1. HashMap Overview:
Map interface is HashMap non-synchronized hash table implementation. This implementation provides all of the optional map operations, and allows the use null null values and keys. This class does not guarantee the order of mapping, in particular, it does not guarantee that the order lasts forever.
2. HashMap data structure:
In the java programming language, the basic structure is the two kinds, one is an array, a further analog pointer (reference), all these data structures can be constructed in two basic structures, the HashMap is no exception. HashMap is actually a "hash list" data structure, i.e., a combination of arrays and lists.
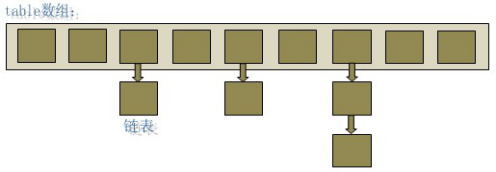
As can be seen from the figure above, the bottom of the HashMap is an array of structures, each item in the array is a linked list. When a new HashMap and it will initialize an array.
Source as follows:
1 /** 2 * The table, resized as necessary. Length MUST Always be a power of two. 3 */ 4 transient Node<K, V>[] table; 5 6 static class Node<K,V> implements Entry<K, V> { 7 final K key; 8 V value; 9 Node<K, V> next; 10 final int hash; 11 …… 12 }
As can be seen, Node is an array of elements, each Node is actually a key-value pair that holds a reference to an element pointing to the next, which constitute the list.
3. HashMap access implementation:
1) Storage:
1, to find Key Hash value, and then calculates the subscript
2, if there is no collision, directly into the bucket (the same meaning collision Hash value calculated by the need to put in the same bucket)
3, if the collision to the list of ways to link back
4, if the chain length exceeds the threshold value (TREEIFY THRESHOLD == 8), put into a red-black tree list turn
5, if the node already exists replaces the old value
6, if the bucket is full (capacity load factor 16 * 0.75), you need to resize (2-fold expansion after rearrangement)
1 final V putVal(final int n, final K k, final V value, final boolean b, final boolean b2) { 2 Node<K, V>[] array; 3 int n2; 4 if ((array = this.table) == null || (n2 = array.length) == 0) { 5 n2 = (array = this.resize()).length; 6 } 7 final int n3; 8 Node<K, V> node; 9 if ((node = array[n3 = (n2 - 1 & n)]) == null) { 10 array[n3] = this.newNode(n, k, value, null); 11 } 12 else { 13 Node<K, V> node2 = null; 14 Label_0222: { 15 final K key; 16 if (node.hash == n && ((key = node.key) == k || (k != null && k.equals(key)))) { 17 node2 = node; 18 } 19 else if (node instanceof TreeNode) { 20 node2 = ((TreeNode<K, V>)node).putTreeVal(this, array, n, k, value); 21 } 22 else { 23 int n4; 24 for (n4 = 0; (node2 = node.next) != null; node = node2, ++n4) { 25 if (node2.hash == n) { 26 final K key2; 27 if ((key2 = node2.key) == k) { 28 break Label_0222; 29 } 30 if (k != null && k.equals(key2)) { 31 break Label_0222; 32 } 33 } 34 } 35 node.next = (Node<K, V>)this.newNode(n, (K)k, (V)value, (Node<K, V>)null); 36 if (n4 >= 7) { 37 this.treeifyBin(array, n); 38 } 39 } 40 } 41 if (node2 != null) { 42 final V value2 = node2.value; 43 if (!b || value2 == null) { 44 node2.value = value; 45 } 46 this.afterNodeAccess(node2); 47 return value2; 48 } 49 } 50 ++this.modCount; 51 if (++this.size > this.threshold) { 52 this.resize(); 53 } 54 this.afterNodeInsertion(b2); 55 return null; 56 }
When the system determines HashMap stored in key-value pairs, there is no consideration in the Entry value, calculated according to the just determined key and the storage location of each Entry. We can put Map collection value as a key subsidiary, when the system determines the storage location of the key, value will be there to save.
