As we all know, Hive's mission statement is to hql calculated into MapReduce, Hive's overall solution is very good, but the results are returned from the query submitted to take a long time, the query takes too long. The main reason is because Hive is a native MapReduce-based, so if we do not generate MapReduce Job, but generate Spark Job, you can take advantage of the ability to quickly perform Spark to shorten the response time of HiveHQL.
This project uses SparkSql integrate with hive, hive read the metadata of tables by SparkSql, the HiveHQL bottom using MapReduce to handle the task, resulting in slow performance characteristics, instead of the Spark more powerful engine to analyze and process, fast for users to build a user to tag portrait.
6.1 Environment Preparation
Ø 1, build hadoop cluster (see profile)
Ø 2, installation hive building data warehouses (see profile)
Ø 3, install spark cluster (see profile)
Ø 4, sparksql integration hive
6.2 sparksql integration hive
The main object of the Spark SQL so that the user can use the SQL on Spark, which can be either a data source RDD, the data may be an external source (such as text, Hive, Json etc.). Spark SQL which is a branch Spark on Hive, which is in use to resolve Hive HQL, the translation logic execution plan, the execution plan optimization logic, we can approximate that only the physical execution plan became Spark job from the job to replace MR. SparkSql integration hive hive is acquired metadata information table, and then to manipulate the data via SparkSql.
Integration steps:
① need to copy the file to the hive-site.xml Spark conf directory, so that you can find the data and metadata Hive With this configuration file storage location.
② If the metadata stored in the Hive Mysql, we also need to be prepared Mysql-related driving, such as: mysql-connector-java-5.1.35.jar
6.3 sparksql test whether successful integration hive
First start hadoop cluster, execute the command after starting the spark cluster to ensure a successful start:
/var/local/spark/bin/spark-sql --master spark://itcast01:7077 --executor-memory 1g --total-executor-cores 4
Indicated master address, every executor memory size, the total number of nuclear needs,
mysql database connection driver.
After the successful implementation of the interface: Go to the spark-sql client command line interface, 
you can then operate the database table by sql statement:
See which currently has a database --- show databases; 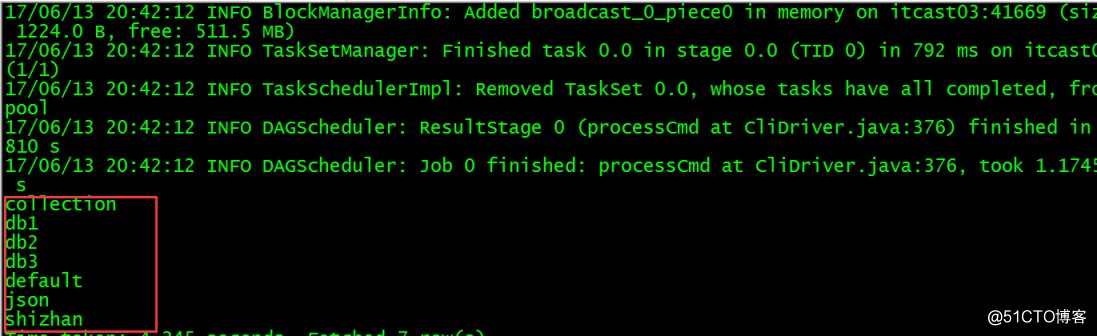
see above results, indicating sparksql integration hive success!
Log too much, we can modify the spark log output level (conf / log4j.properties)
High-energy front:
After spark2.0 version due to the emergence of sparkSession, initialization sqlContext time, will set the default spark.sql.warehouse.dir = spark-warehouse,
At this point the hive after the sparksql integration is completed, at boot time by sparksql script, or script will launch sparksql where it will create a spark.sql.warehouse.dir in the current directory of spark-warehouse directory, to store information in the database to create data and tables created by the spark-sql, hive previous data rate is not placed in the same path (can access each other). But this time the spark-sql data table locally, is not conducive to the operation, nor safe.
All need to add at startup such an argument:
--conf spark.sql.warehouse.dir=hdfs://node1:9000/user/hive/warehouse
Promise not to produce a new directory to store data when sparksql start, sparksql and end-use of the hive is a hive in the same directory data store.
If you are using previous versions of spark2.0, because there is no sparkSession, there will be no spark.sql.warehouse.dir configuration items, problem does not occur.
The final execution of the script;
the Spark-SQL \
--master spark://node1:7077 \
--executor-memory 1g \
--total-performer-colors 2 \
--conf spark.sql.warehouse.dir=hdfs://node1:9000/user/hive/warehouse