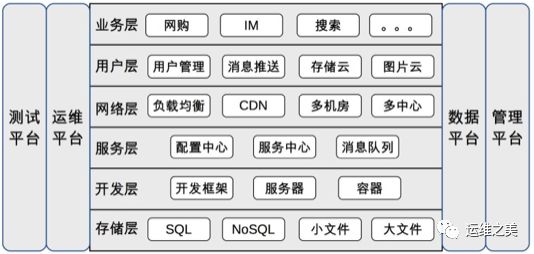
Internet standard technology architecture shown below, this pattern substantially covers most of the technical point of Internet technology companies, different companies only a slight difference in specific technology, but not out of the scope of this framework.
SQL storage layer technology
SQL that is, we usually refer to relational data. NoSQL fire for a while a few years ago, many people are understood to be completely abandoned NoSQL relational data, all using non-relational data. But after several years of testing, we found that the relationship data can not be completely abandoned, NoSQL is not No SQL, but Not Only SQL, NoSQL is the SQL that is complementary.
So the Internet industry must rely on relational data, taking into account Oracle is too expensive, they also need someone to maintain, under normal circumstances the Internet industry are using MySQL, PostgreSQL open source database such. The characteristics of such a database is open source and free, brought on by; but the drawback is the performance compared to commercial databases to be worse. With the development of Internet services, increasingly high performance requirements, will have to face a problem: splitting data into multiple database instances in order to meet the performance needs of the business (in fact, Oracle is the same, just a matter of time).
Split the database to meet the performance requirements, but brought the issue of complexity: how to split the data, how the data combination? The complexity of the problem is not easy to solve, if every business is to achieve again, repeat-create the wheel will result in wasted investment, reduce efficiency, business development, think fast almost up.
So popular Internet companies after the business approach is developed to a certain stage, this part will function independently as middleware, such as Baidu's DBProxy, Taobao TDDL. But this part of the high technical requirements, will be divided into sub-table library automation and platform to do, it is not an easy thing, it is generally the size of a large company would do its own. Small and medium companies recommend the use of open-source programs such as MySQL official recommendation of the MySQL Router, 360 open-source database middleware Atlas.
If the company's business continues to develop, we continued to expand, more and more SQL Server, if each business based on a unified database middleware independent deploy their SQL cluster, will lead the new complexity of the problem, in particular in:
- Database resource usage is not high, more waste.
- Separate maintenance of the SQL cluster, the maintenance cost of inputs is increasing.
Therefore, the strength of large companies this time usually built on SQL cluster SQL storage platform to provide transparent allocation of resources for business in the form of data backup, migration, disaster recovery, read and write separation, sub-library sub-table and other services such as Taobao UMP (Unified MySQL Platform) system.
NoSQL
First, the conventional SQL NoSQL on different data structures, such as a typical Memcache of key-value structure of the complex data structures Redis, MongoDB document data structure; secondly, without exception, will be NoSQL its performance as a major selling point. NoSQL of these two characteristics is well up for the lack of relational databases, NoSQL application therefore in the Internet industry is essentially the basis of the requirements.
Because NoSQL program itself provides general functionality of the cluster, for example Memcache consistency Hash clusters, Redis Cluster 3.0, so NoSQL easy at the beginning of the application, unlike SQL sub-library sub-table so complicated. The company generally will not consider at the beginning of the packaging NoSQL to store the platform, but if the company has developed rapidly, such as Memcache node when there are thousands or even thousands, it makes sense to NoSQL storage platform. The first is through a centrally managed storage platform can greatly enhance the efficiency of operation and maintenance; followed by storage platform can greatly enhance the efficiency of resource use, 2000 machines, if can improve the utilization of 10%, you can reduce the 200 machines, several hundred thousand dollars a year It saves out.
So, after NoSQL developed to a certain scale, usually in clusters on the basis of NoSQL again to achieve a unified storage platform, unified storage platform to achieve these main functions:
- Dynamic demand dynamic allocation of resources: for example, the same Memcache server, according to the memory usage, allocated to a plurality of service usage.
- Automated Resource Management: for example, just how much new business Memcache cache space applications on it, without paying attention to what specific Memcache server to provide services for themselves.
- Fault automated processing: for example, after a certain stage Memcache server hang, there is another one backup server to take over immediately Memcache cache requests, will not result in the loss of a lot of cache data.
Of course, to develop to this stage, it is generally large companies will do so, in short, if only dozens of NoSQL servers, storage platforms do not return; but if there are several thousand NoSQL servers, storage platforms can generate NoSQL great benefits.
Small files are stored
In addition to a relational business data, the Internet industry, there are a lot of data for display. For example, Taobao product images, product description; Facebook users picture; a microblog Sina Weibo and so on. These data have three typical characteristics: First, small data, generally below 1MB; the second is a huge number, Facebook in 2013 photos uploaded every day reached 350 million; the third is a huge traffic, Facebook traffic than a day 1000000000.
As the Internet industry basically every business will have a large number of small data, if each have their own business to consider how to design mass storage and mass access, efficiency will naturally be lower, repeat-create the wheel will be put to waste, so we should naturally be small file storage made uniform and non-business platform.
And SQL and NoSQL difference is small file storage does not necessarily require a large-scale company or business, basically think that in the initial stage of business you can consider doing a small unified file storage. Thanks to the development of a large and popular open-source movement data of recent years, a small package file storage platform is not too difficult to do on the basis of open-source programs. For example, HBase, Hadoop, Hypertable, FastDFS so small files that can be stored as the underlying platform, simply repackaging what these open source programs can be basically used.
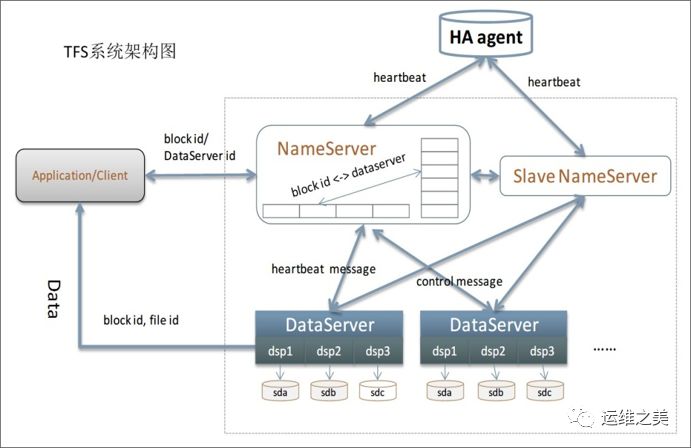
A typical small files stored there: Taobao TFS, Jingdong JFS, Facebook's Haystack.
