

Laboratory equipment and software environment
Hardware environment: Memory ddr3 4G above and x86 architecture hosts a
System environment: Windows
Software Environment: Anaconda2 (64- Wei ) , Python 3.5 , jupyter
Kernel version: window10.0
Test content and principles
( 1 ) Experiment:
Using k-nearest neighbor matching algorithm to improve the effect of dating sites. Helen use the URL to find their own dating Dating dating site will recommend different candidates. She had gone out of the man summed up into three types: do not like people, the charm of the average person, very charismatic person. Despite the discovery of these laws, but still can not be classified as dating sites offer the appropriate classification. Use KNN algorithm to better help her match the exact object is divided into categories.
Using handwriting recognition system constructed using k nearest neighbor algorithm k- nearest neighbor classifier. Figures have to be identified using image-processing software, the processing have the same size and color: black and white image width and height is 32 pixels * 32 pixels. The use of handwriting recognition system, it may be more convenient handwriting input, the handwriting recognition system and further improve the recognition rate. Allowing users to experience better handwriting input. During the experiment, although in text format for storing images inefficient use of memory space, but in order to facilitate understanding, we will convert the image to a text format.
( 2 ) Principle:
The core idea of kNN algorithm is that if a majority of the samples in the feature space of k-nearest neighbor samples belong to a category, then the sample also fall into this category, and has the characteristics of the sample on the category. The method in determining the classification decision based solely on the nearest one category or several samples to determine the category to be sub-sample belongs. kNN method in the decision-making categories, with only a very small amount of adjacent samples related. Since kNN method mainly limited by the surrounding adjacent samples, rather than a method of determining the discrimination class Category field, so for domains overlap or more class sample set is to be divided, the method kNN more than other methods suitable.
K-nearest neighbor (k-Nearest Neighbor, KNN) classification algorithm, is a more mature approach in theory, one of the most simple machine learning algorithm. The idea of the method is: if a sample in feature space of the k most similar (i.e. nearest feature space) most of the samples belonging to a particular category, then the sample may also fall into this category. KNN algorithm, the selected neighbors are already correctly classified objects. The method in a given class decisions based solely on the nearest one category or several samples to determine the category to be sub-sample belongs. KNN method, although in principle also depends on the limit theorem, but in the decision-making categories, with only a very small amount of adjacent samples related. Since the KNN method is mainly limited by the surrounding adjacent samples, rather than a method of determining the discrimination class Category field, so for class field of an overlap or more sub-sample set is to be, more than other methods KNN. suitable.
KNN algorithm not only can be used for classification, regression can also be used. By finding a sample k nearest neighbor, the average value of the property assigned to these neighbors of the sample, you can get the properties of the sample. The method is more useful to the neighbors of the different distances of the sample produced are given different weights (weight), as the weights inversely proportional to distance.
Algorithm steps:
1. Prepare data, data pre-processing
2. The appropriate choice of data structure stored training data and test tuple
3. Set parameters such as k
4. Maintenance of a size k by distance descending priority queue , for storing training nearest neighbor tuples. Selected randomly from the training tuple k as an initial tuples nearest neighbor tuples, each tuple is calculated from this test k tuples, tuples numerals and will train the distance stored in the priority queue
