Watercress Top250 URL previously crawling to IMDb simple visualization: CSV format data list saved as

Import data ready
#!-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
import re
from numpy import rank
from builtins import map
from datashape.coretypes import Map
#http://www.jianshu.com/p/0a76c94e9db7 参考了简书上的饼状图教程
#切换工作目录,IPython运行%pylab
Movie=pd.read_csv('./doubanmovietop.csv') #数据读取
Check the header
Movie.head()
| Unnamed: 0 | title | info | rating_num | comment_num | daoyan | date | guojia | juqing | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | The Shawshank Redemption | People want freedom. | 9.7 | 1682392 | Director: Frank Darabont Frank Darabont Starring: Tim Robbins Tim Robb ... | 1994 | United States | Crime drama |
| 1 | 2 | Farewell My Concubine | Absolute beauty. | 9.6 | 1244650 | Director: Kaige Chen Kaige Chen Cast: Leslie Cheung, Leslie Cheung / Zhang Fengyi ... | 1993 | Mainland China Hong Kong, China | Homosexual love story |
| 2 | 3 | Forrest Gump | An American modern history. | 9.5 | 1301770 | Director: Robert Zemeckis Robert Zemeckis Starring: Tom Hanks Tom Han ... | 1994 | United States | Love story |
| 3 | 4 | The killer is not too cold | Undead and Lolita story have to say. | 9.4 | 1495321 | Director: Luc Besson Luc Besson Starring: Jean Reno Jean Reno / Natalie wave ... | 1994 | France | Action crime drama |
| 4 | 5 | beautiful life | The most beautiful lies. | 9.5 | 760464 | Director: Roberto Benigni is Roberto Benigni Starring: Roberto Bernini Roberto ... | 1997 | Italy | Drama Comedy Romance War |
IMDb Top250  score distribution pie chart Code:
score distribution pie chart Code:
#Rating pie
Rating=Movie['rating_num']
bins=[8,8.5,9,9.5,10] #分区(0,8],(8,8.5]....
rat_cut=pd.cut(Rating,bins=bins)
rat_class=rat_cut.value_counts() #统计区间个数
rat_pct=rat_class/rat_class.sum()*100 #计算百分比
rat_arr_pct=np.array(rat_pct)#将series格式转成array,为了避免pie中出现name
f1=plt.figure(figsize=(9,9))
plt.title('DoubanMovieTop250\nRatingDistributin(0~10)')
plt.pie(rat_arr_pct,labels=rat_pct.index,colors=['r','g','b','c'],autopct='%.2f%%',startangle=75,explode=[0.05]*4) #autopct属性显示百分比的值
plt.savefig('MovieTop250.RatingDistributin(0~10).png')
f1.show()
#explode:将某部分爆炸出来, 使用括号,将第一块分割出来,数值的大小是分割出来的与其他两块的间隙
#labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置
#autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数
#shadow,饼是否有阴影
#startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看
#pctdistance,百分比的text离圆心的距离
#patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本
Film produced in the distribution of the pie: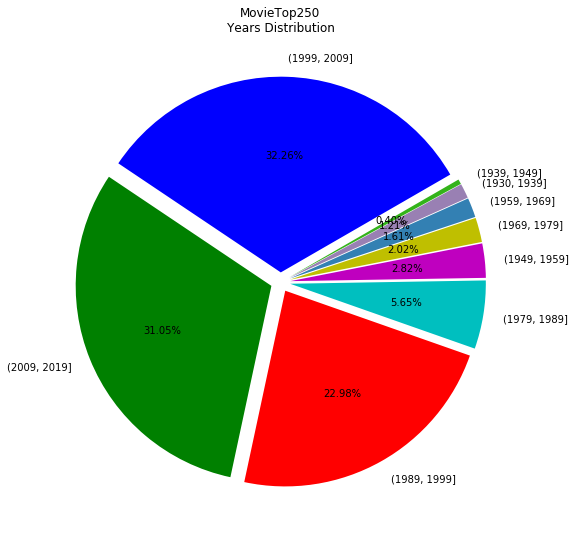
#year pie
year=Movie['date']
for i in year.index:
if len(year[i])>4:
year.drop(i,inplace=True) # year.drop(i,inplace=True) 去除多个年代的特例,inplace重要,修改改变原值
year=year.astype(int)
bins=np.linspace(min(year)-1,max(year)+1,10).astype(int) #产生区间,bins一般为(,]的,所以+1
year_cut=pd.cut(year,bins=bins)
year_class=year_cut.value_counts()
year_pct=year_class/year_class.sum()*100
year_arr_pct=np.array(year_pct)
color=['b', 'g', 'r', 'c', 'm', 'y', (0.2,0.5,0.7), (0.6,0.5,0.7),(0.2,0.7,0.1)] #RGB 0-1之间的tuple
f2=plt.figure(figsize=(9,9))
