First, the section reviews
On one, I to question ksoftirqd CPU usage rate of, for example, you study together with the analysis of kernel threads when high CPU use. Briefly recap.
When it comes to kernel threads resource usage anomalies, many commonly used process-level performance tools, and can not be applied directly to the kernel threads. At this time, we can use the kernel comes with perf to observe their behavior, identify hot spots function, further positioning performance bottle
neck. However, the summary report produced perf is not intuitive, so I usually recommend using flame plans to assist the investigation.
In fact, the use of the system kernel threads perf analysis, kernel threads still is still operating normally in, so this method is also called dynamic tracking technologies.
Dynamic tracking technology, through the probe mechanism to collect information kernel or run the application, you can not modify the code so that the kernel and applications, you get a wealth of information to help you analyze, locate the problem you want to troubleshoot.
In the past, when troubleshooting and debugging performance issues, we often need to set up a series of breakpoints for an application (such as using GDB), and then manually or script (such as GDB Python extensions) way of analysis of these breakpoint application
state sequence. Alternatively, adding a series of logs, looking for clues from the log.
However, the break will often interrupt the normal operation of the application; and adding new logs, often you need to recompile and deploy. Although these methods are still widely in use today, but when troubleshooting complex performance problems, often time-consuming, more application uptime will
have a tremendous impact.
In addition, there are a lot of ways this kind of performance problems. For example, the probability is small, only the online environment can be met. This is difficult to reproduce the problem, it is also a huge challenge.
The emergence of dynamic tracking technology, it offers the perfect solution for these problems: it does not require stopping the service does not need to modify the application code; everything still according to the original mode during normal operation, it can help you analyze root of the problem.
