The most comprehensive HashMap source code analysis (JDK1.8)
Article directory
Prerequisite knowledge: red-black tree
To talk about red-black trees, we must first mention the binary search tree (BST), which uses the idea of binary search to make the time complexity of searching under normal circumstances O(logn). The example is shown in the figure below: satisfy the following
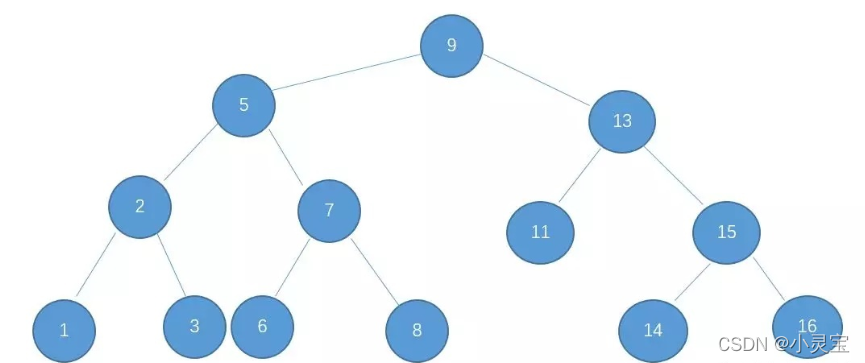
three The tree of conditions is a binary search tree:
- The value of the left subtree is less than or equal to the value of the root
- The value of the right subtree is greater than or equal to the value of the root
- The left and right subtrees are also binary search trees
The above three properties are satisfied, and the search and insertion of BST can be done with the idea of binary search. The maximum number of searches required in BST = the height of BST, and the same is true for insertion. The insertion position is found by continuously comparing the size
But BST has a disadvantage, that is, under extreme conditions, BST will degenerate into a chain, as shown in the figure below:
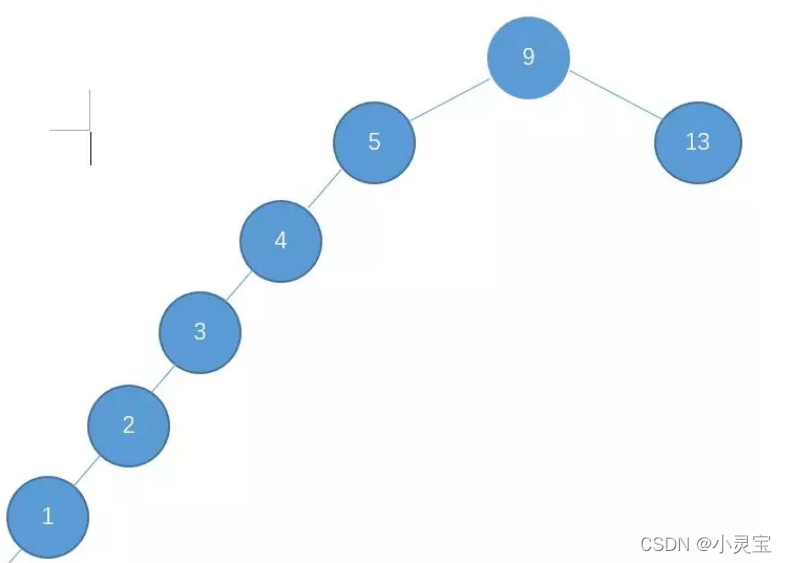
after degenerating into a chain, the time complexity of search and insertion will degenerate to O(n), that is, degenerate into a linear search. That is to say, BST is unbalanced. In order to make up for its shortcoming, a balanced binary tree (AVL) is proposed.
A balanced binary tree (AVL) has all the characteristics of BST, and it also has its unique characteristics, that is: the height difference between the left and right subtrees is at most 1. With this feature, the balanced binary tree will maintain its balance and make up for the shortcomings of BST. The example is shown in the following figure:
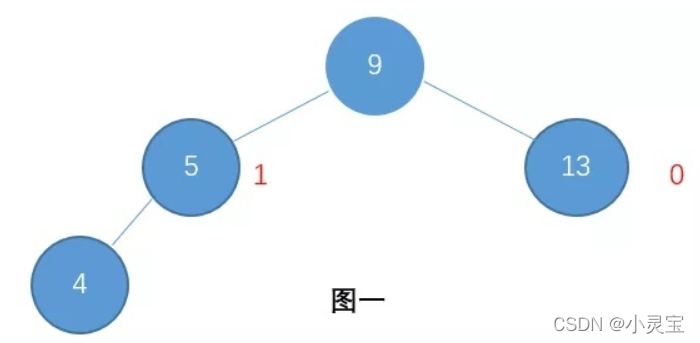
Due to its balance, the worst time complexity of AVL tree search and insertion becomes O(logn)
So now that there is AVL, why do we have to propose a red-black tree? Although AVL is good, its definition of balance: the condition that the height difference between the left and right subtrees is at most 1 is too strict, causing us to destroy the structure of the balanced binary tree almost every time we insert or delete nodes, so that we have to perform left rotation or Right-handle the handle and make it balanced again. If in the scene where insertion and deletion are very frequent, the balanced tree needs to be adjusted frequently, which will greatly reduce the performance of the balanced tree. Another secondary reason is that the implementation code of AVL is relatively complicated, and the theoretical data structure model needs to be slightly modified and compromised in practice.
Based on the above two reasons, people have proposed a less strict balanced tree, which can also be called a compromise solution, that is, the red-black tree. The worst time complexity of red-black tree search is also O(logn), but it will not break the rules of red-black tree frequently like AVL in operations such as insertion and deletion, so it does not need to be adjusted frequently. It is also the reason why we use red-black trees in most cases. An example of a red-black tree is as follows (leaf NIL nodes are not shown):
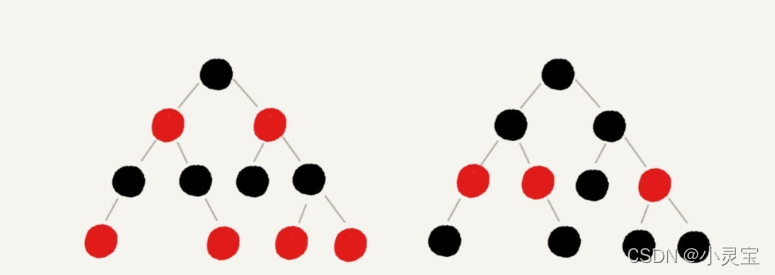
The red-black tree is a self-balancing binary search tree. In addition to the basic characteristics of BST, it also has the following five characteristics:
- Node with color attribute (red or black)
- root node is black
- Each leaf node is a black empty node (NIL node)
- Both children of each red node are black (there cannot be two consecutive red nodes on all paths from each leaf to the root)
- All paths from any node to each of its leaves contain the same number of black nodes
According to the above five characteristics, it can be deduced that the longest path from the root to the leaf of the red-black tree will not exceed twice the shortest path. When inserting or deleting nodes, the rules of the red-black tree may be broken, and adjustments are required. There are two adjustment methods: color change and rotation, and rotation is divided into left-handed and right-handed.
