Pre-skills: tree line, DFS
When I first heard "chain split tree" algorithm, I felt it must be very big on. It seems that it is indeed high on big now, but also very violent (personal opinion, do not like do not spray)
basic concepts
Chain split tree, computer terminology, refers to a partitioning of an algorithm tree, which tree to split into a plurality of side chains by weight, to ensure that each point belongs and only belongs to one strand, and then the data structure ( Fenwick tree, SBT, SPLAY, tree line, etc.) to maintain each strand.
---- one of Wikipedia
Baidu Encyclopedia of what the tree section have made it very clear, the next we'll look at other concepts.
- Heavy sons: For each non-leaf node, it is the son of the son of the most neutron tree node
- Light sons: For each non-leaf node, son other than its weight in addition to son
- Heavy side: father node connected to heavy son's side
- Light Edge: Father son nodes connected to the light side
- Heavy chain: connected by a plurality of edges into a tree heavy chain
- Light chain: connected by a plurality of light into a side chain of the tree
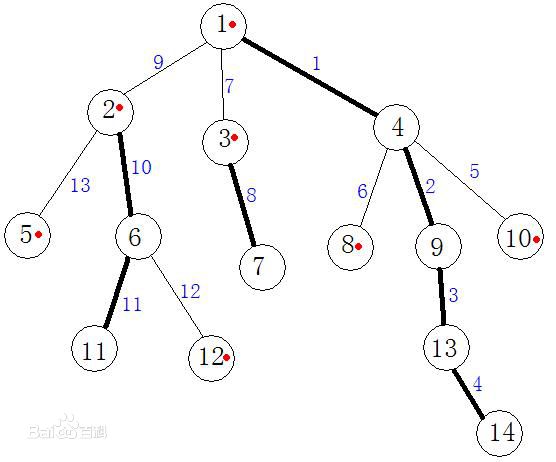
In this image, the light is reddish son point, son the balance weight; bold side edge of a weight, the remainder being the light side; \ (1 -> 14, \; 2 -> 11, \; 3 -> 7 \) path for the heavy chain, the remainder of the light chain.
Some degree already said, the chain split tree to tree by the severity of side split into multiple strands, then it is how to find out the severity of the side, how is split in it? Do not worry, we then speak
Implementation
First thing we need to talk about what requirements
| variable | meaning |
|---|---|
| \(f[i]\) | Node \ (I \) father |
| \(son[i]\) | Node \ (I \) weight son (if \ (I \) has two or more heavy son, the just specified) |
| \(size[i]\) | Node \ (I \) subtree size |
| \ (Nipple [i] \) | Node \ (I \) depth |
| \(top[i]\) | Node \ (I \) to the top of the heavy chain is located (if \ (I \) is the son of light, the \ (top [i] \) is equal to itself) |
| \(pos[i]\) | Node \ (I \) a new number (as will be appreciated point \ (I \) corresponding to \ (Rank \) array indices) |
| \(rank[i]\) | Number \ (I \) points corresponding to the right node of the tree |
Wherein a first four variables can be \ (the DFS \) is obtained, the remaining three may be the first \ (the DFS \) based on another by one \ (the DFS \) is determined
Code like this drop:
void dfs1(int now,int fa){
f[now]=fa, deth[now]=deth[fa]+1, size[now]=1;
for(int i=head[now];i;i=e[i].nex){
int to=e[i].t;
if(to==fa) continue;
dfs1(to,now);
size[now]+=size[to];
if(size[to]>size[son[now]]) son[now]=to;
}
}
void dfs2(int now,int topp){
top[now]=topp, pos[now]=++dfn, rank[dfn]=a[now];
//a[i]表示结点i的点权
if(!son[now]) return ;
dfs2(son[now],topp);
for(int i=head[now];i;i=e[i].nex){
int to=e[i].t;
if(to!=son[now]&&to!=f[now]) dfs2(to,to);
}
}In our second time \ (DFS \) time, we are re-son-first search, which is to ensure the heavy chain \ (rank \) continuity of the array, in addition to a heavy chain, a number in the sub-tree \ (rank \) array is continuous.
Why should I do? Next thing you know.
This, we will split the tree chain finished. But now we find so many things that they can do it?