The figure is Taobao TFS architecture:
Large file storage
Internet industry large files can be divided into two categories: one is the big data services, such as Youtube videos, movie website movies; the other is the massive log data, such as a variety of access log, operation log, track user logs. And the characteristics of small files on the contrary, a large number of small files file is not so much, but each file is large, several hundred MB, GB are common a few dozens of GB, a few TB is likely, therefore on storage and small files are very different, not directly to the storage system of small files used to store large files.
说到大文件,特别要提到Google和Yahoo,Google的3篇大数据论文(Bigtable/Map- Reduce/GFS)开启了一个大数据的时代,而Yahoo开源的Hadoop系列(HDFS、HBase等),基本上垄断了开源界的大数据处理。
对照Google的论文构建一套完整的大数据处理方案的难度和成本实在太高,而且开源方案现在也很成熟了,所以大数据存储和处理这块反而是最简单的,因为你没有太多选择,只能用这几个流行的开源方案,例如,Hadoop、HBase、Storm、Hive等。实力雄厚一些的大公司会基于这些开源方案,结合自己的业务特点,封装成大数据平台,例如淘宝的云梯系统、腾讯的TDW系统。
下面是Hadoop的生态圈:

开发层技术开发框架
互联网业务发展有一个特点:复杂度越来越高。复杂度增加的典型现象就是系统越来越多,不同的系统由不同的小组开发。如果每个小组用不同的开发框架和技术,则会带来很多问题,典型的问题有:
- 技术人员之间没有共同的技术语言,交流合作少。
- 每类技术都需要投入大量的人力和资源并熟练精通。
- 不同团队之间人员无法快速流动,人力资源不能高效的利用。
所以,互联网公司都会指定一个大的技术方向,然后使用统一的开发框架。例如,Java相关的开发框架SSH、SpringMVC、Play,Ruby的Ruby on Rails,PHP的ThinkPHP,Python的Django等。使用统一的开发框架能够解决上面提到的各种问题,大大提升组织和团队的开发效率。
对于框架的选择,有一个总的原则:优选成熟的框架,避免盲目追逐新技术!
为什么呢?
- 首先,成熟的框架资料文档齐备,各种坑基本上都有人踩过了,遇到问题很容易通过搜索来解决。
- 其次,成熟的框架受众更广,招聘时更加容易招到合适的人才。
- 第三,成熟的框架更加稳定,不会出现大的变动,适合长期发展。
Web服务器
开发框架只是负责完成业务功能的开发,真正能够运行起来给用户提供服务,还需要服务器配合。
独立开发一个成熟的Web服务器,成本非常高,况且业界又有那么多成熟的开源Web服务器,所以互联网行业基本上都是“拿来主义”,挑选一个流行的开源服务器即可。大一点的公司,可能会在开源服务器的基础上,结合自己的业务特点做二次开发,例如淘宝的Tengine,但一般公司基本上只需要将开源服务器摸透,优化一下参数,调整一下配置就差不多了。
选择一个服务器主要和开发语言相关,例如,Java的有Tomcat、JBoss、Resin等,PHP/Python的用Nginx,当然最保险的就是用Apache了,什么语言都支持。
你可能会担心Apache的性能之类的问题,其实不用过早担心这个,等到业务真的发展到Apache撑不住的时候再考虑切换也不迟,那时候你有的是钱,有的是人,有的是时间。
容器
容器是最近几年才开始火起来的,其中以Docker为代表,在BAT级别的公司已经有较多的应用。例如,腾讯万台规模的Docker应用实践、新浪微博红包的大规模Docker集群等。
传统的虚拟化技术是虚拟机,解决了跨平台的问题,但由于虚拟机太庞大,启动又慢,运行时太占资源,在互联网行业并没有大规模应用;而Docker的容器技术,虽然没有跨平台,但启动快,几乎不占资源,推出后立刻就火起来了,预计Docker类的容器技术将是技术发展的主流方向。