When a red-black tree is inserted into a node, there are 5 situations, and each situation corresponds to a specific adjustment method. Although it is more complicated, the adjustment routine is fixed and will not be introduced here.
The overall structure of HashMap
The overall structure of HashMap is an array, and the elements in the array are called hash buckets. The hash bucket can be a linked list or a red-black tree, as shown in the figure below: each element
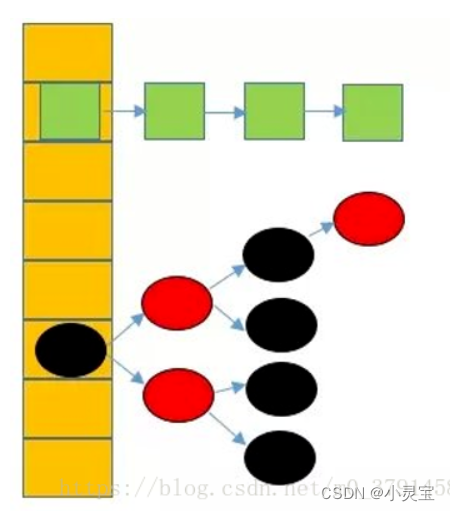
in the hash bucket stores a key,
Before jdk 1.8, the value value and the hash value corresponding to the key and other information, the HashMap is an array + linked list structure, because the query operation in the linked list is O(N) time complexity, and the query operation in the hashMap also occupies a lot For a large proportion, if the number of nodes is large, it will be converted to a red-black tree structure, which will greatly improve efficiency, because in the red-black tree structure, addition, deletion, modification and query are all O(log n). So JDK1.8 made such an adjustment.
Properties of HashMap
Default capacity DEFAULT_INITIAL_CAPACITY

DEFAULT_INITIAL_CAPACITY is the default capacity of HashMap, that is, the default size of the array, which is 16.
Why take 16, because 16 is the optimal solution obtained through continuous statistical experiments
Default load factor DEFAULT_LOAD_FACTOR

DEFAULT_LOAD_FACTOR is the default load factor of HashMap, which is 0.75, and the load factor will be used during expansion.
What is a loading factor? HashMap, as the implementation of a hash table data structure, must reserve a part of space for new elements to be hashed in. When the space is about to be full, it must be expanded instead of waiting until it is really full, because waiting until it is really full If it is full, there must have been a lot of Hash conflicts before. The load factor of 0.75 means that the HashMap can store up to 75% of the key-value pairs multiplied by the Capacity. If the amount of data exceeds 75% multiplied by the capacity, it needs to be expanded. .
Why is the loading factor 0.75, the same as the default initial capacity of 16, because 0.75 is the optimal solution obtained through continuous statistical experiments
TREEIFY_THRESHOLD
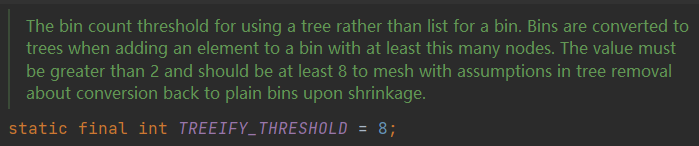
TREEIFY_THRESHOLD is the threshold for converting a hash bucket into a red-black tree. When the number of nodes in a hash bucket is greater than 8, and the length of the array is greater than MIN_TREEIFY_CAPACITY = 64, the hash bucket will be converted into a red-black tree structure
UNTREEIFY_THRESHOLD

UNTREEIFY_THRESHOLD is the threshold for converting a red-black tree into a linked list. When the number of nodes in a hash bucket is less than 6, the hash bucket will be converted into a linked list, provided that it is currently a red-black tree structure
MIN_TREEIFY_CAPACITY

When the length of the linked list is greater than TREEIFY_THRESHOLD = 8 and the length of the array is greater than MIN_TREEIFY_CAPACITY = 64, the linked
list is converted into a red-black tree. or linked list
That is to say, after setting the attribute MIN_TREEIFY_CAPACITY, the linked list does not become a red-black tree when the length is greater than 8, but the linked list becomes a red-black tree when the length of the array is greater than 64. The purpose of doing this is to avoid conflicts as much as possible. This is concluded after long-term experience and mathematical calculations. If the length of the array is less than a certain number, the effect of array expansion will be better than that of hash bucket tree.
In layman's terms, the length of the array is less than or equal to 64, which means that the array has not yet placed many hash buckets. At this time, the elements in a certain bucket are greater than 8, so if I expand the array, hash conflicts will be reduced, and the elements in the bucket will not increase. Soon, simply turning the linked list into a red-black tree does not reduce the possibility of conflicts. When the length of the array is greater than 64, the array has already placed enough hash buckets at this time, and further expansion of the array will affect the operation efficiency of HashMap. At this time, the linked list is changed into a red-black tree to improve the efficiency of operations such as search.
Node< K,V >[] table

table represents an array storing hash buckets, and the array element type is Node<K,V>, that is, hash buckets. The elements in the table are called hash buckets, which can be a linked list structure or a red-black tree structure
Set< Map.Entry< K,V > > entrySet

Convert data into another storage form of Set, mainly used for iteration
Let's take a look at what the generic Map.Entry<K,V> of Set is:
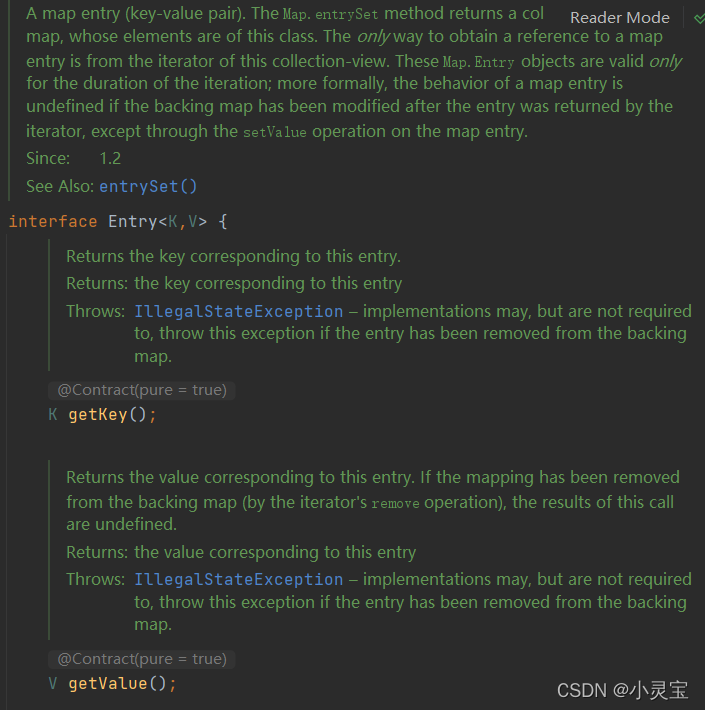
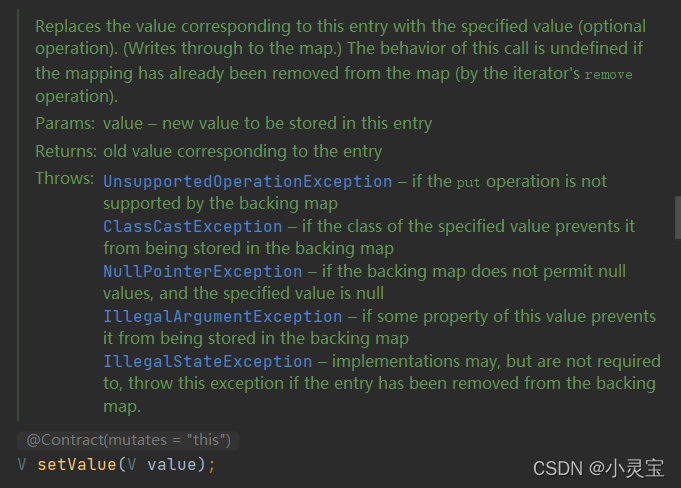
Map.Entry<K,V> is an interface defined in Map, which actually represents a key-value pair, which defines the pair get, set methods, and key and value comparison methods, etc.
