验证集预测
prediction_val = []
target_val = []
permutation = torch.randperm(val_x.size()[0])
for i in tqdm(range(0,val_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = val_x[indices], val_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction_val.append(predictions)
target_val.append(batch_y)
# 验证集精度
accuracy_val = []
for i in range(len(prediction_val)):
accuracy_val.append(accuracy_score(target_val[i],prediction_val[i]))
print('validation accuracy: \t', np.average(accuracy_val))
让我们将其与以前的结果进行比较:
| 训练集准确性 |
验证集准确性 |
|
|---|---|---|
| 没有Dropout |
87.80 | 69.72 |
| 有Dropout |
73.56 | 70.29 |
上表表示没有Dropout和有Dropout的准确性。如果你观察没有遗漏的模型的训练和验证准确性,它们是不同步的。训练精度过高,验证精度较低。因此,这可能是一个过拟合的例子。
当我们引入Dropout时,训练和验证集的准确性是同步的。因此,如果你的模型过拟合,你可以尝试添加Dropout层,以减少模型的复杂性。
要添加的Dropout数量是一个超参数,你可以使用该值进行操作。现在让我们看看另一个难题。
深度学习难题3:模型欠拟合
深度学习模型也可能欠拟合,听起来似乎不太可能。
欠拟合是指模型无法从训练数据本身中学习模式,因此训练集上的性能较低。
这可能是由于多种原因造成的,例如没有足够的数据来训练,架构太简单,模型的训练次数较少等。
为了克服欠拟合的问题,你可以尝试以下解决方案:
- 增加训练数据
- 制作一个复杂的模型
- 增加训练的epoch
对于我们的问题,欠拟合不是问题,因此,我们将继续研究提高深度学习模型性能的下一种方法。
深度学习难题4:训练时间过长
有些情况下,你可能会发现你的神经网络需要花很多时间来收敛。这背后的主要原因是输入到神经网络层的分布发生了变化。
在训练过程中,神经网络各层的权值发生变化,激活也随之变化。现在,这些激活是下一层的输入,因此每一次连续的迭代都会改变分布。
由于这种分布的变化,每一层都必须适应不断变化的输入—这就是为什么训练时间增加的原因。
为了克服这一问题,我们可以应用批处理标准化(batch normalization),其中我们正常化的激活隐藏层,并试图作出相同的分布。
现在让我们向架构中添加batchnorm层,并检查它在车辆分类问题上的表现:
torch.manual_seed(0)
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# 定义2D卷积层
Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
# BN层
BatchNorm2d(16),
MaxPool2d(kernel_size=2, stride=2),
#另一个2D卷积层
Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
# BN层
BatchNorm2d(32),
MaxPool2d(kernel_size=2, stride=2),
)
self.linear_layers = Sequential(
Linear(32 * 56 * 56, 2)
)
# 前向传播
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x定义模型参数
# 定义模型
model = Net()
# 定义优化器
optimizer = Adam(model.parameters(), lr=0.00005)
# 定义损失函数
criterion = CrossEntropyLoss()
# 检查GPU是否可用
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
print(model)
让我们训练模型
torch.manual_seed(0)
# 模型batch大小
batch_size = 128
# epoch数
n_epochs = 5
for epoch in range(1, n_epochs 1):
# 保持记录训练与验证集损失
train_loss = 0.0
permutation = torch.randperm(train_x.size()[0])
training_loss = []
for i in tqdm(range(0,train_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = train_x[indices], train_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs,batch_y)
training_loss.append(loss.item())
loss.backward()
optimizer.step()
training_loss = np.average(training_loss)
print('epoch: \t', epoch, '\t training loss: \t', training_loss)
显然,该模型能够很快学习。在第5个epoch时,我们的训练损失为0.3386,而当我们不使用批量标准化时要25个epoch之后,我们的训练损失才为0.3851。
因此,引入批标准化无疑减少了训练时间。让我们检查训练和验证集的性能:
prediction = []
target = []
permutation = torch.randperm(train_x.size()[0])
for i in tqdm(range(0,train_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = train_x[indices], train_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction.append(predictions)
target.append(batch_y)
# 训练集精度
accuracy = []
for i in range(len(prediction)):
accuracy.append(accuracy_score(target[i],prediction[i]))
print('training accuracy: \t', np.average(accuracy))
# 验证集预测
prediction_val = []
target_val = []
permutation = torch.randperm(val_x.size()[0])