We can see in hashmap you want to find an element, it is necessary to obtain the corresponding location in the array based on the hash value of the key. This is how to calculate the position of the hash algorithm. Preceding said data structure is a combination of arrays and hashmap linked list, of course, we hope to uniform distribution of the positions of these elements hashmap inside, as far as possible so that the number of elements at each position is only one, then when we find a hash algorithm when this position, you can immediately know the location of the corresponding elements of what we want, and not have to traverse the list. Therefore, we first thought that the length of the array hashcode modulo operation, so that the distribution of elements is relatively uniform. However, the "mode" of operation consumption is quite large, you can not find a faster, consume less way
1 static final int hash(final Object o) { 2 int n; 3 if (o == null) { 4 n = 0; 5 } 6 else { 7 final int hashCode = o.hashCode(); 8 n = (hashCode ^ hashCode >>> 16); 9 } 10 return n; 11 }
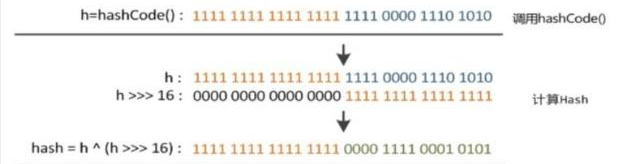
Is simply: 16bt constant high, low, and high 16bit 16bit made an exclusive OR (obtained HASHCODE into binary 32-bit, 16-bit front 16 and rear lower 16bit and 16bit made a high XOR)
For any given object for as long as it hashCode () returns the same value, the program calls the hash hash code value (int h) calculated by the method is always the same.
1 public int hashCode() { 2 int h = this.hash; 3 int len = this.value.length; 4 if (h == 0 && len > 0) { 5 char[] s = this.value; 6 for (int i = 0; i < len; ++i) { 7 h = 31 * h + s[i]; 8 } 9 //s[0]*31^(len-1) + s[1]*31^(len-2) + ... + s[len-1] 10 this.hash = h; 11 } 12 return h; 13 }
We first thought that the hash value of the array length modulo operation, so that the distribution of elements is relatively uniform. However, the "mode" of operation consumption is quite large, in the HashMap do so:
n3 = (n2 - 1 & n)
This method is very clever, which by array.length - save bits to obtain the object 1 & h, and the length of the underlying array is always HashMap n-th power of 2, which is optimized in terms of speed HashMap. The following code HashMap constructor:
1 static final int tableSizeFor(final int n) { 2 final int n2 = n - 1; 3 final int n3 = n2 | n2 >>> 1; 4 final int n4 = n3 | n3 >>> 2; 5 final int n5 = n4 | n4 >>> 4; 6 final int n6 = n5 | n5 >>> 8; 7 final int n7 = n6 | n6 >>> 16; 8 return (n7 < 0) ? 1 : ((n7 >= 1073741824) ? 1073741824 : (n7 + 1)); 9 }
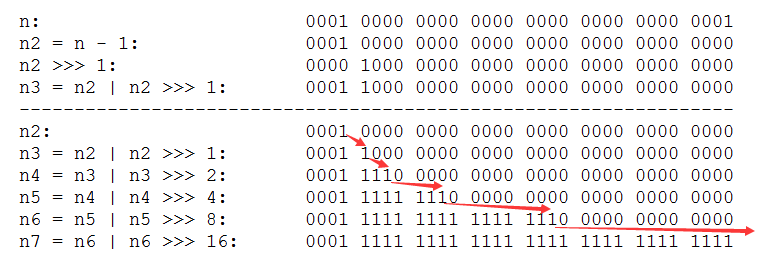
First minus one, then the binary number '1' bit capacity, bits are set to 1 after 1,2,4,8,16. N7 final binary number that is the binary number n2 of up to 1, followed by complement 1.
HashMap initialization code to ensure the capacity is always 2 of the n -th power, i.e., the length of the array is always the bottom layer 2 of the n -th power (2 ^ 30 - 1).
When the n-th power of 2 always length, h & (length-1) is equivalent to the calculation of modulo length, i.e. length% H,% but higher than & efficient.