千万不要以为Docker只是一个虚拟化或者容器技术,它将在很大程度上改变目前的技术形势:
- 运维方式会发生革命性的变化:Docker启动快,几乎不占资源,随时启动和停止,基于Docker打造自动化运维、智能化运维将成为主流方式。
- 设计模式会发生本质上的变化:启动一个新的容器实例代价如此低,将鼓励设计思路朝“微服务”的方向发展。
例如,一个传统的网站包括登录注册、页面访问、搜索等功能,没有用容器的情况下,除非有特别大的访问量,否则这些功能开始时都是集成在一个系统里面的;有了容器技术后,一开始就可以将这些功能按照服务的方式设计,避免后续访问量增大时又要重构系统。
服务层技术
互联网业务的不断发展带来了复杂度的不断提升,业务系统也越来越多,系统间相互依赖程度加深。比如说为了完成A业务系统,可能需要B、C、D、E等十几个其他系统进行合作。从数学的角度进行评估,可以发现系统间的依赖是呈指数级增长的:3个系统相互关联的路径为3条,6个系统相互关联的路径为15条。
服务层的主要目标其实就是为了降低系统间相互关联的复杂度。
配置中心
故名思议,配置中心就是集中管理各个系统的配置。
当系统数量不多的时候,一般是各系统自己管理自己的配置,但系统数量多了以后,这样的处理方式会有问题:
- 某个功能上线时,需要多个系统配合一起上线,分散配置时,配置检查、沟通协调需要耗费较多时间。
- 处理线上问题时,需要多个系统配合查询相关信息,分散配置时,操作效率很低,沟通协调也需要耗费较多时间。
- 各系统自己管理配置时,一般是通过文本编辑的方式修改的,没有自动的校验机制,容易配置错误,而且很难发现。
例如,我曾经遇到将IP地址的数字0误敲成了键盘的字母O,肉眼非常难发现,但程序检查其实就很容易。
实现配置中心主要就是为了解决上面这些问题,将配置中心做成通用的系统的好处有:
- 集中配置多个系统,操作效率高。
- 所有配置都在一个集中的地方,检查方便,协作效率高。
- 配置中心可以实现程序化的规则检查,避免常见的错误。比如说检查最小值、最大值、是否IP地址、是否URL地址,都可以用正则表达式完成。
- 配置中心相当于备份了系统的配置,当某些情况下需要搭建新的环境时,能够快速搭建环境和恢复业务。
整机磁盘坏掉、机器主板坏掉……遇到这些不可恢复的故障时,基本上只能重新搭建新的环境。程序包肯定是已经有的,加上配置中心的配置,能够很快搭建新的运行环境,恢复业务。否则几十个配置文件重新一个个去Vim中修改,耗时很长,还很容易出错。
下面是配置中心简单的设计,其中通过“系统标识 + host + port”来标识唯一一个系统运行实例是常见的设计方法。

服务中心
当系统数量不多的时候,系统间的调用一般都是直接通过配置文件记录在各系统内部的,但当系统数量多了以后,这种方式就存在问题了。
比如说总共有10个系统依赖A系统的X接口,A系统实现了一个新接口Y,能够更好地提供原有X接口的功能,如果要让已有的10个系统都切换到Y接口,则这10个系统的几十上百台机器的配置都要修改,然后重启,可想而知这个效率是很低的。
除此以外,如果A系统总共有20台机器,现在其中5台出故障了,其他系统如果是通过域名访问A系统,则域名缓存失效前,还是可能访问到这5台故障机器的;如果其他系统通过IP访问A系统,那么A系统每次增加或者删除机器,其他所有10个系统的几十上百台机器都要同步修改,这样的协调工作量也是非常大的。
服务中心就是为了解决上面提到的跨系统依赖的“配置”和“调度”问题。
服务中心的实现一般来说有两种方式:服务名字系统和服务总线系统。
- 服务名字系统(Service Name System) 看到这个翻译,相信你会立刻联想到DNS,即Domain Name System。没错,两者的性质是基本类似的。DNS的作用将域名解析为IP地址,主要原因是我们记不住太多的数字IP,域名就容易记住。服务名字系统是为了将Service名称解析为“host + port + 接口名称”,但是和DNS一样,真正发起请求的还是请求方。基本的设计如下:

- 服务总线系统(Service Bus System) 看到这个翻译,相信你可能立刻联想到计算机的总线。没错,两者的本质也是基本类似的。 相比服务名字系统,服务总线系统更进一步了:由总线系统完成调用,服务请求方都不需要直接和服务提供方交互了。 基本的设计如下:
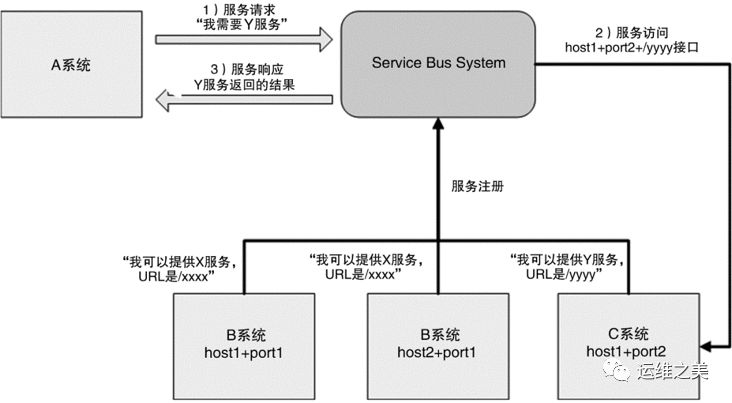
“服务名字系统”和“服务总线系统”简单对比如下表所示。

消息队列
互联网业务的一个特点是“快”,这就要求很多业务处理采用异步的方式。例如,大V发布一条微博后,系统需要发消息给关注的用户,我们不可能等到所有消息都发送给关注用户后再告诉大V说微博发布成功了,只能先让大V发布微博,然后再发消息给关注用户。