patches,out_text,in_text=plt.pie(year_arr_pct,labels=year_pct.index,colors=color,autopct='%.2f%%',explode=[0.05]*9,startangle=30)
plt.title('MovieTop250\nYears Distribution')
f2.show()
# plt.savefig('MovieTop250_YearsDistribution.png')
IMDb Top250, the film ranked number Evaluation & movie ratings scatter plot:
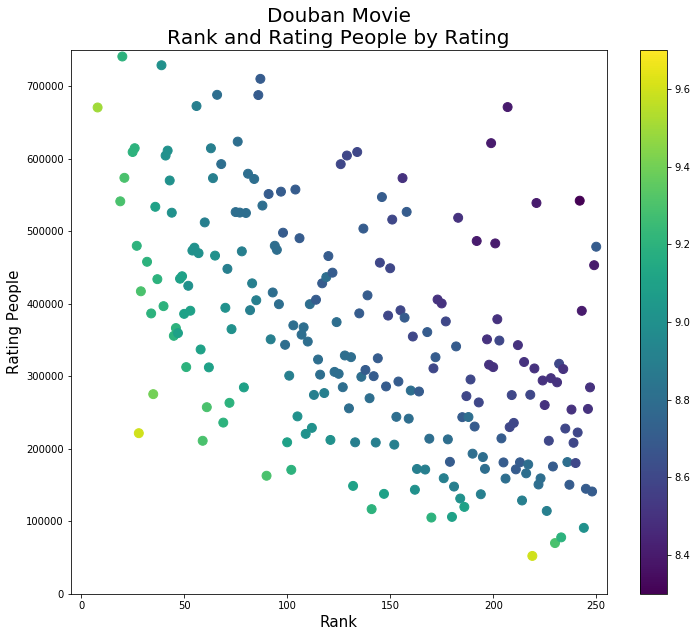
#评价人数
rank=np.array(Movie.index,dtype=int)+1 #index start from 0
Movie['0']=rank
f3=plt.figure(3,figsize=(12,10))
plt.scatter(x=Movie['0'],y=Movie['comment_num'],c=Movie['rating_num'],s=80)
plt.title('Douban Movie\nRank and Rating People by Rating',fontsize=20)
plt.xlabel('Rank',fontsize=15)
plt.ylabel('Rating People',fontsize=15)
plt.axis([-5,255,0,750000]) #x轴坐标范围
plt.colorbar() #显示colorbar
plt.savefig('DoubanMovie_Rank_and_RatingPeople_by_Rating.png')
plt.show()
By National Film Classification bar chart 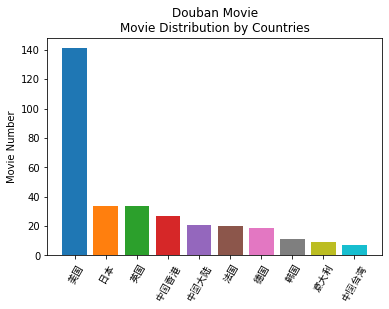 :
:
#!-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from matplotlib.font_manager import FontProperties #fontproperties的模块,pyde自动添加的,好评
Movie=pd.read_csv('./doubanmovietop.csv',encoding='utf-8')
country_iter=(set(x.split(' ')) for x in Movie['guojia']) #generator生成器,分解字符串
countries=sorted(set.union(*country_iter)) #Return the union of sets as a new set.
#*country_iter:This works for any iterable of iterables.
df=pd.DataFrame(np.zeros((len(Movie),len(countries))),columns=countries)#创建一个0DataFrame,np.zeros()内为要tuple
for i,gen in enumerate(Movie['guojia']):
df.ix[i,gen.split(' ')]=1 #第i条数据的country置为1
num_of_country=df.sum()
# print(num_of_country)
num_of_country[4]=num_of_country[1]+num_of_country[2]+num_of_country[4] #(1964中国大陆中国大陆重映)和中国大陆合并
# num_of_country.pop('中国')
# print(num_of_country)
num_of_country.sort_values(inplace=True,ascending=False)
f1=plt.figure()
for i,gen in enumerate(num_of_country[:10]):
plt.bar(i,gen) #i为bar的起始横坐标,gen为纵坐标,宽度默认
names=list(num_of_country.index)
plt.xticks(np.arange(10),names,fontproperties='SimHei',rotation =60) #在图中显示中文字符要加上fontproperties='SimHei'
plt.ylabel('Movie Number')
plt.title('Douban Movie\nMovie Distribution by Countries')
# plt.savefig('Movie_Distribution_by_Countries.png')
f1.show()
#因为有些影片为多国合作的,也算各自国家的吧。
#过滤了很多只有一两部的国家,果然还是美帝有金坷垃,亩产一万八
Genres distribution histogram: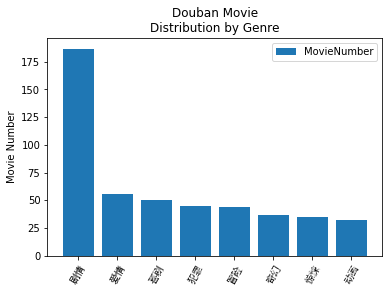
genre_iter=(set(x.split(' ')) for x in Movie['juqing'])
genre=sorted(set.union(*genre_iter))
frame=pd.DataFrame(np.zeros((len(Movie),len(genre))),columns=genre)
for i,gen in enumerate(Movie['juqing']):
frame.ix[i,gen.split(' ')]=1
genre_sum=frame.sum()
genre_sum.sort_values(inplace=True,ascending=False)
f2=plt.figure(2)
'''for i,gen in enumerate(genre_sum[:8]):
plt.bar(i,gen)
names=list(genre_sum.index)
plt.xticks(np.arange(8)+0.4,names,fontproperties='SimHei')
plt.show()'''
#改进的方法
p2=plt.bar(np.arange(8),genre_sum.values[:8],align='center') #p2包含8个元素,每个对应一个bar
names=list(genre_sum.index)
plt.xticks(np.arange(8),names,fontproperties='SimHei')
plt.legend((p2[0],),('MovieNumber',)) #只有一个元素的tuple应写成(ele,)
plt.ylabel('Movie Number')
plt.title('Douban Movie\nDistribution by Genre')
#plt.savefig('Movie_Distribution_by_Genre.png')
plt.show()

For more data, please reply back No public concern: IMDb
you can get -