It looks very simple, in fact, have more mystery, we give an example to illustrate:
Suppose the length of the array 15 and 16, respectively, optimized hash codes are 8 and 9, the calculation result & follows:
h & (table.length-1) hash table.length-1
8 & (15-1): 0100 & 1110 = 0100
9 & (15-1): 0101 & 1110 = 0100
-----------------------------------------------------------------------------------------------------------------------
8 & (16-1): 0100 & 1111 = 0100
9 & (16-1): 0101 & 1111 = 0101
As can be seen from the example above: if they are 15-1 (1110) when the "AND", produced the same results, that is to say they will be positioned to the same location in the array up, which produces a collision , 8 and 9 are formed into the same position of the chain on the array, when the query to traverse the linked list would need to give 8 or 9, thus reducing the efficiency of the query. At the same time, we also found that when the array length of 15 time, hash values and 15-1 (1110) carried out "and" then the last one is always 0, and 0001,0011,0101,1001,1011,0111 chance 1101 will never be the position of these elements in the store, wasted space is quite large, even worse is the case, the position of the array can be used a lot smaller than the length of the array, which means that further increases the impact of reduced slow query efficiency! When the length of the array 16, that is, when the n-th power of 2, 2 n value on each bit binary numbers are obtained -1 1, in which the low & such, the resulting hash of the original, and the same low, so that the two values will be the same hash value list will only be formed into the same position on the array.
So, when an array of length n-th power of 2, when a different key considered less likely to have the same index, then the data is distributed over an array of relatively uniform, that is a small chance of collisions, relative, query when it without traversing the list on a location, so the query efficiency also higher.
The source code put method can be seen above, when a program attempts to key-value pairs into HashMap time, the program of the first key in accordance with the hashCode () Returns the value of the storage location determined Node: if the two key Node the hashCode () returns the value of the same, that they have the same storage location. If both Node return of key by comparing equals true, the newly added Node's value will cover the collection of original Node value, but the key will not be covered. If the two Node, by comparing the return key equals false, forming the newly added Node Node Node original collection chain.
2) reads:
1 final Node<K, V> getNode(final int n, final Object o) { 2 final Node<K, V>[] table; 3 final int length; 4 final Node<K, V> node; 5 if ((table = this.table) != null && (length = table.length) > 0 && (node = table[length - 1 & n]) != null) { 6 final K key; 7 if (node.hash == n && ((key = node.key) == o || (o != null && o.equals(key)))) { 8 return node; 9 } 10 Node<K, V> node2; 11 if ((node2 = node.next) != null) { 12 if (node instanceof TreeNode) { 13 return ((TreeNode<K, V>)node).getTreeNode(n, o); 14 } 15 K key2; 16 while (node2.hash != n || ((key2 = node2.key) != o && (o == null || !o.equals(key2)))) { 17 if ((node2 = node2.next) == null) { 18 return zero ; 19 } 20 } 21 return node2; 22 } 23 } 24 return null ; 25 }
With the above hash algorithm stored as a basis to understand this code is very easy. As can be seen from the above source code: when the get element from HashMap, the hashCode first calculates the key, to find a position corresponding to elements in the array, and then find the necessary elements in the linked list corresponding to the location of the key by the equals method.
3) Briefly sum up, in the HashMap the bottom key-value be processed as a whole, this is an overall Node objects. HashMap bottom using a Node [] array to store all of the key-value pairs, when required to store a Node objects, will decide its storage position in the array according to the hash algorithm, in determining which of the array of locations in accordance with the equals method storage location of the list; Node when a need to remove, will also find its storage position in the array according to the hash algorithm, then removed from the list of the Node on the position according to the equals method.
4. HashMap的resize(rehash):
As more and more of the elements HashMap time, the probability of hash conflict is more and more high, because the length of the array is fixed. So in order to improve the efficiency of queries, it is necessary to carry out an array of HashMap expansion, array expansion of this operation will also appear in an ArrayList, which is a common operation, and after HashMap array expansion, most consumption performance point arises: the original data in the array must recalculate their position in the new array, and into them, which is resize.
So when HashMap for expansion of it? When the number of elements exceeds HashMap * loadFactor array size, the array will be the expansion, loadFactor default value is 0.75, which is a compromise value. That is, by default, the size of the array 16, then when the number of elements in the HashMap than 16 * 0.75 = 12 when the size of the extended array is put 2 * 16 = 32, i.e., doubled, then recalculate in the position of each element in the array, which is a very consuming operation performance, so if we have to predict the number of elements in HashMap, then the preset number of elements can effectively improve the performance of the HashMap. For example, we have 1000 elements new HashMap (1000), but in theory new HashMap (1024) is more appropriate, but I have already said, even in 1000, HashMap automatically sets it to 1024. But new HashMap (1024) is not more appropriate, since 0.75 * 1024 <1000, that is to say in order to allow 0.75 * size> 1000, so we need new HashMap (2048) was the most appropriate, taking into account both & the problem, avoid resize issues.
