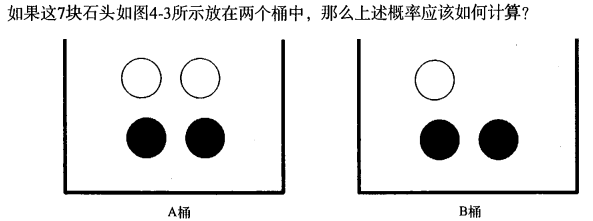
Classifiers can sometimes produce erroneous results, then may require classification given category guess an optimal result, the same
give an estimate of the probability of guessing when.
Probability theory is the basis for many machine learning algorithms
In computing
involves some knowledge of the probability of taking the value of the probability of a certain value feature where we take the first statistical feature set to a particular value in the data
number, and then divided by the total number of instances of data sets, we get to take the characteristic value The probability.
First, from a simple probabilistic classifier Start, and then give
some assumptions to learn naive Bayes classifier. We call it "naive" because the whole formal process only the most primitive,
the simplest hypothesis.
Classification Based on Bayesian decision theory

Naive Bayes is part of Bayesian decision theory, it is necessary to tell the simple negative Yates before a quick look at Bayeux
Sri Lanka decision theory.
Suppose now that we have a data set, which consists of two types of data consisting of
import matplotlib import matplotlib.pyplot as plt from numpy import * n = 1000 #number of points to create xcord0 = [] ycord0 = [] xcord1 = [] ycord1 = [] markers =[] colors =[] fw = open('E:\\testSet.txt','w') for i in range(n): [r0,r1] = random.standard_normal(2) myClass = random.uniform(0,1) if (myClass <= 0.5): fFlyer = r0 + 9.0 tats = 1.0*r1 + fFlyer - 9.0 xcord0.append(fFlyer) ycord0.append(tats) else: fFlyer = r0 + 2.0 tats = r1+fFlyer - 2.0 xcord1.append(fFlyer) ycord1.append(tats) #fw.write("%f\t%f\t%d\n" % (fFlyer, tats, classLabel)) fw.close() fig = plt.figure() ax = fig.add_subplot(111) #ax.scatter(xcord,ycord, c=colors, s=markers) ax.scatter(xcord0,ycord0, marker='^', s=90) ax.scatter(xcord1,ycord1, marker='o', s=50, c='red') plt.plot([0,1], label='going up') plt.show()
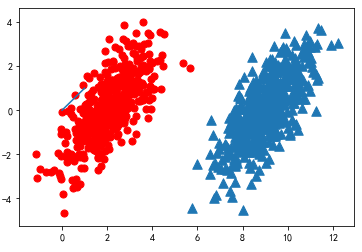
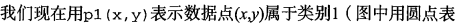

In other words, we would choose a high probability of the corresponding category. This is the core idea of Bayesian decision theory, that choice has
the decision-making of the highest probability.
Conditional Probability



The use of conditional probability to classify


Naive Bayes for document classification
An important application of machine learning is to automatically classify documents. In document classification, the entire document (e.g., email)
is an example, and some elements of the e-mail configuration features. Although e-mail is a text that will continue to increase, but we have the same
kind also can press reports, user messages, any other type of government documents such as text classification. We can observe the document
word appears, and the occurrences of each word, or does not appear as a feature, so the number of features will now get word vocabulary
as much purpose.




Using Python for text classification

准备数据:从文本中构建词向量
将把文本看成单词向量或者词条向量,也就是说将句子转换为向量。考虑出现在所有文
档中的所有单词,再决定将哪些词纳人词汇表或者说所要的词汇集合,然后必须要将每一篇文档
转换为词汇表上的向量。
from numpy import * def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0,1,0,1,0,1] #1 is abusive, 0 not return postingList,classVec def createVocabList(dataSet): vocabSet = set([]) #create empty set for document in dataSet: vocabSet = vocabSet | set(document) #union of the two sets return list(vocabSet) def setOfWords2Vec(vocabList, inputSet): returnVec = [0]*len(vocabList) for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) return returnVec postingList,classVec = loadDataSet() VocabList = createVocabList(postingList) print(VocabList)

returnVec = setOfWords2Vec(VocabList,postingList[0]) print(returnVec)

训练算法:从词向量计算概率
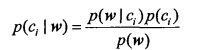


朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory): numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory)/float(numTrainDocs) p0Num = ones(numWords) p1Num = ones(numWords) #change to ones() p0Denom = 2.0 p1Denom = 2.0 #change to 2.0 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = log(p1Num/p1Denom) #change to log() p0Vect = log(p0Num/p0Denom) #change to log() return p0Vect,p1Vect,pAbusive
import matplotlib import matplotlib.pyplot as plt from numpy import * t = arange(0.0, 0.5, 0.01) s = sin(2*pi*t) logS = log(s) fig = plt.figure() ax = fig.add_subplot(211) ax.plot(t,s) ax.set_ylabel('f(x)') ax.set_xlabel('x') ax = fig.add_subplot(212) ax.plot(t,logS) ax.set_ylabel('ln(f(x))') ax.set_xlabel('x') plt.show()


贝叶斯分类函数 def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) if p1 > p0: return 1 else: return 0
这里的相乘是指对应元素
相乘,即先将两个向量中的第1个元素相乘,然后将第2个元素相乘,以此类推。接下来将词汇表
中所有词的对应值相加,然后将该值加到类别的对数概率上。最后,比较类别的概率返回大概率
对应的类别标签。
def testingNB(): listOPosts,listClasses = loadDataSet() myVocabList = createVocabList(listOPosts) trainMat=[] for postinDoc in listOPosts: trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses)) testEntry = ['love', 'my', 'dalmation'] thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)) testEntry = ['stupid', 'garbage'] thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) print(testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)) testingNB()

准备数据:文档词袋模型

朴素贝叶斯词袋模型
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) if p1 > p0: return 1 else: return 0