At the same time, compared to the previous process-level tracking methods (such as ptrace), dynamic tracking often only brought a small performance loss (usually 5% or less).
Since there are so many benefits of dynamic tracking, then, what are dynamic tracking methods, how to use these dynamic tracking methods? Today, I'll take you take a look at this issue. As more knowledge dynamic tracking involved, I will be divided into upper and lower
articles were you explain, first look at this part today.
Second, dynamic tracking
When it comes to dynamic tracking (Dynamic Tracing), you would have to mention the system from Solaris DTrace. DTrace is a dynamic tracing technology originator, which provides a common framework for observation, and can use the D language to extend freedom.
DTrace works as shown below. Permanent its run in the kernel, users can dtrace command, the tracking script written in D language, when submitted to the Executive to run the kernel. DTrace can track everything kernel mode and user mode
pieces, and through a series of optimization measures, to ensure minimal performance overhead.
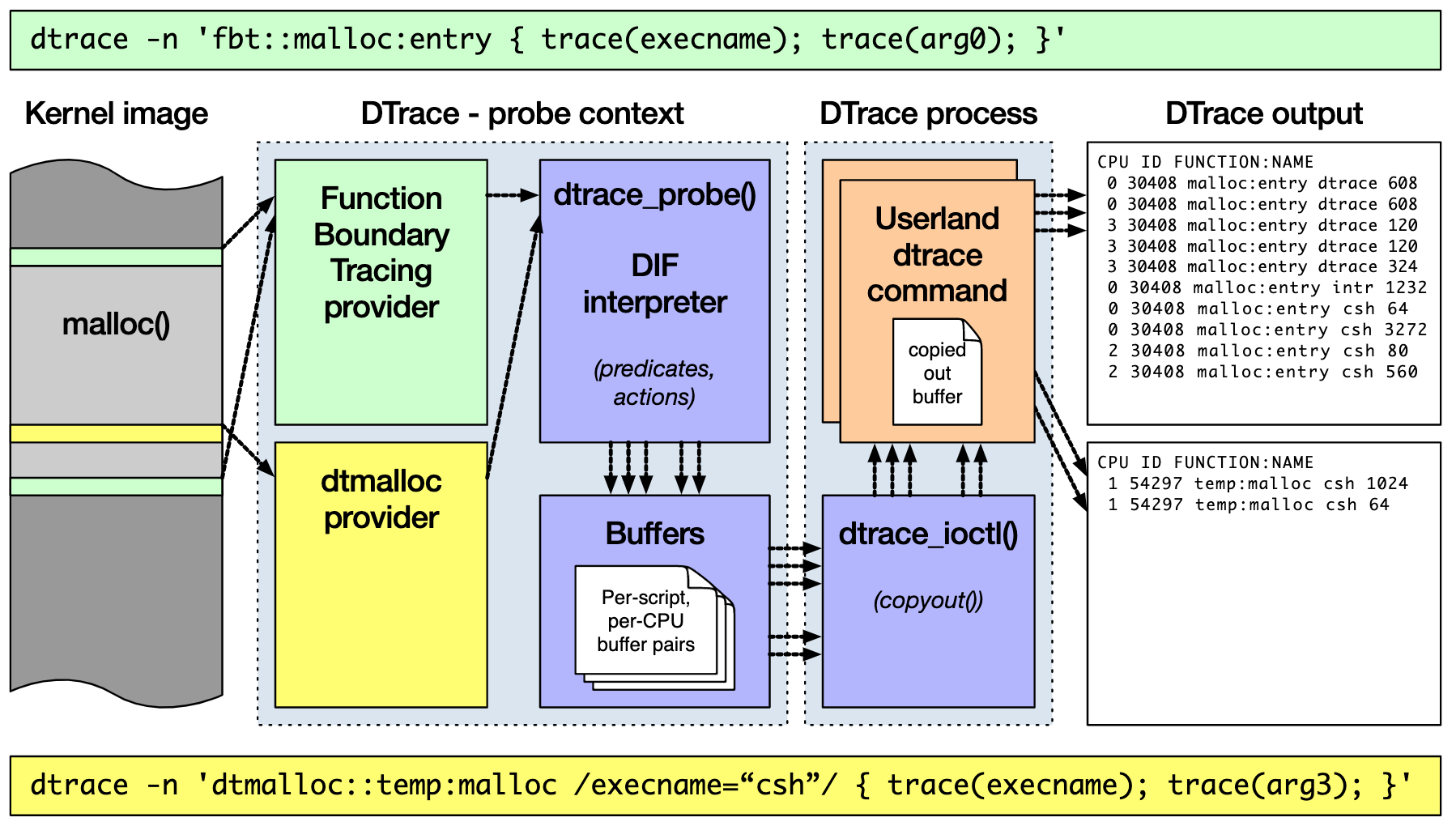
Although until today, DTrace itself still can not run on Linux, but it is equally dynamic tracking of Linux had a tremendous impact. Many engineers have tried to DTrace to Linux, of which the most famous is the main push of RedHat SystemTap.
Like with DTrace, SystemTap also defines a similar scripting language, user-friendly expansion of freedom as needed. However, unlike the DTrace, SystemTap and no permanent running kernel, it needs to first compile the script for the kernel module,
and then inserted into the kernel execution. This also led to SystemTap start slow, and depends on full debugging symbol table.
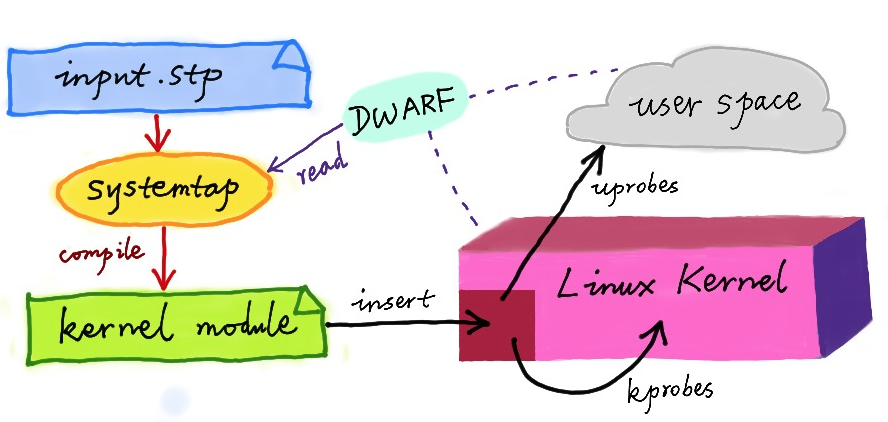
In general, tracking events in order kernel or user space, and the Dtrace SystemTap are passed to the user tracking processing function (generally referred to as the Action), associated to the detection point is referred to as probe. These probes, in fact it is a variety of dynamic chase
tracking technology relies on the event source.