传统的异步通知方式是由消息生产者直接调用消息消费者提供的接口进行通知的,但当业务变得庞大,子系统数量增多时,这样做会导致系统间交互非常复杂和难以管理,因为系统间互相依赖和调用,整个系统的结构就像一张蜘蛛网,如下图所示。

消息队列就是为了实现这种跨系统异步通知的中间件系统。消息队列既可以“一对一”通知,也可以“一对多”广播。以微博为例,可以清晰地看到异步通知的实现和作用,如下图所示。
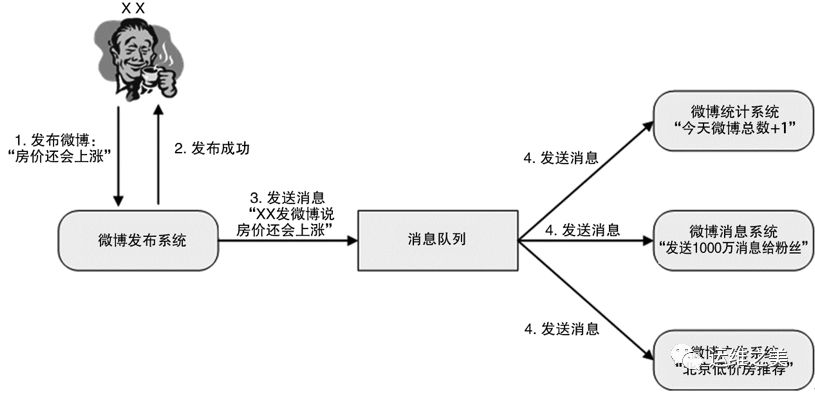
对比前面的蜘蛛网架构,可以清晰地看出引入消息队列系统后的效果:
- 整体结构从网状结构变为线性结构,结构清晰。
- 消息生产和消息消费解耦,实现简单。
- 增加新的消息消费者,消息生产者完全不需要任何改动,扩展方便。
- 消息队列系统可以做高可用、高性能,避免各业务子系统各自独立做一套,减轻工作量。
- 业务子系统只需要聚焦业务即可,实现简单。
消息队列系统基本功能的实现比较简单,但要做到高性能、高可用、消息时序性、消息事务性则比较难。业界已经有很多成熟的开源实现方案,如果要求不高,基本上拿来用即可,例如,RocketMQ、Kafka、ActiveMQ等。但如果业务对消息的可靠性、时序、事务性要求较高时,则要深入研究这些开源方案,否则很容易踩坑。
开源的用起来方便,但要改就很麻烦了。由于其相对比较简单,很多公司也会花费人力和时间重复造一个轮子,这样也有好处,因为可以根据自己的业务特点做快速的适配开发。
网络层技术
除了复杂度,互联网业务发展的另外两个关键特点是“高性能”和“高可用”。通常情况下,我们在设计高可用和高性能系统的时候,主要关注点在系统本身的复杂度,然后通过各种手段来实现高可用和高性能的要求。但是当我们站在一个公司的的角度来思考架构的时候,单个系统的高可用和高性能并不等于整体业务的高可用和高性能,互联网业务的高性能和高可用需要从更高的角度去设计,这个高点就是“网络”。这里的网络强调的是站在网络层的角度整体设计架构,而不是某个具体网络的搭建。
负载均衡
顾名思议,负载均衡就是将请求均衡地分配到多个系统上。使用负载均衡的原因也很简单:每个系统的处理能力是有限的,为了应对大容量的访问,必须使用多个系统。例如,一台32核64GB内存的机器,性能测试数据显示每秒处理Hello World的HTTP请求不超过2万,实际业务机器处理HTTP请求每秒可能才几百QPS,而互联网业务并发超过1万是比较常见的,遇到双十一、过年发红包这些极端场景,每秒可以达到几十万的请求。
DNS
DNS是最简单也是最常见的负载均衡方式,一般用来实现地理级别的均衡。例如,北方的用户访问北京的机房,南方的用户访问广州的机房。一般不会使用DNS来做机器级别的负载均衡,因为太耗费IP资源了。例如,百度搜索可能要10000台以上机器,不可能将这么多机器全部配置公网IP,然后用DNS来做负载均衡。
DNS负载均衡的优点是通用(全球通用)、成本低(申请域名,注册DNS即可),但缺点也比较明显,主要体现在:
- DNS缓存的时间比较长,即使将某台业务机器从DNS服务器上删除,由于缓存的原因,还是有很多用户会继续访问已经被删除的机器。
- DNS不够灵活。DNS不能感知后端服务器的状态,只能根据配置策略进行负载均衡,无法做到更加灵活的负载均衡策略。比如说某台机器的配置比其他机器要好很多,理论上来说应该多分配一些请求给它,但DNS无法做到这一点。
所以对于时延和故障敏感的业务,有实力的公司可能会尝试实现HTTP-DNS的功能,即使用HTTP协议实现一个私有的DNS系统。HTTP-DNS主要应用在通过App提供服务的业务上,因为在App端可以实现灵活的服务器访问策略,如果是Web业务,实现起来就比较麻烦一些,因为URL的解析是由浏览器来完成的,只有Java的访问可以像App那样实现比较灵活的控制。
HTTP-DNS的优缺点有:
- 灵活:HTTP-DNS可以根据业务需求灵活的设置各种策略。
- 可控:HTTP-DNS是自己开发的系统,IP更新、策略更新等无需依赖外部服务商。
- 及时:HTTP-DNS不受传统DNS缓存的影响,可以非常快地更新数据、隔离故障。
- 开发成本高:没有通用的解决方案,需要自己开发。
- 侵入性:需要App基于HTTP-DNS进行改造。
Nginx 、LVS 、F5
DNS用于实现地理级别的负载均衡,而Nginx、LVS、F5用于同一地点内机器级别的负载均衡。其中Nginx是软件的7层负载均衡,LVS是内核的4层负载均衡,F5是硬件的4层负载均衡。