The traverse the training set of tuples, the distance calculating the current training and test tuple of tuples, the resulting maximum distance Lmax L and the priority queue
6. comparison. If L> = Lmax, the tuple is discarded, the next traverse tuple. If L <Lmax, delete the priority queue maximum distance of tuples, the current training tuple into the priority queue.
7. traversal is complete, the majority class calculated priority queue of k-tuples, tuples and as a test of its category.
8. Test tuples After completion of the test error rate is calculated to continue setting different values of k re-training, take the last value k the minimum error rate.
Algorithms advantages:
1. Simple, easy to understand, easy to implement, without estimating parameters, no training;
2. Suitable for rare events are classified;
3. especially suitable for multi-classification problems (multi-modal, object has multiple category labels), kNN better performance than SVM.
Algorithms Disadvantages:
The classification algorithm in the major drawback is that when the sample imbalance, such as a large sample size class, and other classes very small sample sizes, it is possible when entering a new sample cause, the sample of K neighborhood bulk sample class majority. The algorithm calculates only the "closest" neighbor samples, a large number of samples of a class, then this type of sample is not close to the target or sample, or very close to the target sample of these samples. In any case, the number does not affect the results.
Another weakness of this method is computationally expensive, because each text should be classified calculate its distance to all the known samples in order to obtain its K nearest neighbor points.
Intelligibility is poor, can not give that kind of like a decision tree rule.
Improvement Strategies:
kNN algorithm for its proposed earlier time, along with other constantly updated and improved technologies, many shortcomings kNN algorithm is gradually revealed, so many improved algorithm kNN algorithms have emerged.
For lack of direction improved algorithm above algorithm is divided into two main aspects of the classification efficiency and classification results.
Category efficiency: prior to sample attributes reduction, removes the effects of a smaller property classification results, quickly come to class to be classified samples. This algorithm is more suitable for larger sample size automatic classification class field, and the smaller the sample size class field is generated using this algorithm is relatively easy to misclassification.
Classification results: Methods weights (neighbor rights and the sample small distance is greater) to improve, Han, who tried to use the greedy algorithm for document classification real do heavy adjustable weights k-nearest neighbor method WAkNN (weighted 2002 adjusted k nearest neighbor), to facilitate the classification effect; and Li et al due to the different classification of the files themselves have differences on the number and, therefore, should be in accordance with the number of documents in the training set various classifications, selecting a different number of recent in 2004 neighbors to participate in the classification.
And experiment results (mappable)
Use k- nearest neighbor pairing effect of improved dating site
( 1 ) Data Source Description
Experimental data given source datingTestSet.txt , total . 4 columns, each attribute are: ① PERCENTAGE of Playing Time spenting Vedio games ; ② Frequent flied Miles Earned per year ; ③ liters of ICE Cream Consumed per year ; ④ your towars the this people Attitude . By analyzing the data in the data source to obtain a law in order to determine a person's first three properties to come to divide Helen attitude towards him.
( 2 ) KNN algorithm theory
Each point on the unknown properties of a data set once the following
Calculating the distance of each known class data set point and the current point
In turn ordered by distance increments
Selecting a minimum distance to the current point k points
Determine k a point where the frequency of occurrence of categories
Returns the k th point of the highest point of the frequency of occurrence as the classification of the current point
(3) Analysis of data
The first to use Mapplotlib scatter plots produced raw data, in jupyter notebook command-line environment, enter the following command:


Type effect is as follows: The following scattergram using datingDataMat second, third column of the data matrix, respectively feature value "percentage of time spent playing video games" and "the number of liters of ice cream consumed weekly."
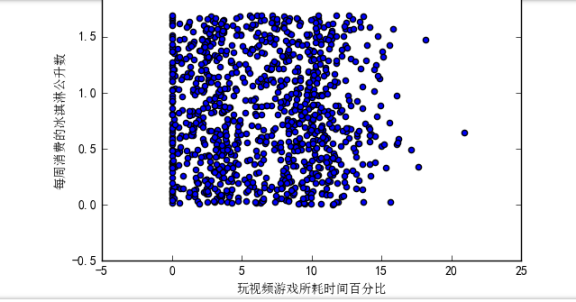
Since no classification characteristic values of the samples, it is difficult to see the useful data mode information from the above figure. In general, the color will be used to mark or other symbol classification of different samples, in order to better understand the data. Matplotlib library provides scatter functions support point on the scatter plot a personalized tag. Re-enter the code above is as follows:

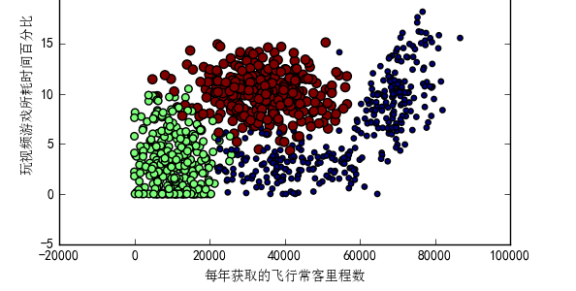
上述代码利用变量datingLabels存储的类标志属性,在散点图上绘制了色彩不等、尺寸不同的点。可以看到与上图类似的散点图。但从上图中,我们很难看出有用的信息,然而由于下图利用颜色及尺寸标识了数据点的属性类别,因而我们基本上可以从下图中看到三个样本分类的局域轮廓:

以上我们使用datingDataMat矩阵的第二和第三列属性来展示数据,虽然也可以区别,但是在下面的图中,采用的是矩阵第一和第二列属性却可以得到更好的展示效果,下面图中清晰地标识了三个不同的样本分类区域,具有不同爱好的人其类别区域也不同。代码及效果图如下:

(4)KNN算法实现 ① 利用python实现构造分类器 首先计算欧式距离然后选取距离最小的K个点 代码如下: def classify0(inMat,dataSet,labels,k): dataSetSize=dataSet.shape[0] #KNN的算法核心就是欧式距离的计算,一下三行是计算待分类的点和训练集中的任一点的欧式距离 diffMat=tile(inMat,(dataSetSize,1))-dataSet sqDiffMat=diffMat**2 distance=sqDiffMat.sum(axis=1)**0.5 #接下来是一些统计工作 sortedDistIndicies=distance.argsort() classCount={} for i in range(k): labelName=labels[sortedDistIndicies[i]] classCount[labelName]=classCount.get(labelName,0)+1; sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0]

② 解析数据 输入文件名,将文件中的数据转化为样本矩阵,方便处理 代码如下: def file2matrix(testFileName,parammterNumber): fr=open(testFileName) lines=fr.readlines() lineNums=len(lines) resultMat=zeros((lineNums,parammterNumber)) classLabelVector = [] index = 0 for line in arrayOLine: line = line.strip()#strip,默认删除空白符(包括'\n', '\r', '\t', ' ') listFromLine = line.split('\t') returnMat[index, :] = listFromLine[0: 3] #选取前3个元素存储到特征矩阵 classLabelVector.append(int(listFromLine[-1])) #-1表示最后一列元素,如果不用int(),将当做字符串处理 index += 1 return returnMat, classLabelVector 返回值为前三列属性被写入到resultMat二维数组中,第四列属性作为标签写入到classLableVector中


③ 归一化数据 不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影 响到数据分析的结果,为了消除指标之间的量纲影响,需要进行 数据标准化处理,使各指标处于同一数量级。 处理过程如下: def autoNorm(dataSet): minVals = dataSet.min(0) #存放每一列的最小值,min(0)参数0可以从列中选取最小值,而不是当前行最小值 maxVals = dataSet.max(0) #存放每一列的最大值 ranges = maxVals - minVals #1 * 3 矩阵 normDataSet = zeros(shape(dataSet)) #列 m = dataSet.shape[0] #行 normDataSet = dataSet - tile(minVals, (m, 1)) #tile(A, (row, col)) normDataSet = normDataSet/tile(ranges, (m, 1)) return normDataSet, ranges, minVals