Calling Map.entrySet() can convert the Map into a Set form, and the element type in the Set is Entry, which is in the form of key-value pairs
size

size indicates the number of key-value pairs in the HashMap, and when size>threshold, the resize expansion operation will be performed
modCount

modCount indicates the number of times the HashMap has been structurally modified. It is mainly used when the iterator iterates. If the HashMap is modified again, a ConcurrentModificationException will be thrown, and the concurrent modification exception will be thrown.
threshold

Threshold is the critical value. When the number of key-value key-value pairs stored in HashMap is greater than the threshold critical value, the array will be expanded
loadFactor
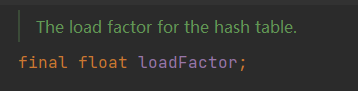
loadFactor represents the load factor, used as a variable
Inner class of HashMap
The internal class of HashMap has red-black tree node TreeNode<K, V> and linked list node Node<K, V>
Red-black tree node TreeNode< K, V >
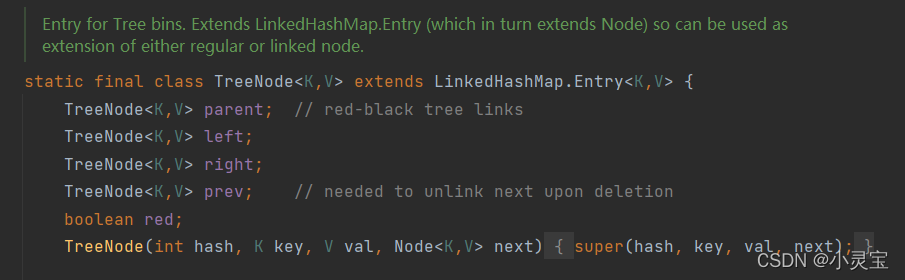
The red-black tree node TreeNode<K,V> inherits LinkedHashMap.Entry<K,V>, which is equivalent to inheriting Node<K,V>, because LinkedHashMap.Entry<K,V> inherits HashMap.Node<K, V>.
The TreeNode<K,V> internal class includes methods for inserting and finding elements in the red-black tree, converting the red-black tree into a linked list, etc.
Linked list node Node< K, V >
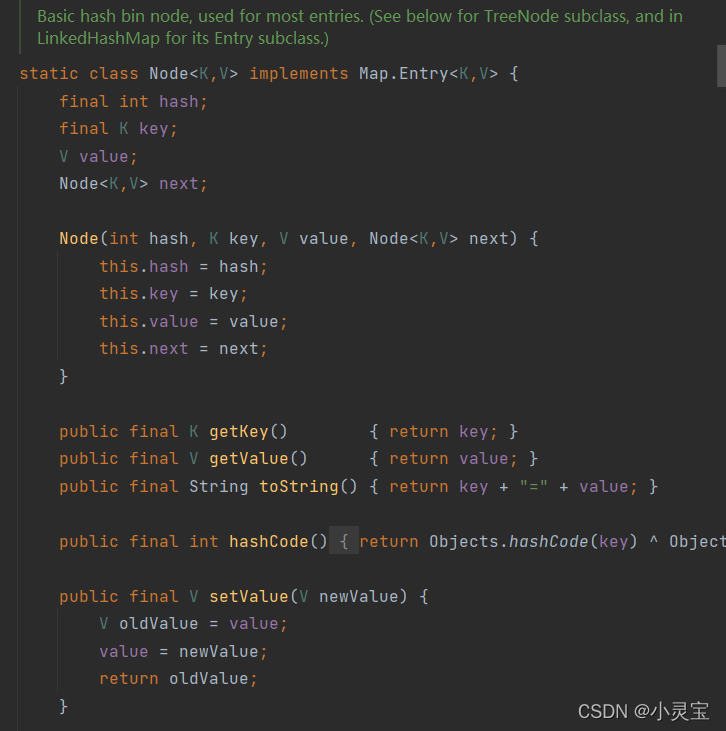
The linked list node Node<K,V> implements the Map.Entry<K,V> interface, and its attributes include key, value, hash value corresponding to the key, and the next Node node. The methods include get and set corresponding to key and value method etc.
HashMap method
Construction method
Empty parameter construction HashMap()
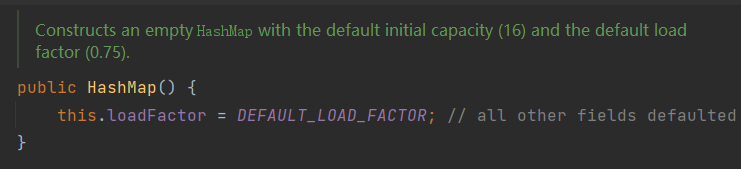
Using empty parameter construction, you will get an empty HashMap, its capacity (that is, the size of the array) is the default 16, and the filling factor is 0.75
HashMap(int initialCapacity)

Using this constructor will set the initial capacity to the value of the parameter and the fill factor to the default of 0.75
HashMap(int initialCapacity, float loadFactor)
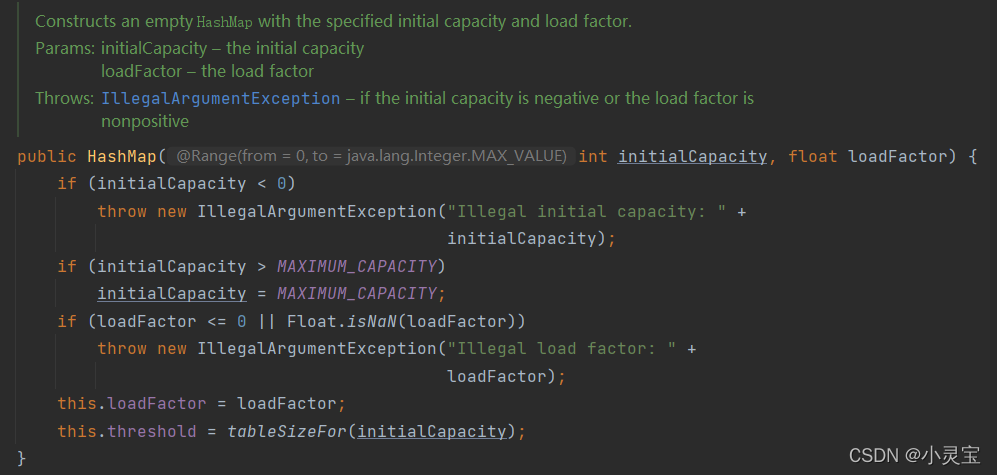
Using this constructor, the corresponding initial capacity and filling factor will be set.