软件和硬件的区别就在于性能,硬件远远高于软件,Ngxin的性能是万级,一般的Linux服务器上装个Nginx大概能到5万/秒;LVS的性能是十万级,没有具体测试过,据说可达到80万/秒;F5性能是百万级,从200万/秒到800万/秒都有。硬件虽然性能高,但是单台硬件的成本也很高,一台最便宜的F5都是几十万,但是如果按照同等请求量级来计算成本的话,实际上硬件负载均衡设备可能会更便宜,例如假设每秒处理100万请求,用一台F5就够了,但用Nginx,可能要20台,这样折算下来用F5的成本反而低。因此通常情况下,如果性能要求不高,可以用软件负载均衡;如果性能要求很高,推荐用硬件负载均衡。
4层和7层的区别就在于协议和灵活性。Nginx支持HTTP、E-mail协议,而LVS和F5是4层负载均衡,和协议无关,几乎所有应用都可以做,例如聊天、数据库等。
目前很多云服务商都已经提供了负载均衡的产品,例如阿里云的SLB、UCloud的ULB等,中小公司直接购买即可。
CDN
CDN是为了解决用户网络访问时的“最后一公里”效应,本质上是一种“以空间换时间”的加速策略,即将内容缓存在离用户最近的地方,用户访问的是缓存的内容,而不是站点实时的内容。
下面是简单的CDN请求流程示意图:
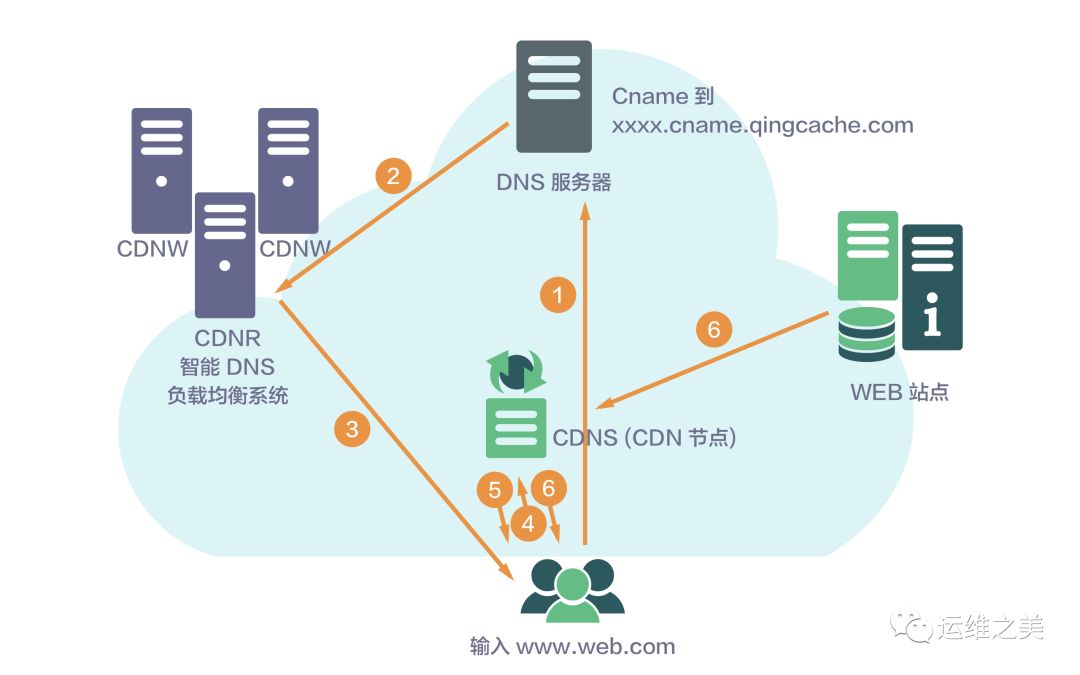
CDN经过多年的发展,已经变成了一个很庞大的体系:分布式存储、全局负载均衡、网络重定向、流量控制等都属于CDN的范畴,尤其是在视频、直播等领域,如果没有CDN,用户是不可能实现流畅观看内容的。
幸运的是,大部分程序员和架构师都不太需要深入理解CDN的细节,因为CDN作为网络的基础服务,独立搭建的成本巨大,很少有公司自己设计和搭建CDN系统,从CDN服务商购买CDN服务即可,目前有专门的CDN服务商,例如网宿和蓝汛;也有云计算厂家提供CDN服务,例如阿里云和腾讯云都提供CDN的服务。
多机房
从架构上来说,单机房就是一个全局的网络单点,在发生比较大的故障或者灾害时,单机房难以保证业务的高可用。例如,停电、机房网络中断、地震、水灾等都有可能导致一个机房完全瘫痪。
多机房设计最核心的因素就是如何处理时延带来的影响,常见的策略有:
- 同城多机房 同一个城市多个机房,距离不会太远,可以投入重金,搭建私有的高速网络,基本上能够做到和同机房一样的效果。 这种方式对业务影响很小,但投入较大,如果不是大公司,一般是承受不起的;而且遇到极端的地震、水灾等自然灾害,同城多机房也是有很大风险的。
- 跨城多机房 在不同的城市搭建多个机房,机房间通过网络进行数据复制(例如,MySQL主备复制),但由于跨城网络时延的问题,业务上需要做一定的妥协和兼容,比如不需要数据的实时强一致性,只是保证最终一致性。 例如,微博类产品,B用户关注了A用户,A用户在北京机房发布了一条微博,B在广州机房不需要立刻看到A用户发的微博,等10分钟看到也可以。 这种方式实现简单,但和业务有很强的相关性,微博可以这样做,支付宝的转账业务就不能这样做,因为用户余额是强一致性的。
- 跨国多机房 和跨城多机房类似,只是地理上分布更远,时延更大。由于时延太大和用户跨国访问实在太慢,跨国多机房一般仅用于备份和服务本国用户。
多中心
多中心必须以多机房为前提,但从设计的角度来看,多中心相比多机房是本质上的飞越,难度也高出一个等级。
简单来说,多机房的主要目标是灾备,当机房故障时,可以比较快速地将业务切换到另外一个机房,这种切换操作允许一定时间的中断(例如,10分钟、1个小时),而且业务也可能有损失(例如,某些未同步的数据不能马上恢复,或者要等几天才恢复,甚至永远都不能恢复了)。因此相比多机房来说,多中心的要求就高多了,要求每个中心都同时对外提供服务,且业务能够自动在多中心之间切换,故障后不需人工干预或者很少的人工干预就能自动恢复。
多中心设计的关键就在于“数据一致性”和“数据事务性”如何保证,这两个难点都和业务紧密相关,目前没有很成熟的且通用的解决方案,需要基于业务的特性进行详细的分析和设计。以淘宝为例,淘宝对外宣称自己是多中心的,但是在实际设计过程中,商品浏览的多中心方案、订单的多中心方案、支付的多中心方案都需要独立设计和实现。
正因为多中心设计的复杂性,不一定所有业务都能实现多中心,目前国内的银行、支付宝这类系统就没有完全实现多中心,不然也不会出现挖掘机一铲子下去,支付宝中断4小时的故障。
用户层技术用户管理
互联网业务的一个典型特征就是通过互联网将众多分散的用户连接起来,因此用户管理是互联网业务必不可少的一部分。
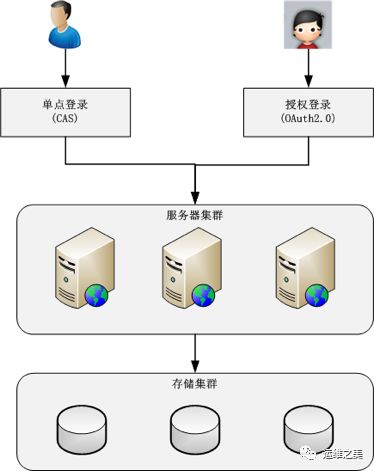
稍微大一点的互联网业务,肯定会涉及多个子系统,这些子系统不可能每个都管理这么庞大的用户,由此引申出用户管理的第一个目标:单点登录(SSO),又叫统一登录。单点登录的技术实现手段较多,例如cookie、JSONP、token等,目前最成熟的开源单点登录方案当属CAS,其架构如下