for i in tqdm(range(0,val_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = val_x[indices], val_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction_val.append(predictions)
target_val.append(batch_y)
# 验证集精度
accuracy_val = []
for i in range(len(prediction_val)):
accuracy_val.append(accuracy_score(target_val[i],prediction_val[i]))
print('validation accuracy: \t', np.average(accuracy_val))
添加批量标准化可以减少训练时间,但是这里存在一个问题。你能弄清楚它是什么吗?该模型现在过拟合,因为我们在训练上的准确性为91%,在验证集上的准确性为63%。记住,我们没有在最新模型中添加Dropout层。
这些是我们可以用来改善深度学习模型性能的一些技巧。现在,让我们结合到目前为止所学的所有技术。
案例研究:提高车辆分类模型的性能
我们已经看到Dropout和批标准化如何帮助减少过拟合并加快训练过程。现在是时候将所有这些技术结合在一起并建立模型了。
torch.manual_seed(0)
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# 定义2D卷积层
Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
# BN层
BatchNorm2d(16),
MaxPool2d(kernel_size=2, stride=2),
# 添加dropout
Dropout(),
#另一个2D卷积层
Conv2d(16, 32, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
# BN层
BatchNorm2d(32),
MaxPool2d(kernel_size=2, stride=2),
# 添加dropout
Dropout(),
)
self.linear_layers = Sequential(
Linear(32 * 56 * 56, 2)
)
# 前向传播
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x现在,我们将定义模型的参数:
# 定义模型
model = Net()
# 定义优化器
optimizer = Adam(model.parameters(), lr=0.00025)
# 定义损失函数
criterion = CrossEntropyLoss()
# 检查GPU是否可用
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
print(model)
最后,让我们训练模型:
torch.manual_seed(0)
# 模型batch大小
batch_size = 128
# epoch数
n_epochs = 10
for epoch in range(1, n_epochs 1):
# 保持记录训练与验证集损失
train_loss = 0.0
permutation = torch.randperm(train_x.size()[0])
training_loss = []
for i in tqdm(range(0,train_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = train_x[indices], train_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs,batch_y)
training_loss.append(loss.item())
loss.backward()
optimizer.step()
training_loss = np.average(training_loss)
print('epoch: \t', epoch, '\t training loss: \t', training_loss)
接下来,让我们检查模型的性能:
prediction = []
target = []
permutation = torch.randperm(train_x.size()[0])
for i in tqdm(range(0,train_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = train_x[indices], train_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction.append(predictions)
target.append(batch_y)
# 训练集精度
accuracy = []
for i in range(len(prediction)):
accuracy.append(accuracy_score(target[i],prediction[i]))
print('training accuracy: \t', np.average(accuracy))
# 验证集预测
prediction_val = []
target_val = []
permutation = torch.randperm(val_x.size()[0])
for i in tqdm(range(0,val_x.size()[0], batch_size)):
indices = permutation[i:i batch_size]
batch_x, batch_y = val_x[indices], val_y[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction_val.append(predictions)
target_val.append(batch_y)
# 验证集精度
accuracy_val = []
for i in range(len(prediction_val)):
accuracy_val.append(accuracy_score(target_val[i],prediction_val[i]))
print('validation accuracy: \t', np.average(accuracy_val))
验证准确性明显提高到73%。太棒了!
结尾
在这篇文章中,我们研究了在使用深度学习模型(如CNNs)时可能面临的不同难题。我们还学习了所有这些难题的解决方案,最后,我们使用这些解决方案建立了一个模型。
在我们将这些技术添加到模型之后,模型在验证集上的准确性得到了提高。总有改进的空间,以下是一些你可以尝试的方法:
- 调整Dropout率
- 增加或减少卷积层的数量
- 增加或减少Dense层的数量
- 调整隐藏层中的神经元数量,等等。
欢迎关注磐创博客资源汇总站:http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:http://pytorch.panchuang.net/