This method will verify the correctness of the parameters, assign the attribute loadFactor to the corresponding parameter, and set the attribute threshold (threshold value of array expansion) as tableSizeFor(initialCapacity)
tableSizeForthe method used to calculate >= parameters The smallest integer power of 2, because the size of HashMap is always an integer power of 2.
Why should the size of HashMap be set to an integer power of 2? It is mainly for the convenience of bit operations. For details, please refer to the following link:
Why is the length of HashMap 2 to the nth power?
HashMap(Map< ? extends K,? extends V > m)

The constructor passes in a Map, and then converts the Map to a HashMap. The fill factor of the converted HashMap is 0.75. This method calls putMapEntries(m, false)the method, putMapEntrieswhich actually puts the data in the Map into the HashMap:
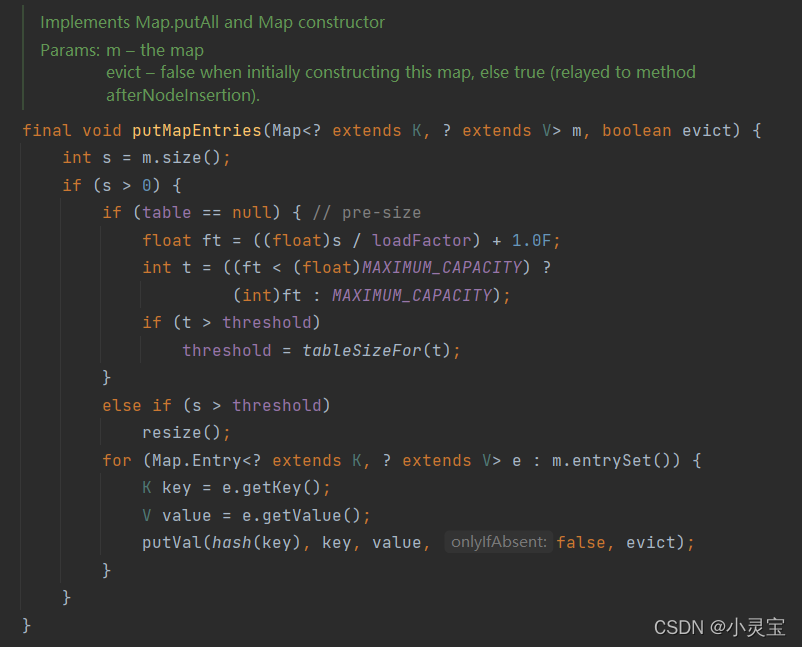
Among them, the Map.entrySet() method returns a Set<Map.Entry<K,V>>. The generic type of this Set is the internal class Entry of Map. Entry is an instance method that stores key-value. The execution flow of the method is shown in the following
putMapEntriesfigure Show:
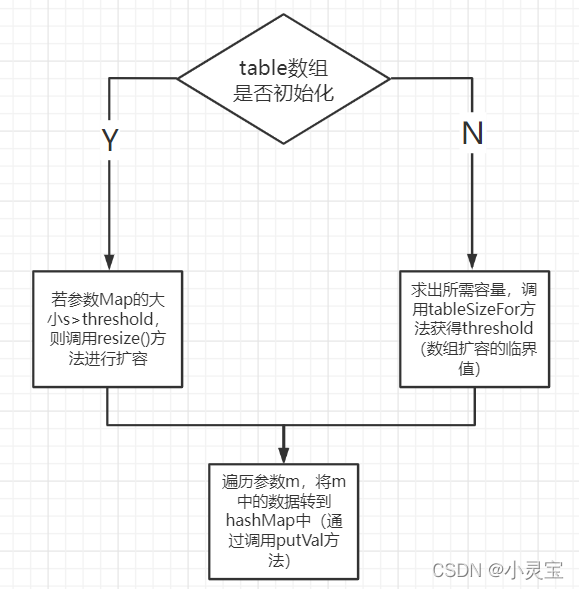
Expansion method resize()
When the number of key-value pairs in the array is greater than the threshold threshold, the resize() method will be called to expand the array. Let's see how this method is implemented: This method does two things, one is to
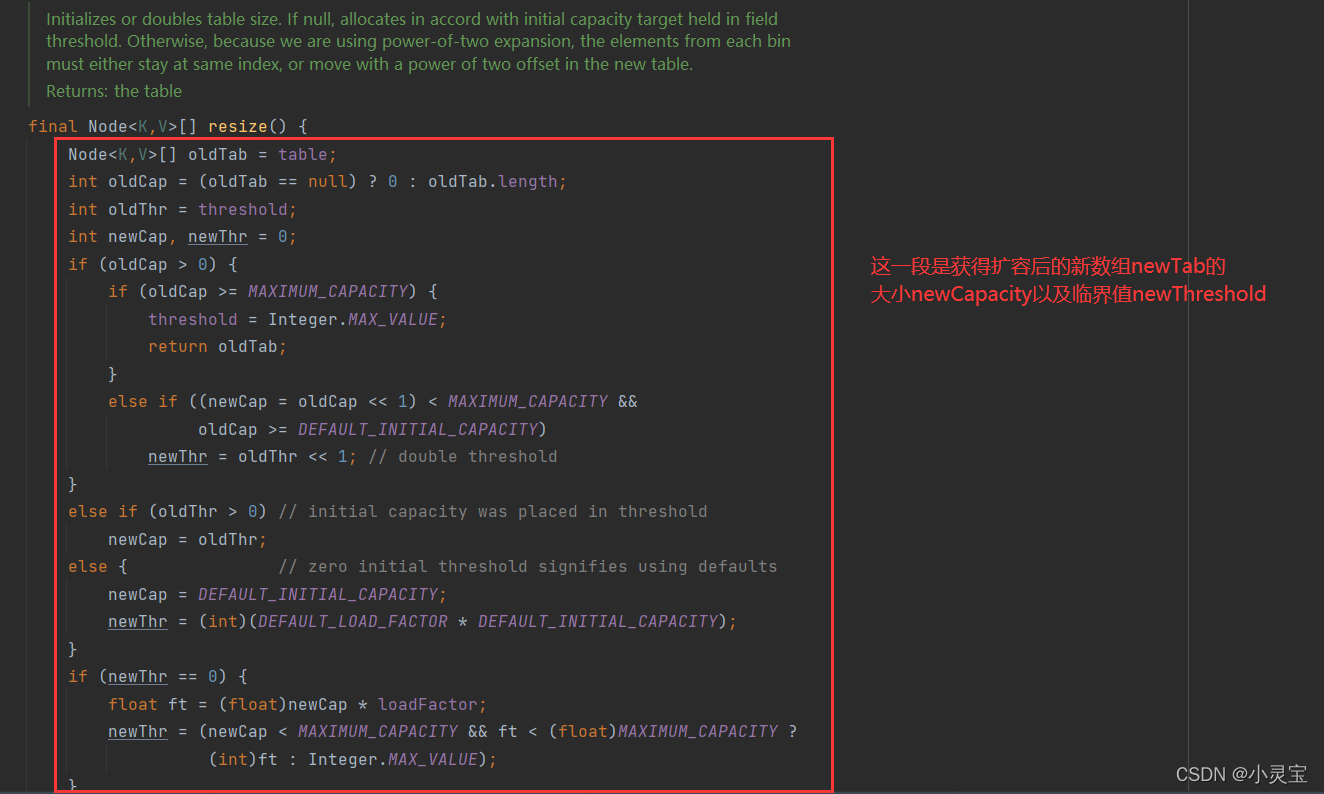
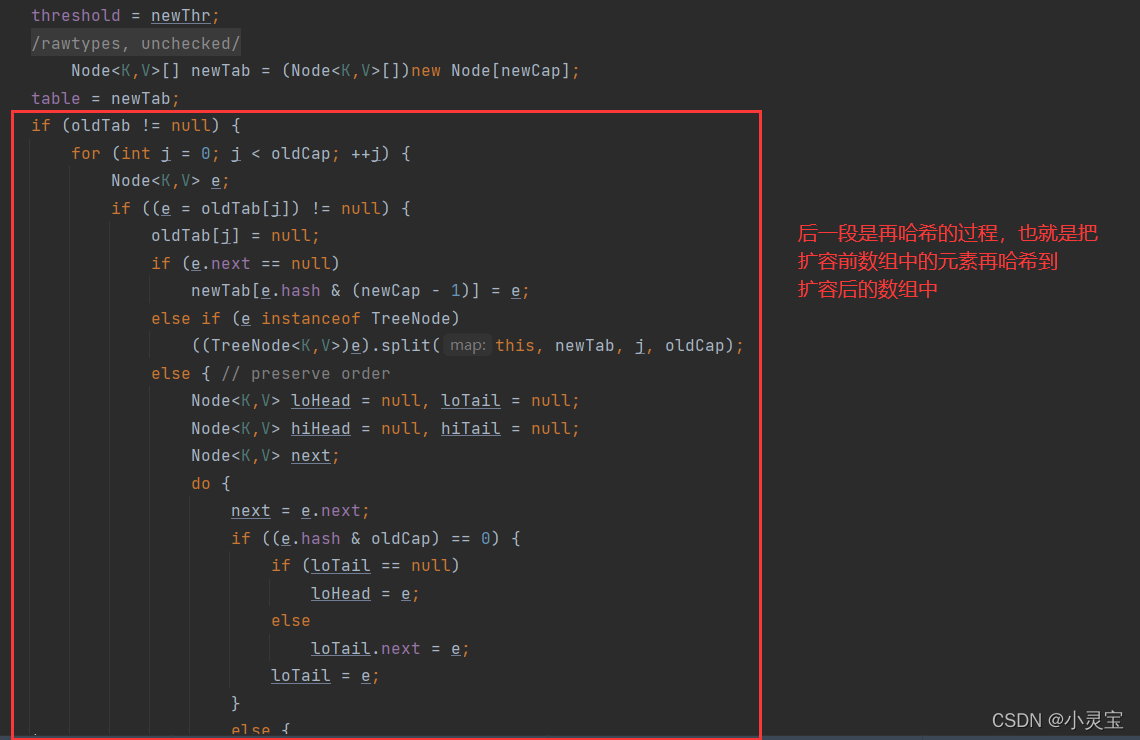
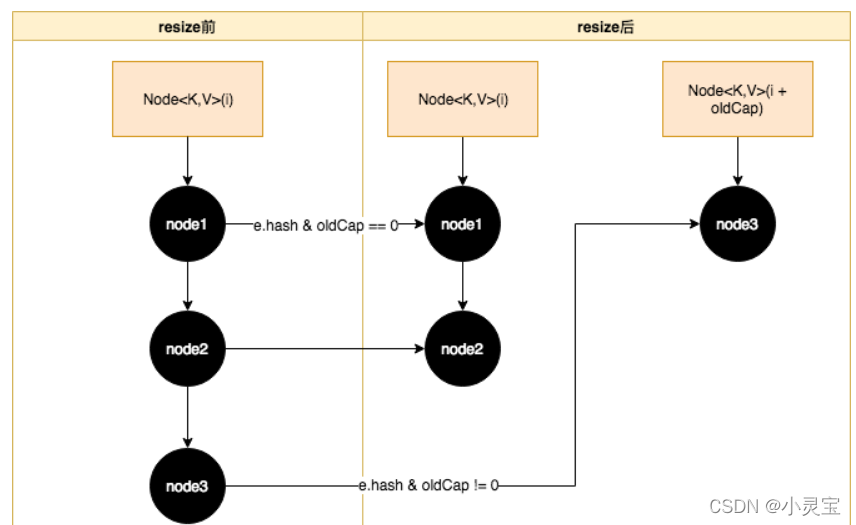