Third, the dynamic tracking of the event source
The different event type, event source dynamic tracking is used, can be divided into three categories static probe, the probe and dynamic hardware events. Their relationship is as shown below: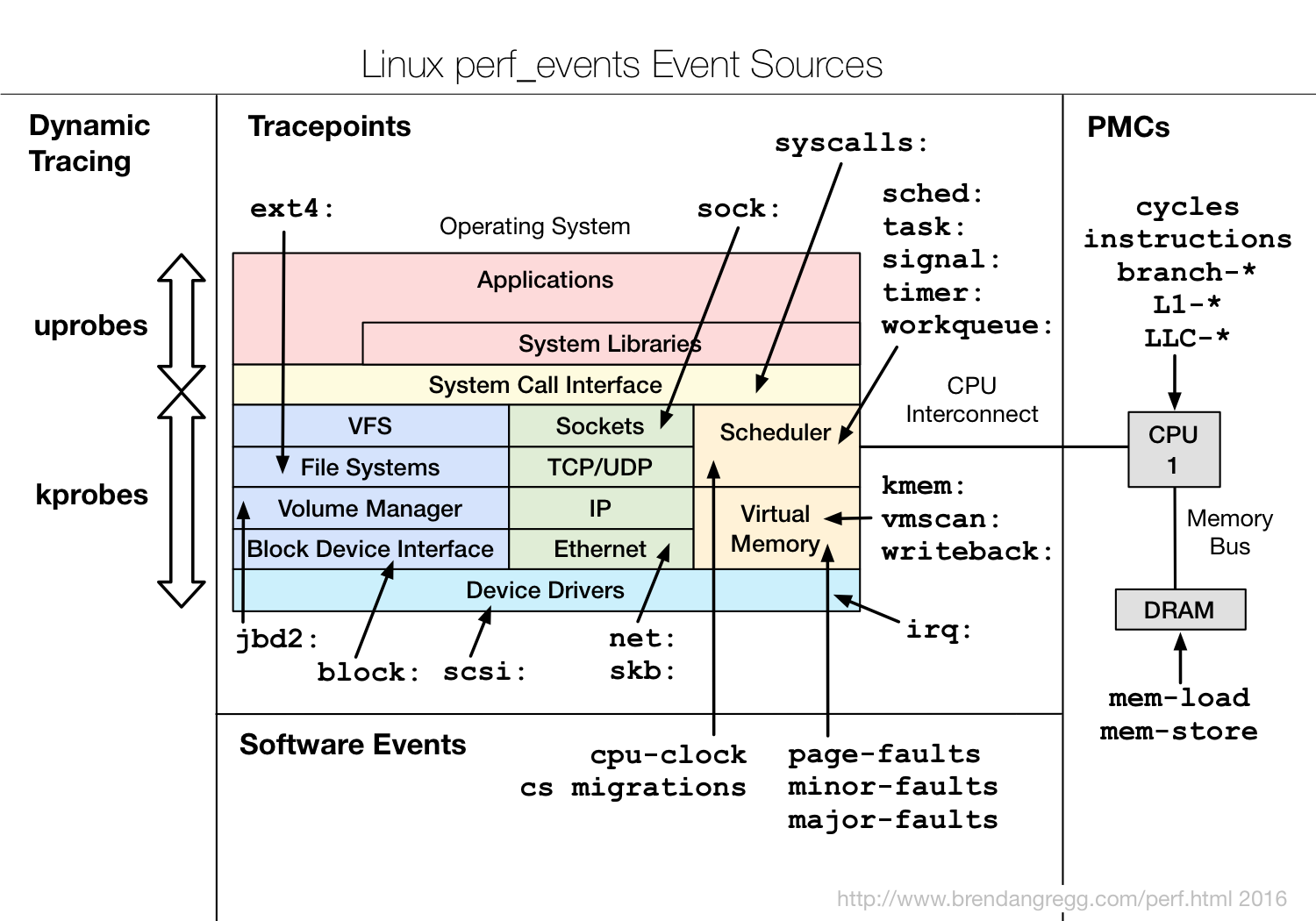
Wherein the hardware event is usually generated by the performance monitoring counter PMC (Performance Monitoring Counter), including a case where the performance of various hardware, such as a CPU cache, the instruction cycle, the branch prediction and the like.
Static probe, means a well defined in advance in the code, and compiled into the kernel or application probe. These probes only in the open detection function will be executed to; do not execute when not turned on. Common static probes include the kernel trace points
(tracepoints) and USDT (Userland Statically Defined Tracing) probe.