5. HashMap performance parameters:
Comprising the HashMap several constructors:
HashMap (): Construction of an initial capacity of 16, the load factor is HashMap 0.75.
HashMap (int initialCapacity): Construction of an initial capacity initialCapacity, the load factor is HashMap 0.75.
HashMap (int initialCapacity, float loadFactor): to specify the initial capacity, create a specified load factor HashMap.
HashMap basis constructor HashMap (int initialCapacity, float loadFactor) with two parameters, which are the initial capacity and load factor initialCapacity loadFactor.
initialCapacity: HashMap the maximum capacity, i.e. the length of the underlying array.
loadFactor: loadFactor load factor is defined as: the number of the actual capacity of the hash table elements (n) / hash table (m).
Load factor is a measure of the spatial extent of use of a hash table, the greater the load factor, the higher the degree of filling of the hash table, vice versa smaller. For use hash table is a linked list method, the average time to find an element is O (1 + a), so if the load factor greater, fuller use of space, but the consequences of the search efficiency is reduced; if the load factor is too small, then the hash table of data would be too sparse, causing a serious waste of space.
HashMap implemented, the threshold field is determined by the maximum capacity of the HashMap:
1 this.threshold = tableSizeFor(n);
Binding tableSizeFor understood the function code, the threshold is the maximum number of elements corresponding to this loadFactor capacity and allowed lower, a resize re than this number, in order to reduce the actual load factor. The default load factor of 0.75 is a balanced choice of space and time efficiency. When this capacity exceeds the maximum capacity, HashMap capacity after resize twice the capacity of:
1 final float n = size / this.loadFactor + 1.0f; 2 final int n2 = (n < 1.07374182E9f) ? ((int)n) : 1073741824; 3 if (n2 > this.threshold) { 4 this.threshold = tableSizeFor(n2); 5 }
6. Fail-Fast mechanism:
We know java.util.HashMap not thread safe, so if there are other threads modifies the map, then will throw ConcurrentModificationException, this is the so-called fail-fast strategy during use iterators.
Implement this strategy in the source code by modCount domain, modCount modify the name suggests is the number of modifications to the HashMap content will increase this value, assign expectedModCount iterator iteration initialization procedure writes this value.
1 HashIterator() { 2 this.expectedModCount = HashMap.this.modCount; 3 final Node<K, V>[] table = HashMap.this.table; 4 final Node<K, V> node = null; 5 this.next = node; 6 this.current = node; 7 this.index = 0; 8 if (table != null && HashMap.this.size > 0) { 9 while (this.index < table.length && (this.next = table[this.index++]) == null) {} 10 } 11 }
In an iterative process to determine whether expectedModCount modCount with equal, if not equal, it says there are already other threads to modify the Map.
1 final Node<K, V> nextNode() { 2 final Node<K, V> next = this.next; 3 if (HashMap.this.modCount != this.expectedModCount) { 4 throw new ConcurrentModificationException(); 5 } 6 ... 7 }
In the API HashMap that:
A "collection view methods" of all classes HashMap returned iterators are fail-fast: after the iterator is created, if the map is structurally modified, except through the iterator's own remove method, any other time in any way modification, the iterator will throw a ConcurrentModificationException. Therefore, in the face of concurrent modification, the iterator fails quickly and cleanly, rather than risking arbitrary behavior uncertain future uncertain time of occurrence.
Note that the fail-fast behavior of an iterator can not be guaranteed, in general, the presence of asynchronous concurrent modification, it is impossible to make any hard guarantees. Fail-fast iterators do our best to throw ConcurrentModificationException. Therefore, the practice of writing depended on this exception procedure is wrong, the correct approach is: fail-fast behavior of iterators should be used only to detect bugs.
1. Reprinted stated: https://www.cnblogs.com/anyeshouhu/p/11527329.html
2. This is personal notes, ideas, may refer to other articles, so only for your blog without permission within the scope of study and reference.
Reference Hirofumi:
https://www.cnblogs.com/yuanblog/p/4441017.html
https://baijiahao.baidu.com/s?id=1618550070727689060&wfr=spider&for=pc