get The size and critical value of the expanded array newTab, and the second is to hash the original elements before the expansion into the new array. The specific process of this method is shown in the figure below:
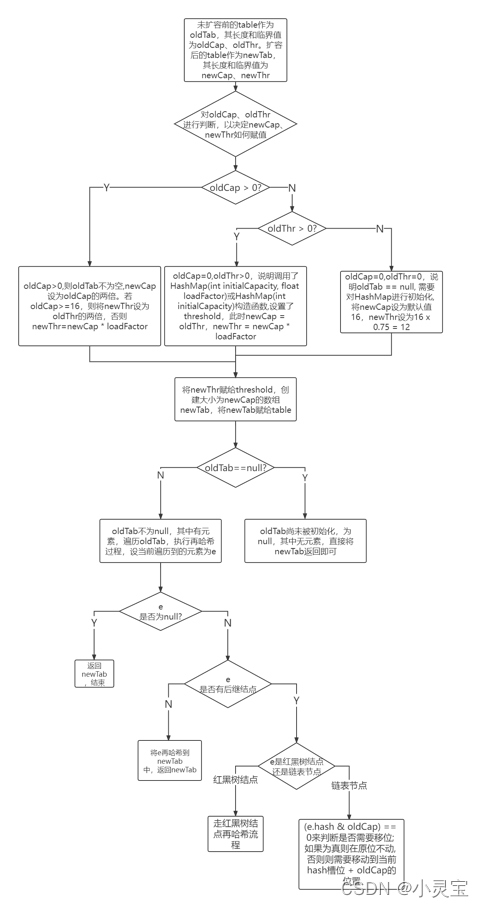
The rehashing process of the linked list hash bucket is shown in the figure below:
CRUD method
Add: put method
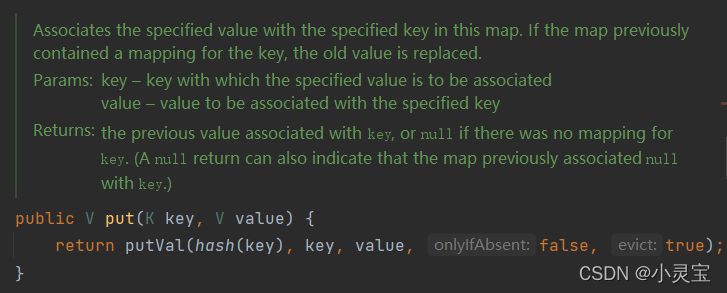
The put method actually calls the putVal method. In addition to the key and value, the hash value of the key is also used as a parameter. The hash value corresponding to the key is obtained by calling the hash(key) method. Let's see how the hash method is calculated. Hash value:
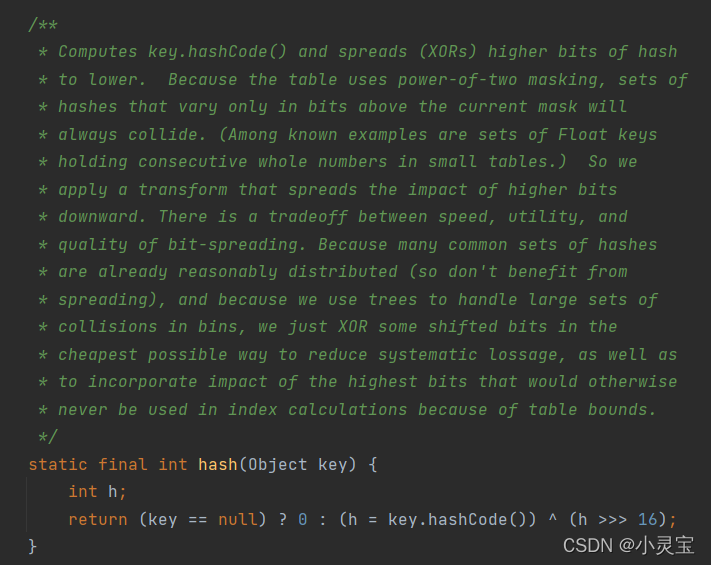
if the key is null, its hash value is 0, otherwise it is the XOR of the key's hashCode and hashCode to the right unsigned right shift 16 bits