- Tracking point (tracepoints), is actually inserted in the source code with a number of probe points controlled conditions, which allow the probe point add post processing function. For example, in the kernel, the most common method is static tracking printk, ie the output log. Linux kernel defines a number of tracking points can be turned on or off via the kernel compile options.
- USDT probe, the user name is statically defined class tracking, DTRACE_PROBE need to insert in the source code () code, and compiled into the application. However, there are many applications built USDT probes, such as MySQL, PostgreSQL and so on.
Dynamic Probe, refers not previously defined in the code, but the probes can be added dynamically at run time, such as a function call and return and the like. Add the probe support on-demand dynamic probe point in the kernel or application, greater flexibility. Common dynamic
state of two probes, i.e., for kprobes kernel mode and a user mode uprobes.
- kprobes kernel mode functions for tracking, including a function call and a kprobe kretprobe function returns.
- uprobes used to track the user mode function, comprising means for function calls and means for uprobe uretprobe function returns.
Open CONFIG_UPROBE_EVENTS and uprobes when you need to compile the kernel; open CONFIG_KPROBE_EVENTS note, kprobes need a kernel compile time.
Fourth, the dynamic tracking mechanism
And on the basis of these probes, Linux also provides a range of dynamic tracking mechanisms, such as ftrace, perf, eBPF and so on.
ftrace earliest functions for tracking, and later extended to support a variety of event tracking. ftrace use interfaces with similar procfs we mentioned before, it is by debugfs (after 4.1 also supports tracefs), in the form of regular files, to the user
to provide access interface space.
File read and write in this way, no additional tool, you can mount point (typically / sys / kernel / debug / tracing directory) to interact with ftrace, tracking kernel or run the event of the application.
perf is our old friend, and we in front of a lot of cases, are used in its event recording and analysis capabilities, which is actually just a simple static tracking mechanism. You can also perf, from the definition of dynamic events (perf probe),
only focus on the real events of interest.
eBPF is extended from the base BPF (Berkeley Packet Filter) is on, not only supports event tracking mechanism, it can also freely expanded by custom BPF code (C language). So, eBPF actually reside in the kernel is running
, you can say that Linux version of DTrace.
In addition, there are many tools out of the kernel, but also provides a wealth of dynamic tracking. The most common is the previously mentioned SystemTap, we have repeatedly used before BCC (BPF Compiler Collection), as well as commonly used in container performance
analysis sysdig and so on.
In the analysis of a large number of events, using a flame drawing on lessons we mentioned, a large number of data can be visual display, allowing you to identify potential problems more intuitive.
Next, I would pass a few examples with you to see how to use these mechanisms to dynamically track the implementation of the kernel and applications. The following case is based on Ubuntu 18.04 system, it is equally applicable to other systems.
Note that all of the following commands as root by default, if you use the landing system as a normal user, run sudo su root command to switch to root user.
Five, ftrace
Let's look at ftrace. Just mentioned, ftrace by debugfs (or tracefs), to provide space for the user interface. Therefore use ftrace, often starting from switching to the debugfs mount point.
cd /sys/kernel/debug/tracing $ ls README instances set_ftrace_notrace trace_marker_raw available_events kprobe_events set_ftrace_pid trace_options ...
If this directory does not exist, then your system has not mounted debugfs, you can execute the following command to mount it:
mount -t debugfs nodev /sys/kernel/debug
ftrace provides multiple trackers to track different types of information, such as function calls, interrupts closed, process scheduling. Specific support tracker depends on the system configuration, you can execute the following command to query all supported tracker:
cat available_tracers hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
Among these, function that the implementation of the tracking function, function_graph relationship tracking function is invoked, that is generated visual call graphs. This is the two most commonly used tracker.
In addition to tracking device before use ftrace, also you need to make sure to track targets, including core kernel functions and events. among them,
- Function is the function name in the kernel.
- The event, the point is to track the kernel source code defined in advance.
Similarly, you can execute the following command to query support functions and events:
cat available_filter_functions $ cat available_events
Understand this basic information, then, I will take the ls command, for example, take you to see the use of ftrace.
