Because the demand for data to be operated within the hive work, so look at the hive knowledge database, to prevent yourself delete library on foot
hive data types
Integer:
TINYINT micro-byte integer 1
Small Integer SMALLINT 2 bytes
INT 4 bytes Integer
BIGINT 8 bytes
Boolean:
BOOLEAN TRUE/FALSE
Float:
Single-precision FLOAT
DOUBLE double
String type:
No set length STRING
Complex data type:
ARRAY ordered set type field, the field must be the same
MAP an unordered set of key-value pairs
STUCTS a named set of fields
1 CREATE TABLE complex( 2 3 col1 ARRAY< INT>, 4 5 col2 MAP< STRING,INT>, 6 7 col3 STRUCT< a:STRING,b:INT,c:DOUBLE> 8 9 )
hive storage type
There are two main stores data hive in columns and rows of memory storage
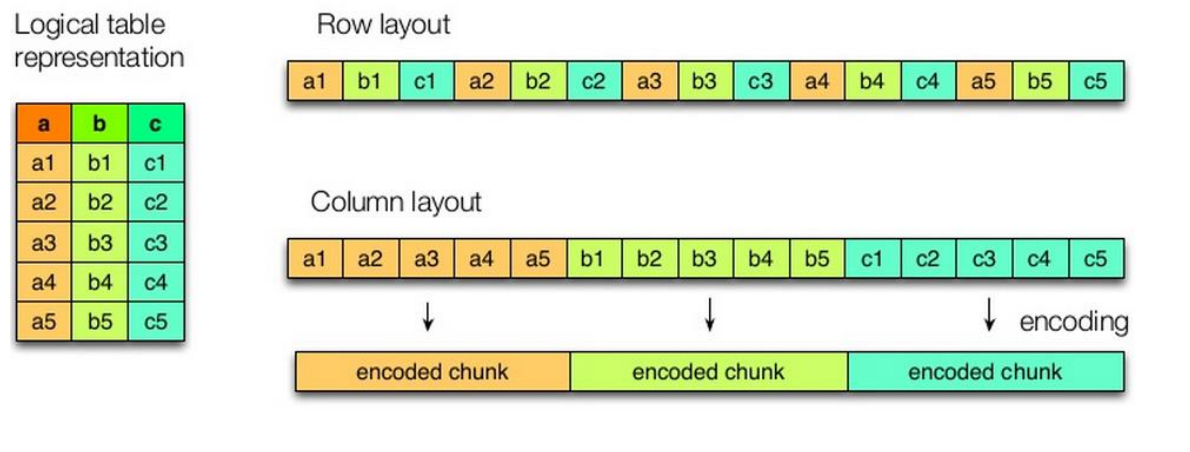
hive common storage format
1.textfile
The default format for the row storage format
2.ORCFile
hive / spark support this storage format, which stores data in the embodiment is the use of block rows, each block is stored in columns, wherein each block is stored an index. It characterized by very high data compression ratio
3.Parquet
Parquet also a storage line, while having good compression properties; also can reduce the number of table scans and deserialization time.
sql how to define the storage format
CREATE TABLE IF NOT EXIST testname( .......... )STORED AS PARQUET
Reference https://www.jianshu.com/p/694f044d1c34