The put method actually adds elements to the HashMap by calling the putVal method. Let's take a look at the putVal method:
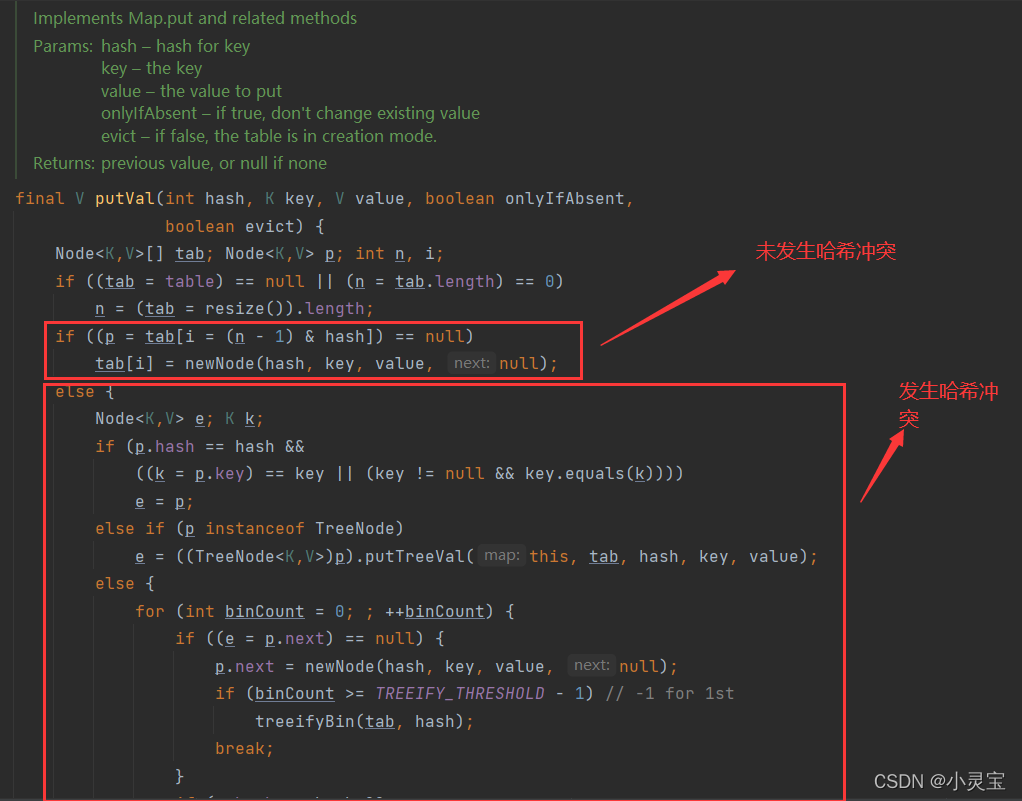
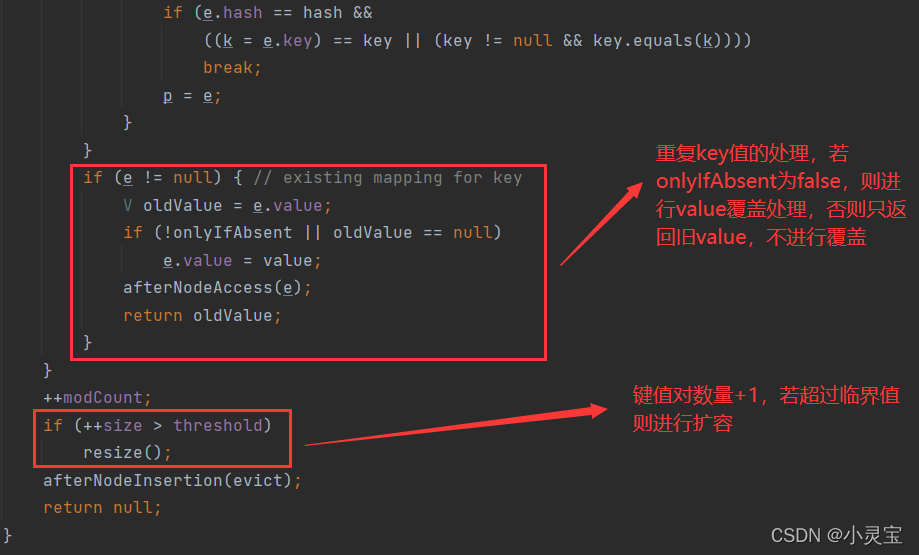
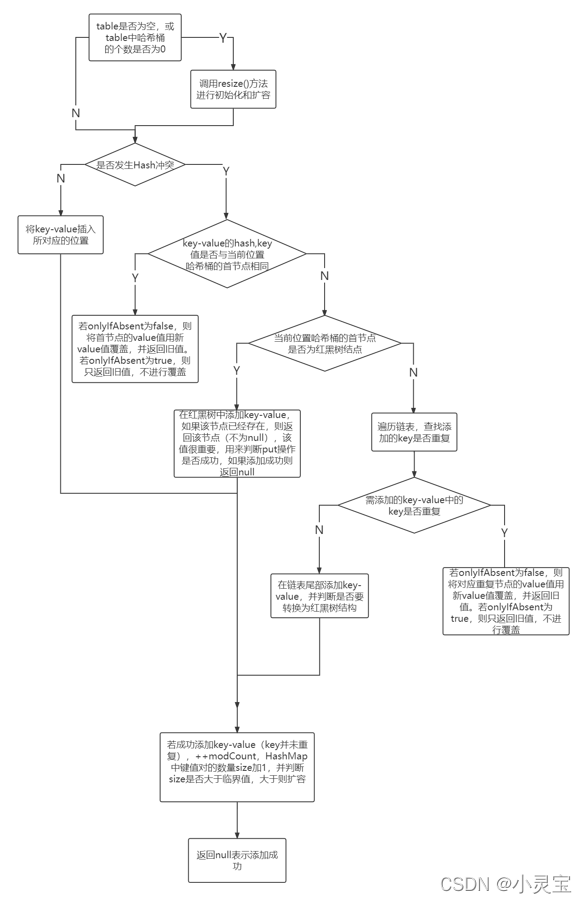
The flow of the putVal method is shown in the figure below:
Note that when the table is empty, the resize method will be called for initialization, which is why HashMap is lazy loaded, because it will only allocate space when it is used, otherwise it will not Storage space will be allocated for it
. It is worth noting that jdk provides several hook functions:

their default implementation is empty, which can be rewritten by programmers, so that different processing is performed in the case of repeated key values and successful insertion
Delete: remove method
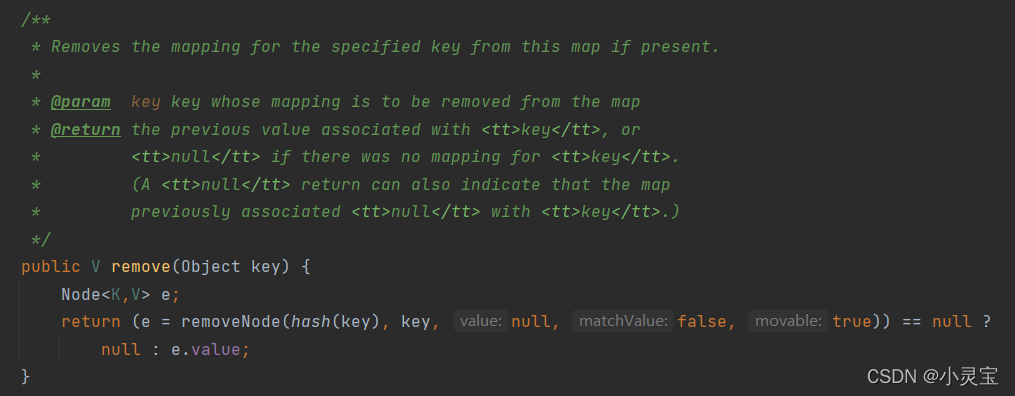