To list the files, ls command invokes the open directory files open system, open the corresponding kernel function named do_sys_open. So, we have to do the first step is to track the function is set to do_sys_open:
echo do_sys_open > set_graph_function
Next, the second step, configure the tracking option, open the function call tracing and tracking the calling process:
echo function_graph > current_tracer $ echo funcgraph-proc > trace_options
Then, the third step, which is open to track:
echo 1 > tracing_on
The fourth step, after the implementation of a ls command, and then close the track:
ls $ echo 0 > tracing_on
Actual test code is as follows:
[root@luoahong tracing]# cat available_tracers blk function_graph wakeup_dl wakeup_rt wakeup function nop [root@luoahong tracing]# cat available_events|head kvmmmu:kvm_mmu_pagetable_walk kvmmmu:kvm_mmu_paging_element kvmmmu:kvm_mmu_set_accessed_bit kvmmmu:kvm_mmu_set_dirty_bit kvmmmu:kvm_mmu_walker_error kvmmmu:kvm_mmu_get_page kvmmmu:kvm_mmu_sync_page kvmmmu:kvm_mmu_unsync_page kvmmmu:kvm_mmu_prepare_zap_page kvmmmu:mark_mmio_spte [root@luoahong tracing]# echo do_sys_open > set_graph_function [root@luoahong tracing]# echo funcgraph-proc > trace_options -bash: echo: write error: Invalid argument [root@luoahong tracing]# echo function_graph > current_tracer [root@luoahong tracing]# echo funcgraph-proc > trace_options [root@luoahong tracing]# echo 1 > tracing_on [root@luoahong tracing]# ls available_events dynamic_events kprobe_events saved_cmdlines set_ftrace_pid timestamp_mode trace_stat available_filter_functions dyn_ftrace_total_info kprobe_profile saved_cmdlines_size set_graph_function trace tracing_cpumask available_tracers enabled_functions max_graph_depth saved_tgids set_graph_notrace trace_clock tracing_max_latency buffer_percent events options set_event snapshot trace_marker tracing_on buffer_size_kb free_buffer per_cpu set_event_pid stack_max_size trace_marker_raw tracing_thresh buffer_total_size_kb function_profile_enabled printk_formats set_ftrace_filter stack_trace trace_options uprobe_events current_tracer instances README set_ftrace_notrace stack_trace_filter trace_pipe uprobe_profile [root@luoahong tracing]# echo 0 > tracing_on
The fifth step, the final step is to view the trace results:
cat trace
# tracer: function_graph
#
# CPU TASK/PID DURATION FUNCTION CALLS
# | | | | | | | | |
0) ls-12276 | | do_sys_open() {
0) ls-12276 | | getname() {
0) ls-12276 | | getname_flags() {
0) ls-12276 | | kmem_cache_alloc() {
0) ls-12276 | | _cond_resched() {
0) ls-12276 | 0.049 us | rcu_all_qs();
0) ls-12276 | 0.791 us | }
0) ls-12276 | 0.041 us | should_failslab();
0) ls-12276 | 0.040 us | prefetch_freepointer();
0) ls-12276 | 0.039 us | memcg_kmem_put_cache();
0) ls-12276 | 2.895 us | }
0) ls-12276 | | __check_object_size() {
0) ls-12276 | 0.067 us | __virt_addr_valid();
0) ls-12276 | 0.044 us | __check_heap_object();
0) ls-12276 | 0.039 us | check_stack_object();
0) ls-12276 | 1.570 us | }
0) ls-12276 | 5.790 us | }
0) ls-12276 | 6.325 us | }
...
Actual test code is as follows:
[root@luoahong tracing]# cat trace|head -n 100
# tracer: function_graph
#
# CPU TASK/PID DURATION FUNCTION CALLS
# | | | | | | | | |
0) ls-9986 | | do_sys_open() {
0) ls-9986 | | getname() {
.......
0) ls-9986 | | dput() {
0) ls-9986 | | _cond_resched() {
0) ls-9986 | 0.184 us | rcu_all_qs();
0) ls-9986 | 0.535 us | }
0) ls-9986 | 0.954 us | }
0) ls-9986 | 9.782 us | }
In the final output obtained:
- The first column indicates the operation of CPU;
- The second column is the task name and the process PID;
- The third column is a function of executing the delay;
- The last one, it is to call a function of the relationship.
As you can see, the function call graph, different levels of indentation, visual display of the call relationships among functions.
Of course, I think you should also find the disadvantages of using ftrace - the five steps it is trouble with them is not easy. But do not worry, trace-cmd have to help you put these steps to package up. In this way, you can be in the same command-line
tool, the process to complete all of the above.
