There is a very famous abroad condition with tutorials airport is in English, reads: http://blog.echen.me/2012/01/03/introduction-to-conditional-random-fields/
A little easier to understand introductory tutorial text: http://www.jianshu.com/p/55755fc649b1
Suppose you have photos of many different times of day Xiao Ming classmates, childhood tora pants to get up to take your pants off to sleep each time period are (Xiao Ming is a photograph of control!). The task now is to classify these pictures. For instance, some photos are eating, then give it a label marked with a meal; some photo shoot while running, it is marked with a label run; some photographs were taken during the meeting, the meeting would be marked with a label. The question is, how are you going to do it?
A simple and intuitive way is, regardless of the time between the order of the photographs, think of ways to train a multi-classifier. Some lay the tag is to use the photos as training data to train a model directly classified according to the characteristics of the photo. For example, if the photo was shot at 6:00 in the morning, and the screen is dark, then give it a label marked with sleep; if there are cars on the photo, then give it a label marked car.
This feasible?
At first glance you can! But in fact, because we ignored the time order between these photos this important information, we will classifier defects. For example, if there is a photograph Zhang Xiaoming mouth closed, and how classification? Obviously it is difficult to directly determine the need to refer to the previous shut up pictures, if the previous photograph shows Xiaoming at dinner, then this is likely to be shut up photos of Xiao Ming ready to swallow chewing food, you can eat it marked the label; if the previous photos show Xiaoming singing, then this is likely to be shut up photos of Xiao Ming singing moment of capture, you can sing it marked label.
So, in order for us classifier into account to have a better performance, when classified as a picture, we must be adjacent to its label information of the photo. That - that is, Conditional Random Fields (CRF) showcases the place!
CRF and speech tagging
What is POS tagging problem?
Very simple, it is to give each word in a sentence note speech. For example, this sentence: "Bob drank coffee at Starbucks", stated after the speech of each word is this: "Bob (noun) drank (verb) coffee (noun) at (preposition) Starbucks (noun)."
Now, on with CRFs to solve this problem.
With the words above as an example, there are five words, we will :( nouns, verbs, nouns, prepositions, nouns) as there are many marked a sequence, known as l, optional annotation sequence, such as l can look like this: (nouns, verbs, verbs, prepositions, nouns), we want to mark in the sequence are so many options, the most likely pick a label us as this sentence.
How to judge a marked sequence fly do not fly it?
As far as we mark two sequences shown above, the second is obviously not as good as the first tricky, because it is the second and third words are marked became a verb, verb take verb, which is usually in a sentence It is illogical.
If we give each scoring sequence annotation, the higher the score the more reliable sequence annotation on behalf of the least we can say, all marked appeared verb or a verb annotation sequence, to give it a negative score! !
The above mentioned verb or a verb is a characteristic function, we can define a set of characteristic function, use this feature to function as a set of scoring sequence annotation, and accordingly select the most likely sequence annotation. That is, each feature function can be used to mark a sequence of scores, the collection features all the functions on the same label sequence of scores together, marked the final score is this sequence of values.
Characteristic function of CRF
Now, we formally define what is the characteristic function of the CRF, the so-called characteristic function, is one such function which takes four parameters:
S sentence (what we want speech marked sentence)
i, s sentence to represent the i-th word
l_i, said to score mark sequence to the i-word speech marked
l_i-1, said to score mark sequence to i-1 of the words of speech tagging
its output value to be 0 or 1, 0 indicates the sequence denoted score does not meet this feature, a score represents the label to meet this sequence features.
The definition of a good set of features function, we give each feature function f_j assigned a weight λ_j. Now, as long as there is a sentence s, there is a label sequence l, we can use the feature set of functions previously defined by l to score.
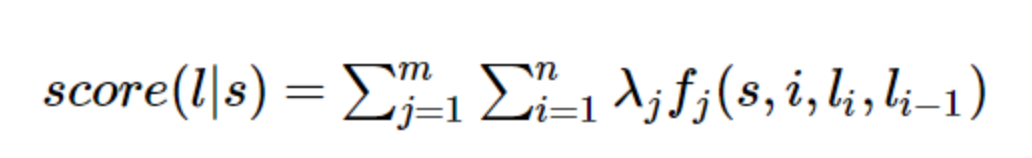
There are two summation formula, to find out the summation for each feature and function f_j scores, and which is used to find the sum of words in the sentence position of each of the eigenvalues.
This index and standardized scores, we can obtain a probability value denoted l sequence p (l | s), as follows:

in conclusion:
To build a conditional random field, we first define a feature set of functions, wherein each function are based on the entire sentence s, i the current position, positions i and i-1 input label. Then given a weight function for each feature weight, and a label for each sequence L, of the weighted sum of all the characteristic function, if necessary, can be converted to a value of the summed probability value.
Article link: https: //www.jianshu.com/p/8cecc901fa3b