除此之外,当业务做大成为了平台后,开放成为了促进业务进一步发展的手段,需要允许第三方应用接入,由此引申出用户管理的第二个目标:授权登录。现在最流行的授权登录就是OAuth 2.0协议,基本上已经成为了事实上的标准,如果要做开放平台,则最好用这个协议,私有协议漏洞多,第三方接入也麻烦。
用户管理系统面临的主要问题是用户数巨大,一般至少千万级,QQ、微信、支付宝这种巨无霸应用都是亿级用户。不过也不要被这个数据给吓倒了,用户管理虽然数据量巨大,但实现起来并不难,原因是什么呢? 因为用户数据量虽然大,但是不同用户之间没有太强的业务关联,A用户登录和B用户登录基本没有关系。因此虽然数据量巨大,但我们用一个简单的负载均衡架构就能轻松应对。
用户管理的基本架构如下:
消息推送
消息推送根据不同的途径,分为短信、邮件、站内信、App推送。除了App,不同的途径基本上调用不同的API即可完成,技术上没有什么难度。例如,短信需要依赖运营商的短信接口,邮件需要依赖邮件服务商的邮件接口,站内信是系统提供的消息通知功能。
App目前主要分为iOS和Android推送,iOS系统比较规范和封闭,基本上只能使用苹果的APNS;但Android就不一样了,在国外,用GCM和APNS差别不大;但是在国内,情况就复杂多了:首先是GCM不能用;其次是各个手机厂商都有自己的定制的Android,消息推送实现也不完全一样。因此Android的消息推送就五花八门了,大部分有实力的大厂,都会自己实现一套消息推送机制,例如阿里云移动推送、腾讯信鸽推送、百度云推送;也有第三方公司提供商业推送服务,例如友盟推送、极光推送等。
通常情况下,对于中小公司,如果不涉及敏感数据,Android系统上推荐使用第三方推送服务,因为毕竟是专业做推送服务的,消息到达率是有一定保证的。
如果涉及敏感数据,需要自己实现消息推送,这时就有一定的技术挑战了。消息推送主要包含3个功能:设备管理(唯一标识、注册、注销)、连接管理和消息管理,技术上面临的主要挑战有:
- 海量设备和用户管理 消息推送的设备数量众多,存储和管理这些设备是比较复杂的;同时,为了针对不同用户进行不同的业务推广,还需要收集用户的一些信息,简单来说就是将用户和设备关联起来,需要提取用户特征对用户进行分类或者打标签等。
- 连接保活 要想推送消息必须有连接通道,但是应用又不可能一直在前台运行,大部分设备为了省电省流量等原因都会限制应用后台运行,限制应用后台运行后连接通道可能就被中断了,导致消息无法及时的送达。连接保活是整个消息推送设计中细节和黑科技最多的地方,例如应用互相拉起、找手机厂商开白名单等。
- 消息管理 实际业务运营过程中,并不是每个消息都需要发送给每个用户,而是可能根据用户的特征,选择一些用户进行消息推送。由于用户特征变化很大,各种排列组合都有可能,将消息推送给哪些用户这部分的逻辑要设计得非常灵活,才能支撑花样繁多的业务需求,具体的设计方案可以采取规则引擎之类的微内核架构技术。
存储云、图片云
互联网业务场景中,用户会上传多种类型的文件数据,例如微信用户发朋友圈时上传图片,微博用户发微博时上传图片、视频,优酷用户上传视频,淘宝卖家上传商品图片等,这些文件具备几个典型特点:
- 数据量大:用户基数大,用户上传行为频繁,例如2016年的时候微信朋友圈每天上传图片就达到了10亿张。
- 文件体积小:大部分图片是几百KB到几MB,短视频播放时间也是在几分钟内。
- 访问有时效性:大部分文件是刚上传的时候访问最多,随着时间的推移访问量越来越小。
为了满足用户的文件上传和存储需求,需要对用户提供文件存储和访问功能,这里就需要用到前面介绍“存储层”技术时提到的“小文件存储”技术。简单来说,存储云和图片云通常的实现都是“CDN + 小文件存储”,现在有了“云”之后,除非BAT级别,一般不建议自己再重复造轮子了,直接买云服务可能是最快也是最经济的方式。
既然存储云和图片云都是基于“CDN + 小文件存储”的技术,为何不统一一套系统,而将其拆分为两个系统呢?这是因为“图片”业务的复杂性导致的,普通的文件基本上提供存储和访问就够了,而图片涉及的业务会更多,包括裁剪、压缩、美化、审核、水印等处理,因此通常情况下图片云会拆分为独立的系统对用户提供服务。
业务层技术
互联网的业务千差万别,不同的业务分解下来有不同的系统,所以业务层没有办法提炼一些公共的系统或者组件。抛开业务上的差异,各个互联网业务发展最终面临的问题都是类似的:业务复杂度越来越高。也就是说,业务层面对的主要技术挑战是“复杂度”。
复杂度越来越高的一个主要原因就是系统越来越庞大,业务越来越多。幸运的是,面对业务层的技术挑战,我们有一把“屠龙宝刀”,不管什么业务难题,用上“屠龙宝刀”问题都能迎刃而解。这把“屠龙宝刀”就是“拆”,化整为零、分而治之,将整体复杂性分散到多个子业务或者子系统里面去。具体拆的方式你可以查看专栏前面可扩展架构模式部分的分层架构、微服务、微内核等。
