Fragment (Sharding) is used to MongoDB large data set assigned to different dispersion methods used by the server, so does not require a powerful server can store more data processing and greater load. The basic idea is to set cut small, dispersed into a plurality of blocks sheet, each sheet is only responsible for a portion of the total data, and finally performs equalization (data migration for each fragment by an equalizer. operated by a routing process is called mongos, know mongos and correspondence data sheet (by the configuration server).
The basic architecture

- mongos: inlet access the cluster, which itself is not persistent data, read and write operations are performed by the component is recommended to ensure that multiple components in a cluster in a consistent state mongos generally have a plurality of nodes.
- config server: metadata storage clusters, i.e., each slice of data which contains information (a mapping, the real data is not saved), a small space is needed
- shard: storing user data traffic, may be a replica set may be a single machine, the stored data in the unit of chunk
When do I need to use fragmentation?
- Lack of a single machine storage
- A single machine can not meet the performance requirements of the data written by the writing pressure so dispersed slice to each slice above, using the server's own resource fragmentation
What chunk that?
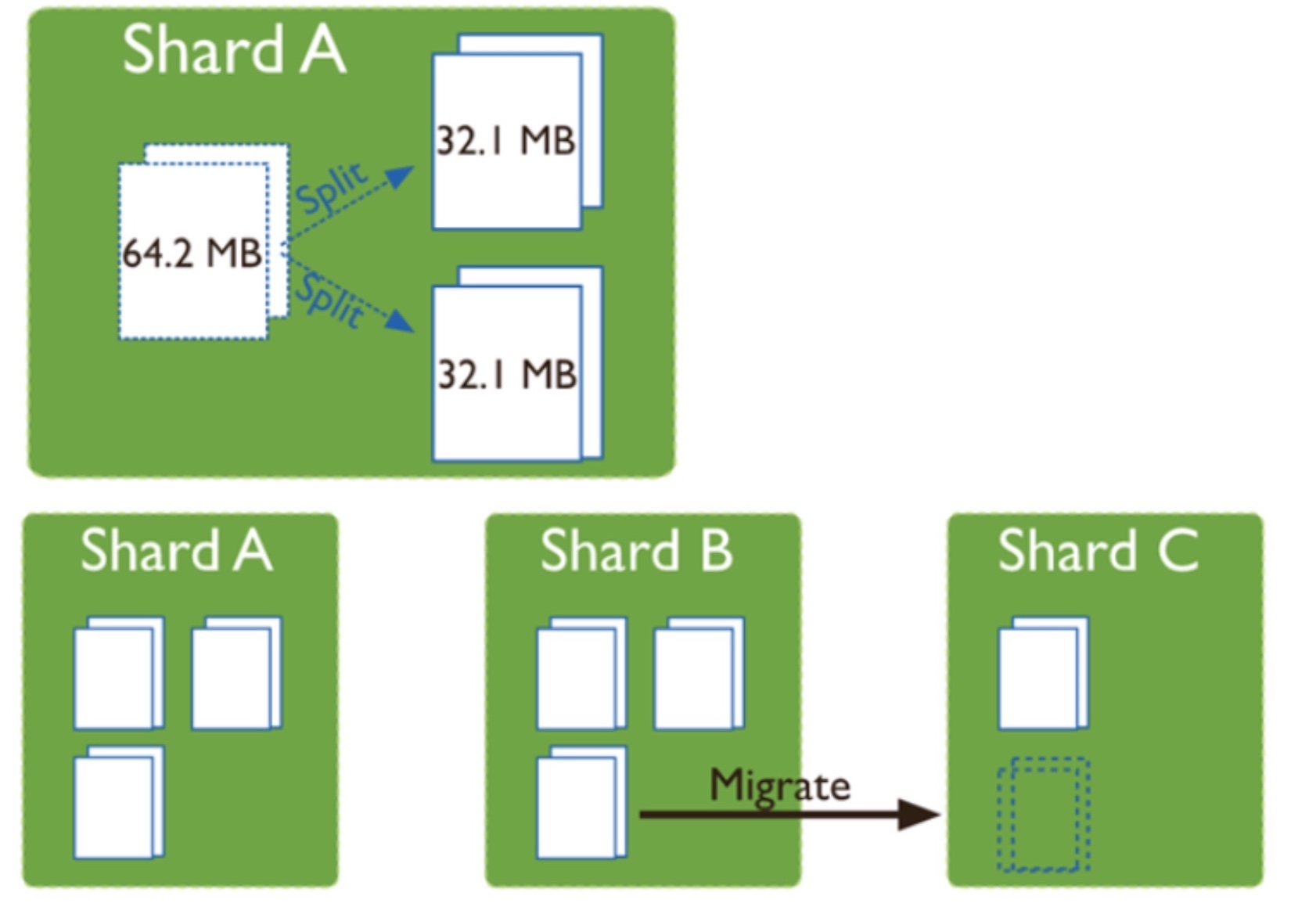
After using sharding function, based on the data shard keyto the chunk of data is divided into different shard onto the server chunk(默认64M)mainly has the following functions
- spliting (split)
when data is written when the amount of data written on a chunk, overchunk size(64M)time, mongodb background process triggers chunk split, split into smaller chunk, to prevent a single chunk too large - balancing (balance)
when on each shard chunk uneven distribution, migration triggered chunk. chunk of division and migration consuming IO resources.
chunk在写入数据时会分裂, 在读取时不会. chunksize会影响数据的迁移速度, 如果chunksize很大, 数据分裂少, 但是迁移会很慢, 还可能出现chunk内文档数过多无法迁移(chunk 内文档数不能超过 250000)
jumbo chunk
MongoDB 默认的 chunk size 为64MB,如果 chunk 超过64MB 并且不能分裂(比如所有文档 的 shard key 都相同),则会被标记为jumbo chunk ,balancer 不会迁移这样的 chunk,从而可能导致负载不均衡
数据分布
范围分片(Range based)和hash分片(Hash based)
- 范围分片
优点: 能很好满足范围查询的需求, 因为连续的数据大概率在一个shard上, 也可能在一个chunk上.
缺点: 如果分片键是连续递增的话, 新插入数据会落到一个chunk上, 如果这部分数据特别活跃, 则不能充分利用集群的性能优势. 注意: mongodb的_id高位是时间戳递增的 - hash分片
优点: 可以更好的利用集群性能
缺点: 不能快速进行范围查询
分片键
分片键决定了数据会以怎样的策略进行分布, 主要有
- 递增型
- 随机性
- 混合型
可以结合业务特点来选择合适的分片键, 同时要注意以下
- 分片键一旦设置不能取消
- 分片键必须有索引. 如果集合是非空, 必须先设置该field为索引, 才能指定为分片键
- 分片键用于路由查询
- 分片键大小限制512bytes
# 启用数据库分片:
sh.enableSharding("<database>")
# 使用hash分片键
sh.shardCollection('db.collection', {'field':'hashed'})
# 使用递增分片键
sh.shardCollection('db.collection', { field: 1})
# 查看分片是否成功
db.collection.stats().sharded
# 查看数据分布
db.collection.getShardDistribution()参考资料