You can execute the following command to install the trace-cmd:
# Ubuntu $ apt-get install trace-cmd # CentOS $ yum install trace-cmd
After installation, the original five-step tracking process can be simplified into the following two steps:
trace-cmd record -p function_graph -g do_sys_open -O funcgraph-proc ls
$ trace-cmd report
...
ls-12418 [000] 85558.075341: funcgraph_entry: | do_sys_open() {
ls-12418 [000] 85558.075363: funcgraph_entry: | getname() {
ls-12418 [000] 85558.075364: funcgraph_entry: | getname_flags() {
ls-12418 [000] 85558.075364: funcgraph_entry: | kmem_cache_alloc() {
ls-12418 [000] 85558.075365: funcgraph_entry: | _cond_resched() {
ls-12418 [000] 85558.075365: funcgraph_entry: 0.074 us | rcu_all_qs();
ls-12418 [000] 85558.075366: funcgraph_exit: 1.143 us | }
ls-12418 [000] 85558.075366: funcgraph_entry: 0.064 us | should_failslab();
ls-12418 [000] 85558.075367: funcgraph_entry: 0.075 us | prefetch_freepointer();
ls-12418 [000] 85558.075368: funcgraph_entry: 0.085 us | memcg_kmem_put_cache();
ls-12418 [000] 85558.075369: funcgraph_exit: 4.447 us | }
ls-12418 [000] 85558.075369: funcgraph_entry: | __check_object_size() {
ls-12418 [000] 85558.075370: funcgraph_entry: 0.132 us | __virt_addr_valid();
ls-12418 [000] 85558.075370: funcgraph_entry: 0.093 us | __check_heap_object();
ls-12418 [000] 85558.075371: funcgraph_entry: 0.059 us | check_stack_object();
ls-12418 [000] 85558.075372: funcgraph_exit: 2.323 us | }
ls-12418 [000] 85558.075372: funcgraph_exit: 8.411 us | }
ls-12418 [000] 85558.075373: funcgraph_exit: 9.195 us | }
...
Actual test code is as follows:
[root@luoahong ~]# trace-cmd report|head -n 100
CPU 0 is empty
cpus=2
ls-10015 [001] 3232.717769: funcgraph_entry: 1.802 us | mutex_unlock();
ls-10015 [001] 3232.720548: funcgraph_entry: | do_sys_open() {
ls-10015 [001] 3232.720549: funcgraph_entry: | getname() {
ls-10015 [001] 3232.720549: funcgraph_entry: | getname_flags() {
ls-10015 [001] 3232.720549: funcgraph_entry: | kmem_cache_alloc() {
ls-10015 [001] 3232.720550: funcgraph_entry: | _cond_resched() {
ls-10015 [001] 3232.720550: funcgraph_entry: 0.206 us | rcu_all_qs();
ls-10015 [001] 3232.720550: funcgraph_exit: 0.724 us | }
ls-10015 [001] 3232.720550: funcgraph_entry: 0.169 us | should_failslab();
ls-10015 [001] 3232.720551: funcgraph_entry: 0.177 us | memcg_kmem_put_cache();
ls-10015 [001] 3232.720551: funcgraph_exit: 1.792 us | }
ls-10015 [001] 3232.720551: funcgraph_entry: | __check_object_size() {
ls-10015 [001] 3232.720552: funcgraph_entry: 0.167 us | check_stack_object();
ls-10015 [001] 3232.720552: funcgraph_entry: 0.207 us | __virt_addr_valid();
ls-10015 [001] 3232.720552: funcgraph_entry: 0.212 us | __check_heap_object();
ls-10015 [001] 3232.720553: funcgraph_exit: 1.286 us | }
ls-10015 [001] 3232.720553: funcgraph_exit: 3.744 us | }
ls-10015 [001] 3232.720553: funcgraph_exit: 4.134 us | }
You will find that the output trace-cmd, with the output of the cat trace is similar.
Through this example we know that when you want to understand the process of calling a kernel function, use ftrace, you can track its execution.
VI Summary
Today, I bring you learn with a common dynamic tracking method. The so-called dynamic tracking system is in normal operation or an application, through the probe to provide the kernel dynamic tracking their behavior, so as to assist the investigation performance bottlenecks.
In the Linux system, the common dynamic tracking methods include ftrace, perf, eBPF SystemTap and so on. When you have located a kernel function, but it is not clear when the realization of the principle, you can track its execution with ftrace. As for
other dynamic tracking method, I will continue to the next lesson detailed interpretation for you.