以一个简单的电商系统为例,如下图所示。

我这个模拟的电商系统经历了3个发展阶段:
- 第一阶段:所有功能都在1个系统里面。
- 第二阶段:将商品和订单拆分到2个子系统里面。
- 第三阶段:商品子系统和订单子系统分别拆分成了更小的6个子系统。
上面只是个样例,实际上随着业务的发展,子系统会越来越多,据说淘宝内部大大小小的已经有成百上千的子系统了。
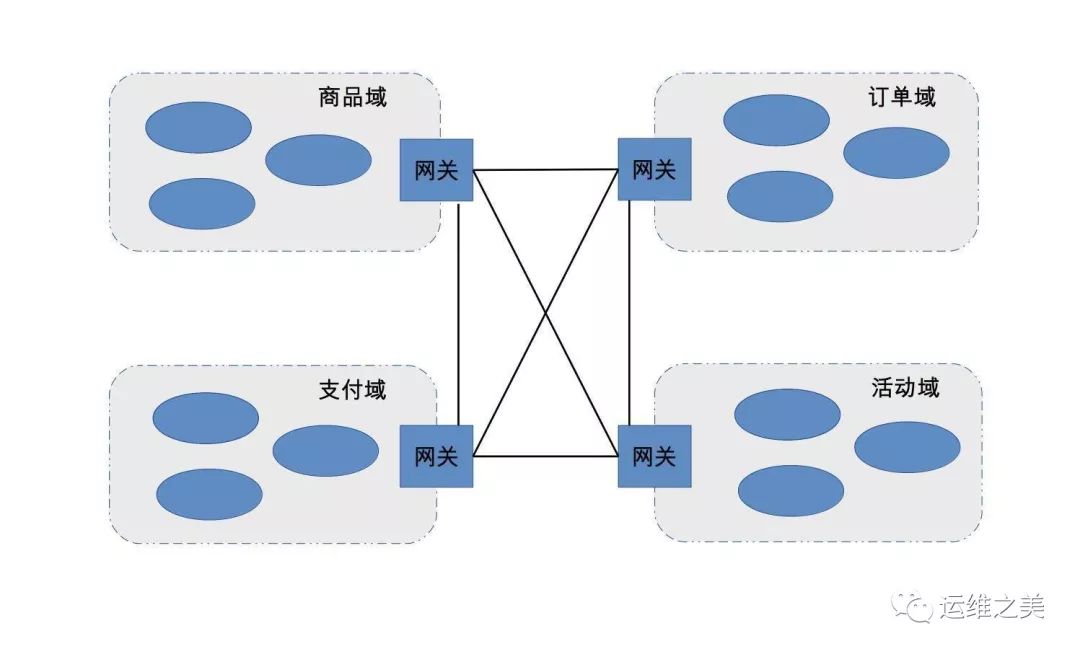
随着子系统数量越来越多,如果达到几百上千,另外一个复杂度问题又会凸显出来:子系统数量太多,已经没有人能够说清楚业务的调用流程了,出了问题排查也会特别复杂。此时应该怎么处理呢,总不可能又将子系统合成大系统吧?最终答案还是“合”,正所谓“合久必分、分久必合”,但合的方式不一样,此时采取的“合”的方式是按照“高内聚、低耦合”的原则,将职责关联比较强的子系统合成一个虚拟业务域,然后通过网关对外统一呈现,类似于设计模式中的Facade模式。同样以电商为样例,采用虚拟业务域后,其架构如下:
平台技术
当业务规模比较小、系统复杂度不高时,运维、测试、数据分析、管理等支撑功能主要由各系统或者团队独立完成。随着业务规模越来越大,系统复杂度越来越高,子系统数量越来越多,如果继续采取各自为政的方式来实现这些支撑功能,会发现重复工作非常多。因此我们自然而然就会想到将这些支撑功能做成平台,避免重复造轮子,减少不规范带来的沟通和协作成本。
运维平台
运维平台核心的职责分为四大块:配置、部署、监控、应急,每个职责对应系统生命周期的一个阶段,如下图所示。
- 配置:主要负责资源的管理。例如,机器管理、IP地址管理、虚拟机管理等。
- 部署:主要负责将系统发布到线上。例如,包管理、灰度发布管理、回滚等。
- 监控:主要负责收集系统上线运行后的相关数据并进行监控,以便及时发现问题。
- 应急:主要负责系统出故障后的处理。例如,停止程序、下线故障机器、切换IP等。
运维平台的核心设计要素是“四化”:标准化、平台化、自动化、可视化。
- 标准化 需要制定运维标准,规范配置管理、部署流程、监控指标、应急能力等,各系统按照运维标准来实现,避免不同的系统不同的处理方式。标准化是运维平台的基础,没有标准化就没有运维平台。 如果某个系统就是无法改造自己来满足运维标准,那该怎么办呢?常见的做法是不改造系统,由中间方来完成规范适配。例如,某个系统对外提供了RESTful接口的方式来查询当前的性能指标,而运维标准是性能数据通过日志定时上报,那么就可以写一个定时程序访问RESTful接口获取性能数据,然后转换为日志上报到运维平台。
- 平台化 传统的手工运维方式需要投入大量人力,效率低,容易出错,因此需要在运维标准化的基础上,将运维的相关操作都集成到运维平台中,通过运维平台来完成运维工作。 运维平台的好处有:
- 可以将运维标准固化到平台中,无须运维人员死记硬背运维标准。
- 运维平台提供简单方便的操作,相比之下人工操作低效且容易出错。
- 运维平台是可复用的,一套运维平台可以支撑几百上千个业务系统。
- 自动化 传统手工运维方式效率低下的一个主要原因就是要执行大量重复的操作,运维平台可以将这些重复操作固化下来,由系统自动完成。 例如,一次手工部署需要登录机器、上传包、解压包、备份旧系统、覆盖旧系统、启动新系统,这个过程中需要执行大量的重复或者类似的操作。有了运维平台后,平台需要提供自动化的能力,完成上述操作,部署人员只需要在最开始单击“开始部署”按钮,系统部署完成后通知部署人员即可。 类似的还有监控,有了运维平台后,运维平台可以实时收集数据并进行初步分析,当发现数据异常时自动发出告警,无须运维人员盯着数据看,或者写一大堆“grep + awk + sed”来分析日志才能发现问题。
- 可视化 运维平台有非常多的数据,如果全部通过人工去查询数据再来判断,则效率很低。尤其是在故障应急时,时间就是生命,处理问题都是争分夺秒,能减少1分钟的时间就可能挽回几十万元的损失,可视化的主要目的就是为了提升数据查看效率。 可视化的原理和汽车仪表盘类似,如果只是一连串的数字显示在屏幕上,相信大部分人一看到一连串的数字,第一感觉是眼花,而且也很难将数据与具体的情况联系起来。而有了仪表盘后,通过仪表盘的指针偏离幅度及指针指向的区域颜色,能够一目了然地看出当前的状态是低速、中速还是高速。 可视化相比简单的数据罗列,具备下面这些优点:
- 能够直观地看到数据的相关属性,例如,汽车仪表盘中的数据最小值是0,最大是100,单位是MPH。
- 能够将数据的含义展示出来,例如汽车仪表盘中不同速度的颜色指示。
- 能够将关联数据整合一起展示,例如汽车仪表盘的速度和里程。
测试平台
测试平台核心的职责当然就是测试了,包括单元测试、集成测试、接口测试、性能测试等,都可以在测试平台来完成。