Remember said at the beginning of a degree on Wikipedia can " to maintain each strand through data structures (Fenwick tree, SBT, SPLAY, tree line, etc.) " do? Yes, after obtaining so many things, we can use the familiar data structures to fiddle The tree of (fog
To facilitate understanding + wide range of applications, we are speaking about an example segment tree maintenance tree chain (In fact, because bloggers too betel, only segment tree)
Let us assume that title the following:
- All tree nodes from x to y shortest path node values plus z
- Tree request from x to y values of all nodes in the shortest path of nodes and
- X is a root node will be the subtree nodes values are all plus z
- Find all the nodes in the value x is a root node of the subtree and
We said above: a heavy chain in \ (rank \) array is continuous, a sub-tree in \ (rank \) array is continuous. So many times we can modify the interval and multiple range queries to get the four operating segments used by the tree.
First segment tree:
In fact, everything has changed very little tree line, and how to play or how to play, but you want to maintain the array become our cross out \ (rank \) array
code show as below:
void build(int l,int r,int p){ //建树
if(l==r){
tree[p]=rank[l]; return ; //要注意这里的数组是rank
}
build(l,mid,ls); build(mid+1,r,rs);
tree[p]=tree[ls]+tree[rs];
}
void down(int l,int r,int p){ //下传懒标记(我太蒟了,不会标记永久化)
tag[ls]+=tag[p]; tag[rs]+=tag[p];
tree[ls]+=(mid-l+1)*tag[p];
tree[rs]+=(r-mid)*tag[p];
tag[p]=0;
}
void update(int l,int r,int p,int nl,int nr,ll k){ //区间修改
if(nl<=l&&nr>=r){
tag[p]+=k; tree[p]+=(r-l+1)*k;
return ;
}
down(l,r,p);
if(nl<=mid) update(l,mid,ls,nl,nr,k);
if(nr>mid) update(mid+1,r,rs,nl,nr,k);
tree[p]=tree[ls]+tree[rs];
}
ll query(int l,int r,int p,int nl,int nr){ //区间查询
ll ans=0;
if(nl<=l&&nr>=r) return tree[p];
down(l,r,p);
if(nl<=mid) ans+=query(l,mid,ls,nl,nr);
if(nr>mid) ans+=query(mid+1,r,rs,nl,nr);
return ans;
}That segment tree tree how to use it?
If the point \ (x \) and (y \) \ is not on a heavy chain, let them jump up, jump up on a heavy chain. In order to prevent more jumping away, we make a deeper depth to jump on the other strand. When jumping, because the heavy chain is in the array in a row , we can use segment tree Sector Change / queries to deal with this part, through multiple range operation, we will be able to realize this operation 1,2.
void upd(int x,int y,ll k){ //将树从x到y结点最短路径上所有节点的值都加上z
while(top[x]!=top[y]){ //如果不在一条重链上
if(deth[top[x]]<deth[top[y]]) swap(x,y);
update(1,n,1,pos[top[x]],pos[x],k);
x=f[top[x]]; //让更深的跳上来,跳到另一条链上,顺便加上区间修改
}
//如果在一条链上
if(deth[x]>deth[y]) swap(x,y);
update(1,n,1,pos[x],pos[y],k); //则处理一下两节点之间的区间
}
ll sum(int x,int y){ //查询操作和修改是一样的……
ll ans=0;
while(top[x]!=top[y]){
if(deth[top[x]]<deth[top[y]]) swap(x,y);
ans+=query(1,n,1,pos[top[x]],pos[x]);
x=f[top[x]];
}
if(deth[x]>deth[y]) swap(x,y);
ans+=query(1,n,1,pos[x],pos[y]);
return ans;
}3 and 4 for the operation is easier. Because the sub-tree in the array is continuous, we know the size of each of them subtree, so a direct wave of tree line on it
update(1,n,1,pos[x],pos[x]+size[x]-1,y); //将以x为根节点的子树内所有节点值都加上z
query(1,n,1,pos[x],pos[x]+size[x]-1); //求以x为根节点的子树内所有节点值之和This, tree sectional really finished, I do not know Tell me what the public understand how much ......
Recommended topics
- Luogu [template] tree chain split (that is, we are talking about the example)
- HAOI2015 tree operation
- NOI2015 Package Manager
These are some of the bare title. Tree cross itself is not difficult to understand, but because the longer the code, it is easier wrong ...... and the whole is recursive, not good debugging ...... Therefore, more training ......
Reference blog
Tree chain subdivision principle and - \ (banananana \)
tree chain Detailed Split - \ (ChinHhh \)
tree chain Detailed Split - \ (Communist \)