Our daily work, a simple HTTP request, programmers tend to use everything python Requests library. However, under most scenarios, our needs are not purely static web page, the page load process is accompanied by a large number of JS files involved in the entire rendering process of the page, and each step of the page may be able to find the XHR asynchronous loading shadow. So Requests library is not a panacea, Requests-Html libraries can solve part of the problem, provided that you know what the process of loading js files. The actual work of a small climb, the more likely Requests + selenium patterns to crawl the entire web page complete information.
Requests can use the library directly to request data directly with Session class requests to the request, met JS load more pages, switch to selenium to perform.
So the question is, how gracefully requests to switch from selenium to complete the automation process the entire page of it? In many cases, our information page crawling, the server asking users to log in first, and then every time a request to ensure that the session session cookies and fundamental change, you can always guarantee login status background. So how cookies requests library pass selenium to use it? When this switch to selenium, we do not log in again, but the direct use of cookies requests to bind to the next selenium, request landing page, open the Web page can be the natural state of the landing.
Let's use the library to log requests, the code is usually the case (see the need to capture data parameter post request background, this configuration parameter before we ask it, landing data parameters for each page vary):
loginData={'redirect':'','username':username,'password':psw}
session = requests.Session()
r=session.post('%sportal/u/a/login.do'%base_url,loginData)
Upon completion of this operation, we can Post request status_code is equal to 200 to determine whether the successful landing page. Once the login is successful, the follow-up of the site's pages our session request, the session can be kept longer.
Next, what I want to get cookies after requests go to the website, it is an instance of the class Cookiejar of requests. Cookiejar is simply get the response cookie, cookie is some of the information stored in the browser, including user login information and some action in response to information we have obtained from the server, the cookie sometimes contains some information.

The problem is that this object is not cookiejar our common word objects typical cookies, we need to use utils.dict_from_cookiejar method requests to the library cookiejar object into a python dictionary object.
cookies=session.cookies
cookies=requests.utils.dict_from_cookiejar(cookies)
The resulting cookies probably the following form:
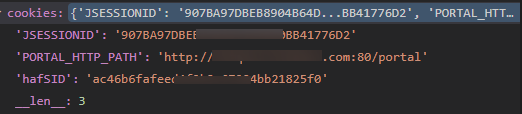
But this is still not the selenium support cookies format. In fact, selenium use driver.get_cookies () method to get the cookies as follows: the list contains more than one cookie dictionary, each dictionary contains multiple key-value pairs, and all the keys, and some are not necessary, but "name "," value "of these two keys is required.
"""传递request cookie给 selenium用""" for k,v in cookies.items(): driver.add_cookie({"name":k,"value":v})
Note that, we must first driver.get (your url), before you can use driver.add_cookie method, otherwise selenium error.
So far, we have successfully added selenium cookies captured in response to requests, we will not need to be asked selenium server first landed. requests to complete and selenium seamless, perfect!