测试平台的核心目的是提升测试效率,从而提升产品质量,其设计关键就是自动化。传统的测试方式是测试人员手工执行测试用例,测试效率低,重复的工作多。通过测试平台提供的自动化能力,测试用例能够重复执行,无须人工参与,大大提升了测试效率。
为了达到“自动化”的目标,测试平台的基本架构如下图所示。
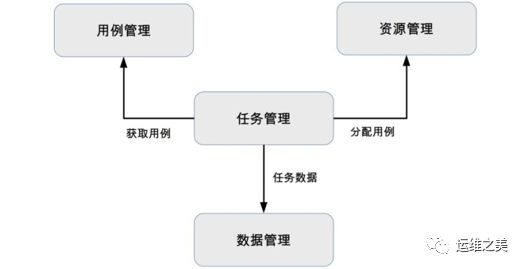
- 用例管理 测试自动化的主要手段就是通过脚本或者代码来进行测试,例如单元测试用例是代码、接口测试用例可以用Python来写、可靠性测试用例可以用Shell来写。为了能够重复执行这些测试用例,测试平台需要将用例管理起来,管理的维度包括业务、系统、测试类型、用例代码。例如,网购业务的订单系统的接口测试用例。
- 资源管理 测试用例要放到具体的运行环境中才能真正执行,运行环境包括硬件(服务器、手机、平板电脑等)、软件(操作系统、数据库、Java虚拟机等)、业务系统(被测试的系统)。 除了性能测试,一般的自动化测试对性能要求不高,所以为了提升资源利用率,大部分的测试平台都会使用虚拟技术来充分利用硬件资源,如虚拟机、Docker等技术。
- 任务管理 任务管理的主要职责是将测试用例分配到具体的资源上执行,跟踪任务的执行情况。任务管理是测试平台设计的核心,它将测试平台的各个部分串联起来从而完成自动化测试。
- 数据管理 测试任务执行完成后,需要记录各种相关的数据(例如,执行时间、执行结果、用例执行期间的CPU、内存占用情况等),这些数据具备下面这些作用:
- 展现当前用例的执行情况。
- 作为历史数据,方便后续的测试与历史数据进行对比,从而发现明显的变化趋势。例如,某个版本后单元测试覆盖率从90%下降到70%。
- 作为大数据的一部分,可以基于测试的任务数据进行一些数据挖掘。例如,某个业务一年执行了10000个用例测试,另外一个业务只执行了1000个用例测试,两个业务规模和复杂度差不多,为何差异这么大?
数据平台
数据平台的核心职责主要包括三部分:数据管理、数据分析和数据应用。每一部分又包含更多的细分领域,详细的数据平台架构如下图所示。

- 数据管理 数据管理包含数据采集、数据存储、数据访问和数据安全四个核心职责,是数据平台的基础功能。
- 数据采集:从业务系统搜集各类数据。例如,日志、用户行为、业务数据等,将这些数据传送到数据平台。
- 数据存储:将从业务系统采集的数据存储到数据平台,用于后续数据分析。
- 数据访问:负责对外提供各种协议用于读写数据。例如,SQL、Hive、Key-Value等读写协议。
- 数据安全:通常情况下数据平台都是多个业务共享的,部分业务敏感数据需要加以保护,防止被其他业务读取甚至修改,因此需要设计数据安全策略来保护数据。
- 数据分析 数据分析包括数据统计、数据挖掘、机器学习、深度学习等几个细分领域。
- 数据统计:根据原始数据统计出相关的总览数据。例如,PV、UV、交易额等。
- 数据挖掘:数据挖掘这个概念本身含义可以很广,为了与机器学习和深度学习区分开,这里的数据挖掘主要是指传统的数据挖掘方式。例如,有经验的数据分析人员基于数据仓库构建一系列规则来对数据进行分析从而发现一些隐含的规律、现象、问题等,经典的数据挖掘案例就是沃尔玛的啤酒与尿布的关联关系的发现。
- 机器学习、深度学习:机器学习和深度学习属于数据挖掘的一种具体实现方式,由于其实现方式与传统的数据挖掘方式差异较大,因此数据平台在实现机器学习和深度学习时,需要针对机器学习和深度学习独立进行设计。
- 数据应用 数据应用很广泛,既包括在线业务,也包括离线业务。例如,推荐、广告等属于在线应用,报表、欺诈检测、异常检测等属于离线应用。 数据应用能够发挥价值的前提是需要有“大数据”,只有当数据的规模达到一定程度,基于数据的分析、挖掘才能发现有价值的规律、现象、问题等。如果数据没有达到一定规模,通常情况下做好数据统计就足够了,尤其是很多初创企业,无须一开始就参考BAT来构建自己的数据平台。
管理平台
管理平台的核心职责就是权限管理,无论是业务系统(例如,淘宝网)、中间件系统(例如,消息队列Kafka),还是平台系统(例如,运维平台),都需要进行管理。如果每个系统都自己来实现权限管理,效率太低,重复工作很多,因此需要统一的管理平台来管理所有的系统的权限。
权限管理主要分为两部分:身份认证、权限控制,其基本架构如下图所示。
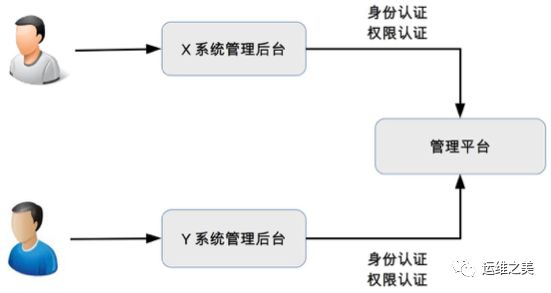
1.身份认证
确定当前的操作人员身份,防止非法人员进入系统。例如,不允许匿名用户进入系统。为了避免每个系统都自己来管理用户,通常情况下都会使用企业账号来做统一认证和登录。
2.权限控制
根据操作人员的身份确定操作权限,防止未经授权的人员进行操作。例如,不允许研发人员进入财务系统查看别人的工资。