④ 测试数据 在利用KNN算法预测之前,通常只提供已有数据的90%作为训练样本,使用其余的10%数据去测试分类器。注意10%测试数据是随机选择的,采用错误率来检测分类器的性能。错误率太高说明数据源出现问题,此时需要重新考虑数据源的合理性。 def datingClassTest(trainigSetFileName,testFileName): trianingMat,classLabel=file2Mat(trainigSetFileName,3) trianingMat,minVals,ranges=autoNorm(trianingMat) testMat,testLabel=file2Mat(testFileName,3) testSize=testMat.shape[0] errorCount=0.0 for i in range(testSize): result=classify((testMat[i]-minVals)/ranges,trianingMat,classLabel,3) if(result!=testLabel[i]): errorCount+=1.0 errorRate=errorCount/(float)(len(testLabel)) return errorRate;
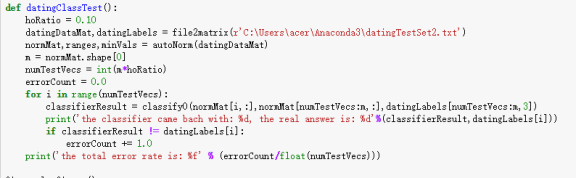
⑤ 使用KNN算法进行预测 如果第四步中的错误率在课接受范围内,表示可以利用此数据源进行预测。输入前三项属性之后较为准确的预测了分类。 代码如下: def classifyPerson() resultList = [‘not at all’,’in small doses’,’in large doses’] percentTats = float(raw_input(”percentage of time spent playing video games?”)) #玩游戏占用了多少时间 ffMiles = float(raw_input(“frequent flier miles earned video games?”)) #玩游戏赚了多少飞行里程 iceCream = float(raw_input(“liters of ice cream consumed per year?”)) #每年消费多少升雪糕 datingDataMat,datingLabels = file2matrix(‘datingTestSet2.txt’) normMat,ranges,minVals = autoNorm(datingDataMat) inArr = array([ffMiles,percentTats,iceCream]) classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3) print (“You will probably like this person:”,resultList[classifierResult-1])

预测的结果如下图所示:

使用k-近邻算构建手写识别系统 实现图像存储在目录trainingDigits中包含了大约2000个例子,每个例子的内容都是一些数字,每个数字大约有200个样本;目录testDigits中包含大约900个测试数据。使用目录trainingDigits中的数据训练分类器,使用目录testDigits中的数据测试分类器的效果。这两组的数据是没有重叠的。 为了使用前面两个分类器,现在必须将图像格式化处理为一个向量。将把一个32*32的二进制图像矩阵转换为1*1024的向量,这样前两节使用的分类器就可以处理数字图像信息了。 具体算法的实现如下: 手写识别系统KNN算法实现 ① 利用python实现构造分类器 首先计算欧式距离然后选取距离最小的K个点 代码如下: def classify0(inMat,dataSet,labels,k): dataSetSize=dataSet.shape[0] #KNN的算法核心就是欧式距离的计算,一下三行是计算待分类的点和训练集中的任一点的欧式距离 diffMat=tile(inMat,(dataSetSize,1))-dataSet sqDiffMat=diffMat**2 distance=sqDiffMat.sum(axis=1)**0.5 #接下来是一些统计工作 sortedDistIndicies=distance.argsort() classCount={} for i in range(k): labelName=labels[sortedDistIndicies[i]] classCount[labelName]=classCount.get(labelName,0)+1; sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0]
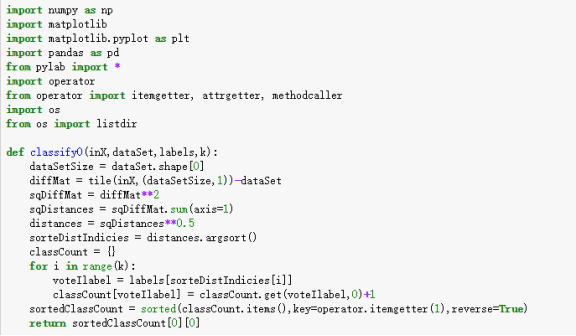
② 解析数据
编写一段函数img2vector,将图像转换为向量:该函数创建1*1024的NumPy数组,然后打开给定的文件,循环读出文件的前32行,并将每行的头32个字符值存储在NumPy数组中,最后返回数组。具体代码如下:

在jupyter notebook中输入下列命令测试上面的img2vector函数,然后与文本编辑器打开的文件进行比较。具体代码及其输出如下:

输入效果如下:

③ 归一化数据
不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影 响到数据分析的结果,为了消除指标之间的量纲影响,需要进行 数据标准化处理,使各指标处于同一数量级。
但在这个手写识别系统中,每一个图像数据都是二元的数字,所以不需要再另将数据进行归一化处理。
④ 测试数据
在前面现实:改进约会网站的配对效果这一实验时,已经将数据处理成分类器可以识别的格式,现在我们将这些数据输入到分类器,检测分类器的执行效果。下面的代码主要是:自包含函数handwritingClassTest()是测试分类器。但在写入这些代码之前,必须确保将from os import listdir写入到文件的起始部分,这段代码的主要功能是从os模块中导入函数listdir,它可以列出给定目录的文件名。
具体代码如下:

