1. mongodb replica set concept
Replication of mongodb requires at least two nodes. One of them is the master node, which is responsible for database write operations, and the rest are slave nodes, which are responsible for replicating the data on the master node and can perform read operations.
The common collocation methods of mongodb nodes are: one master and one slave, one master and multiple slaves.
The master node records all operations oplogs on it, and the slave node periodically polls the master node to obtain these operations, and then performs these operations on its own data copy, thereby ensuring that the slave node's data is consistent with the master node.
mongodb can have arbiter nodes in the replica set. The arbiter nodes are mainly responsible for electing the master node and do not store data themselves.
If the mongodb replica set works normally, at least n/2+1 nodes need to survive, n/2 is a rounded down integer
1.1. mongodb replica set construction
Now build a replica set with 3 mongodb nodes, a master node, a slave node, and an arbiter node. The main parameters are as follows:
--dbpath data file path
--logpath log file path
--port port number, the default is 27017. I also use this port number here.
--replSet The name of the replica set, each node in a replica set must use a replica set name for this parameter
--maxConns maximum number of connections
--fork run in background
--logappend The log file is rotated, if the log file is full, the new log will overwrite the longest log.
1.1.1 Start mongodb node 1
mongod.exe --port 27017 --dbpath D:\work\mongodb\1 --replSet test --logpath D:\work\mongodb\1\log1\log.txt --logappend
1.1.2 Start mongodb node 2
mongod.exe --port 27018 --dbpath D:\work\mongodb\2 --replSet test --logpath D:\work\mongodb\2\log2\log.txt --logappend
1.1.3 Start mongodb node 3
mongod.exe --port 27019 --dbpath D:\work\mongodb\3 --replSet test --logpath D:\work\mongodb\3\log3\log.txt --logappend
1.1.4 Cluster Node Configuration
step1: mongo.exe connects to the mongod server
step2: Assume that the host pointed to by the current ip is configured in hosts as zhq.test.com
rs.initiate()
rs.add("zhq.test.com:27018")
rs.addArb("zhq.test.com:27019")
rs.status() to view the replica set status
2. The concept of mongodb sharding
When MongoDB stores massive amounts of data, one machine may not be enough to store the data, or it may not be enough to provide acceptable read and write throughput, and perhaps a master node cannot provide enough write throughput. At this time, we can split the data on multiple machines so that the database system can store and process more data. The structure of the split is as follows:
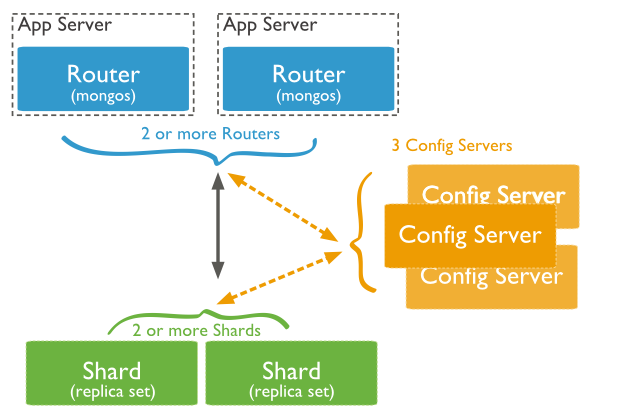
Shard: used to store real shard data, each shard can use a replica set to store data redundantly as a cluster
Config Server: mongod instance that stores metadata for the entire cluster
Router: routing service, the application server can use the sharding function of mongodb by accessing the routing service
2.1 Create two mongodb replica sets
According to that step, we create test and test1 replica sets, the difference is that we need to add the --shardsvr parameter:
2.1.1 Start the mongodb node 1 of the test and test1 clusters
mongod.exe --port 27017 --dbpath D:\work\mongodb\1 --replSet test --logpath D:\work\mongodb\1\log1\log.txt --logappend --shardsvr
mongod.exe --port 27020 --dbpath D:\work\mongodb\4 --replSet test1 --logpath D:\work\mongodb\4\log4\log.txt --logappend --shardsvr
2.1.2 Start the mongodb node 2 of the test and test1 clusters
mongod.exe --port 27018 --dbpath D:\work\mongodb\2 --replSet test --logpath D:\work\mongodb\2\log2\log.txt --logappend --shardsvr
mongod.exe --port 27021 --dbpath D:\work\mongodb\5 --replSet test1 --logpath D:\work\mongodb\5\log5\log.txt --logappend --shardsvr
2.1.3 Start the mongodb node 3 of the test and test1 clusters
mongod.exe --port 27019 --dbpath D:\work\mongodb\3 --replSet test --logpath D:\work\mongodb\3\log3\log.txt --logappend --shardsvr
mongod.exe --port 27022 --dbpath D:\work\mongodb\6 --replSet test1 --logpath D:\work\mongodb\6\log6\log.txt --logappend --shardsvr
2.1.4 Cluster Node Configuration
step1:mongo.exe --port 27020 connect to mongod server
step2: Assume that the host pointed to by the current ip is configured in hosts as zhq.test.com
rs.initiate()
rs.add("zhq.test.com:27021")
rs.addArb("zhq.test.com:27022")
rs.status() to view the replica set status
2.2 Establish a cluster consisting of two mongodb config servers (this is based on the mongodb3.2 version, the version below mongodb3.0 only needs to start two mongod nodes, no need to establish a cluster)
mongod.exe --port 27023 --dbpath D:\work\mongodb\config1 --logpath D:\work\mongodb\config1\config.log --logappend --replSet config --configsvr
mongod.exe --port 27024 --dbpath D:\work\mongodb\config2 --logpath D:\work\mongodb\config2\config.log --logappend --replSet config --configsvr
mongo.exe --port 27023 connect to mongod server
Assume that the host that the current ip points to is configured in hosts as zhq.test.com
rs.initiate()
rs.add("zhq.test.com:27024")
rs.status() to view the replica set status
2.3 Create two mongos nodes
mongos.exe --port 27025 --configdb config/zhq.test.com:27024,zhq.test.com:27023 --fork --logpath D:\work\mongodb\route1\route.log
mongos.exe --port 27026 --configdb config/zhq.test.com:27024,zhq.test.com:27023 --fork --logpath D:\work\mongodb\route2\route.log
2.4 Connect to a mongos node and configure sharding (only need to connect a mongos to add these configurations, other mongos configurations will be automatically synchronized through the config server)
mongo.exe --port 27025
db.runCommand({addshard:"test/zhq.test.com:27017,zhq.test.com:27018,zhq.test.com:27019"})//Add shard 1 cluster
db.runCommand({addshard:"test1/zhq.test.com:27020,zhq.test.com:27021,zhq.test.com:27022"})//Add shard 2 cluster
db.runCommand({ enablesharding:"test" }) //Set the sharded database
db.runCommand({ shardcollection: "test.log", key: { title:1}})//Set the field title of the table log for sharding
sh.status({verbose:true}) can view the status of the current shard
2.5 How to select shard fields
a. Each record must contain a fragmented field. After the fragmentation field is set, mongodb will automatically create an index for this field
a. The shard field needs to have many different values. Facilitate data segmentation and migration
b. The sharding field should be combined with the application, so that the application can query one shard as much as possible, and there is no need to combine the results of multiple shards
c. The value of the sharding field should be as scattered and random as possible, so that when inserting data, it can be inserted into different shards to avoid excessive pressure on one shard
https://my.oschina.net/seektechnology/blog/870316