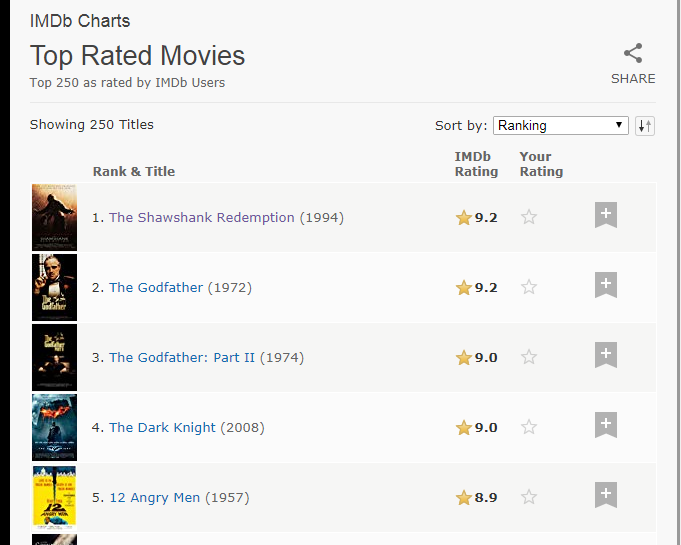
1. Open IMDB movie T250 Ranking can see 250 movies data, film name, score and other data can be seen
Press F12 into Developer mode, find the corresponding HTML page data structure, as shown in FIG.
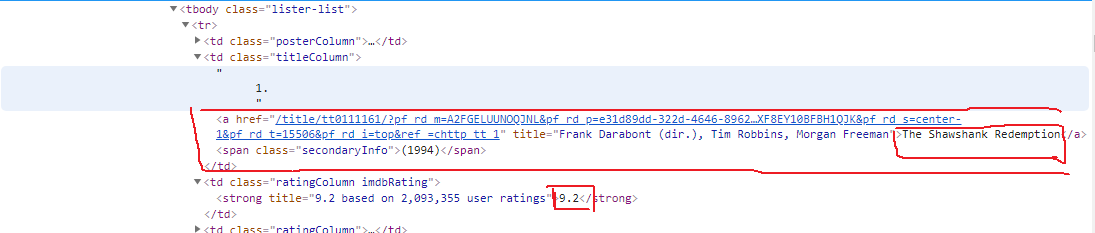
You can see there are links, click on the link to enter the movie details page, which you can see the director, screenwriter, actor information

Also see the HTML structure, you can find information on the location of the node

Actor information can be viewed in the full cast of the information on this page

HTML Page Structure
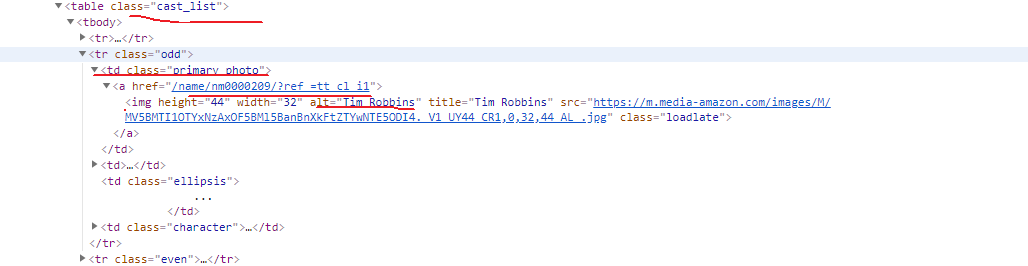
A complete analysis of the data to be crawling, now home to get 250 movie information
1. Relevant library code needs to use the entire crawler
import re import pymysql import json import requests from bs4 import BeautifulSoup from requests.exceptions import RequestException
2. Request Home HTML web pages (if the request is not relevant can be added by Header), return to the page content
def get_html(url): response=requests.get(url) if response.status_code==200: #判断请求是否成功 return response.text else: return None
3.解析HTML
def parse_html(html): #进行页面数据提取 soup = BeautifulSoup(html, 'lxml') movies = soup.select('tbody tr') for movie in movies: poster = movie.select_one('.posterColumn') score = poster.select_one('span[name="ir"]')['data-value'] movie_link = movie.select_one('.titleColumn').select_one('a')['href'] #电影详情链接 year_str = movie.select_one('.titleColumn').select_one('span').get_text() year_pattern = re.compile('\d{4}') year = int(year_pattern.search(year_str).group()) id_pattern = re.compile(r'(?<=tt)\d+(?=/?)') movie_id = int(id_pattern.search(movie_link).group()) #movie_id不使用默认生成的,从数据提取唯一的ID movie_name = movie.select_one('.titleColumn').select_one('a').string #使用yield生成器,生成每一条电影信息 yield { 'movie_id': movie_id, 'movie_name': movie_name, 'year': year, 'movie_link': movie_link, 'movie_rate': float(score) }
4.我们可以保存文件到txt文本
def write_file(content): with open('movie12.txt','a',encoding='utf-8')as f: f.write(json.dumps(content,ensure_ascii=False)+'\n') def main(): url='https://www.imdb.com/chart/top' html=get_html(url) for item in parse_html(html): write_file(item) if __name__ == '__main__': main()
5.数据可以看见

6.如果成功了,可以修改代码保存数据到MySQL,使用Navicat来操作非常方便先连接到MySQL
db = pymysql.connect(host="localhost", user="root", password="********", db="imdb_movie") cursor = db.cursor()
创建数据表
CREATE TABLE `top_250_movies` ( `id` int(11) NOT NULL, `name` varchar(45) NOT NULL, `year` int(11) DEFAULT NULL, `rate` float NOT NULL, PRIMARY KEY (`id`) )
接下来修改代码,操作数据加入数据表
def store_movie_data_to_db(movie_data): sel_sql = "SELECT * FROM top_250_movies \ WHERE id = %d" % (movie_data['movie_id']) try: cursor.execute(sel_sql) result = cursor.fetchall() except: print("Failed to fetch data") if result.__len__() == 0: sql = "INSERT INTO top_250_movies \ (id, name, year, rate) \ VALUES ('%d', '%s', '%d', '%f')" % \ (movie_data['movie_id'], movie_data['movie_name'], movie_data['year'], movie_data['movie_rate']) try: cursor.execute(sql) db.commit() print("movie data ADDED to DB table top_250_movies!") except: # 发生错误时回滚 db.rollback() else: print("This movie ALREADY EXISTED!!!")
run
def main(): url='https://www.imdb.com/chart/top' html=get_html(url) for item in parse_html(html): store_movie_data_to_db(item) if __name__ == '__main__': main()
View Navicat, you can see the data saved to the mysql.