在上面的程序清单中,将trainingDigits目录中的文件内容存储在列表trainingFileList中,然后可以得到目录中有多少文件,并将其存储在变量m中,接着,代码创建一个m行1024列的训练矩阵,该矩阵的行数据存储一个图像。我们可以从文件名中解系分类数字(第一个for循环的作用)。该目录下的文件按照规则命名,如文件9_45.txt的分类是9,它是数字9的第45个实例。然后我们可以将类代码存储在hwLabels向量中,使用前面讨论的img2vector函数载入图像。在下一步中,我们对testDigits目录中的文件执行相似的操作,不同之处是我们并不将这个目录下的文件载入矩阵中,而是使用classify0()函数测试该目录下的每一个文件。由于文件中的值已经在0和1之间,所以不需要上面使用的autoNorm()函数。
在jupyter notebook中输入handwritingClassTest(),测试该函数的输出结果。依赖于机器速度,加载数据集可能需要花费很长的时间,然后函数开始依次测试每个文件。具体的操作情况,如下图所示:

..........................................(篇幅有限)

从上面的输出可以看出:K-邻近算法识别手写数字数据集,错误率为1.2%。改变变量k的值、修改函数handwritingClassTest随机选取训练样本、改变训练样本的数目,都会对k-近邻算法的错误率产生影响。
⑤ 使用KNN算法进行预测
如果第四步中的错误率在课接受范围内,表示可以利用此数据源进行预测。读取一份手写数字二元数据集,使用前面的算法进行预测。
使用的预测文件数据截图如下:
文件8_179.txt具体数据截图如下:


代码如下:

算法输出的结果是:
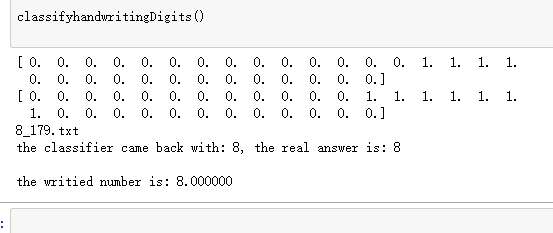
可以看到:这个预测是数字8,和实际的输入相对应,所以这个手写预测结果是正确的。
操作异常问题与解决方案
- KNN算法中的K值的大小对分类的影响?
答:K值选取的太小,模型太复杂。K值选取的太大,导致分类模糊。例如:k=1,则表示取距离测试数据距离最近的那一个样本数据的类作为预测数据的类。k=n,表示这个样本数据集中的n个样本数据,那个数据的类别多,那么被预测的数据就那个类别最多的类。
解决方案:
A、可以用Cross Validation。
B、可以用贝叶斯
C、可以用bootstrap
2. 如何理解KNN算法,其是否存在不足?
答:(1)理解:kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
(2)不足:
A、该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
B、该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
C、可理解性差,无法给出像决策树那样的规则。
实验总结
通过本实验,我主要学习和掌握了: K-NN算法分类的原理及其具体的实现
骤。主要内容包括以下几个方面:
1、更加深入地学习和了解了KNN近邻算法的原理
2、对于python的相关语法和函数的理解和使用更加的透彻和熟练了
3、对于KNN近邻算法的大体的操作步骤,我现在也能够很熟悉地运用了
4、但在实验过程,由于python的版本的不兼容性,在一些函数库及函数的使用方面花费了一定的时间,但最后通过努力,还是将所遇到的问题都很好地解决了
5、通过k-近邻算法改进约会网站的配对效果和构建手写识别系统,在于积累代码编写,系统逻辑思维能力,抽象思维能力等方面,也有所提升。
6、希望通过后期的努力,更进一步地提升自己在机器学习代码编写,算法理解等方面的能力。
最后很感谢老师的指导和他的支持......