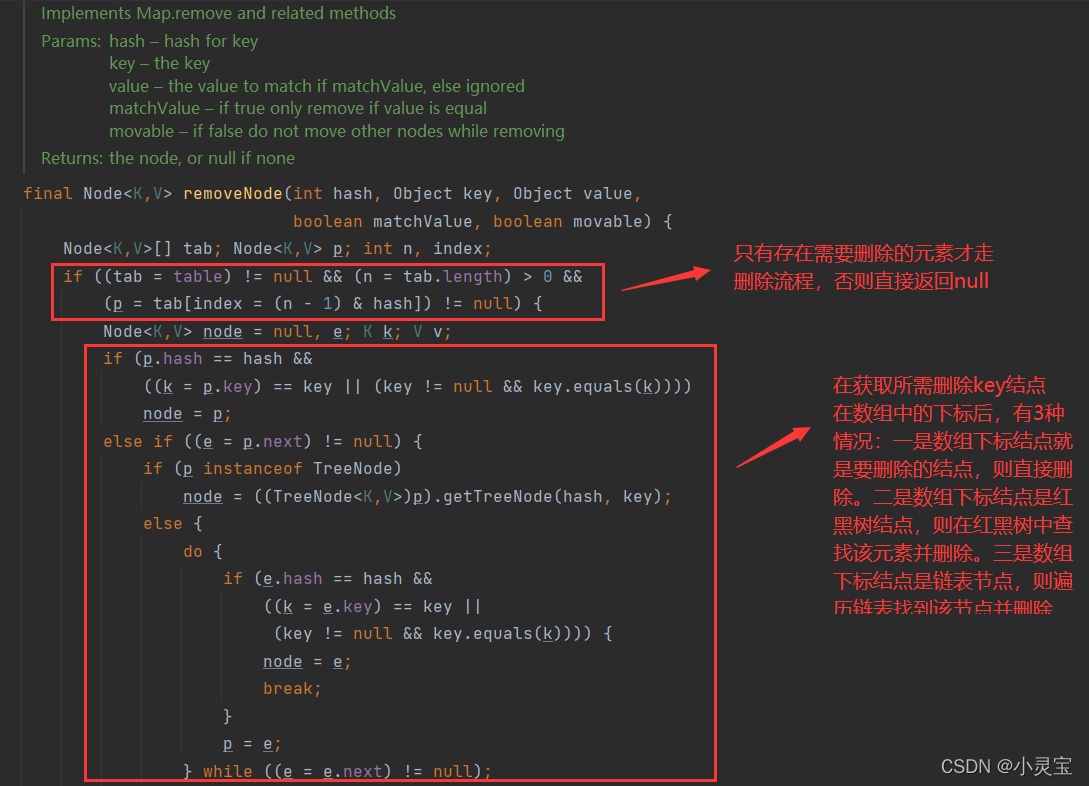
The remove method actually calls the removeNode method, let's take a look at this method:
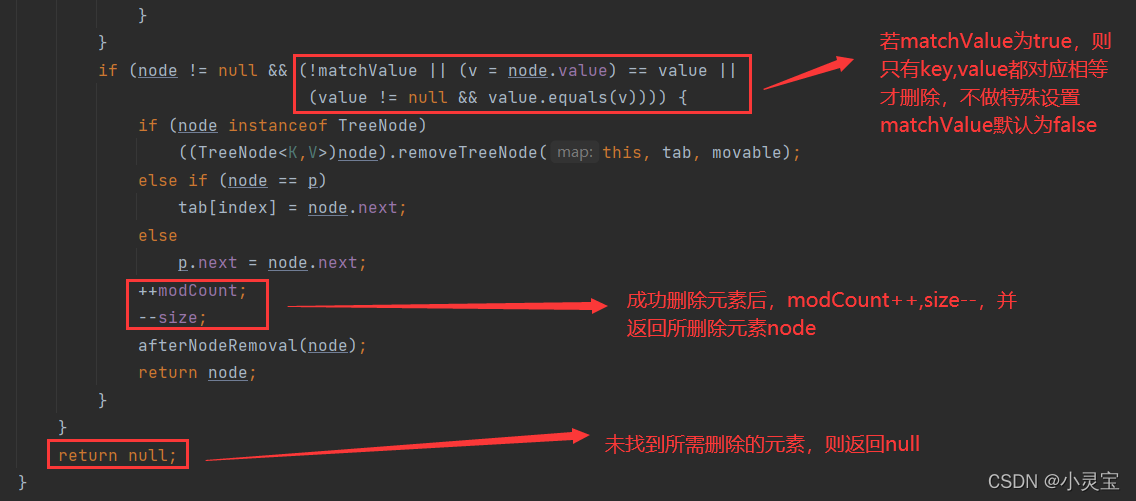
Delete also has a clear() method, which deletes all key-value pairs, which actually sets all elements of the array to null

Change: put method
The modification of the element is also the put method, because the key is unique, and onlyIfAbsent is false, so modifying the element is to overwrite the old value with the new value.
Check: get method
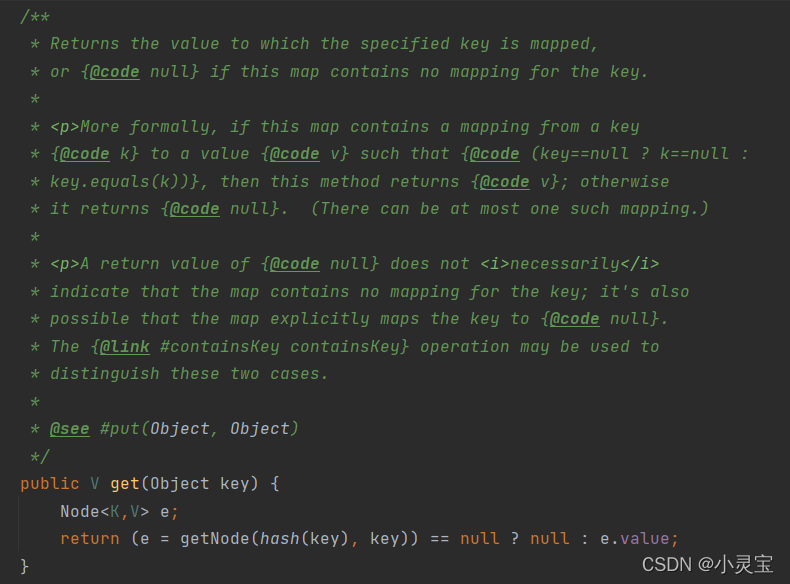
The get method actually calls the getNode method, let's take a look at the method:
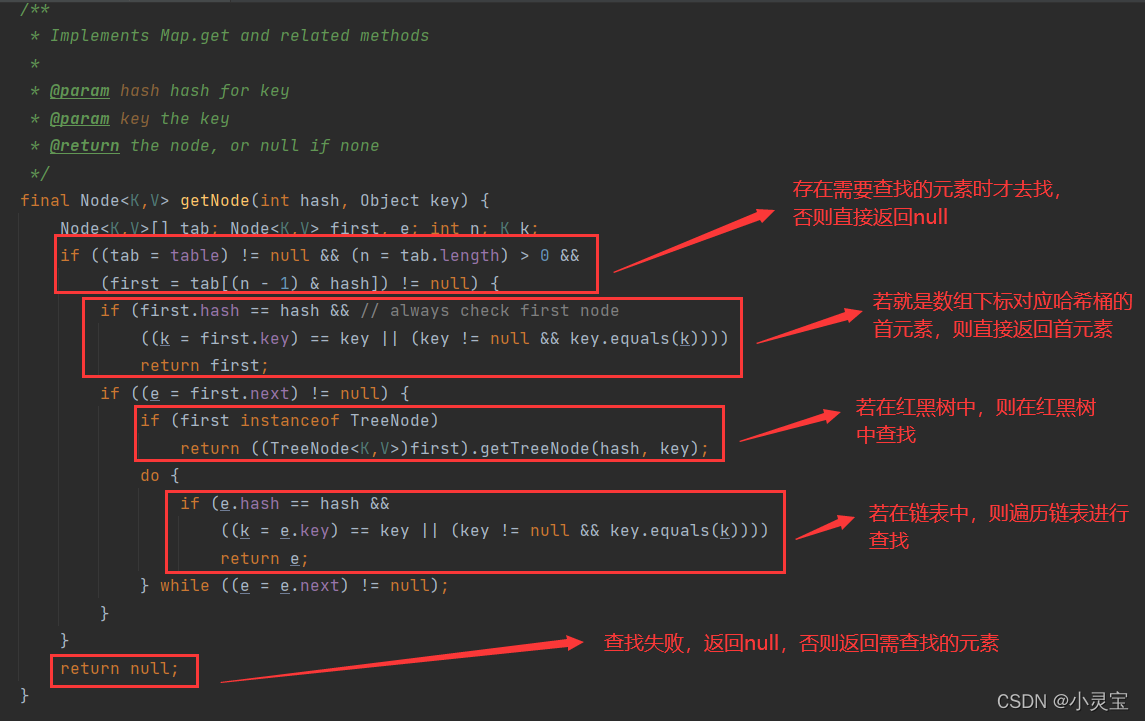
There is also a commonly used method, the containsKey method, to find out whether a key exists, in fact, it calls the getNode method:

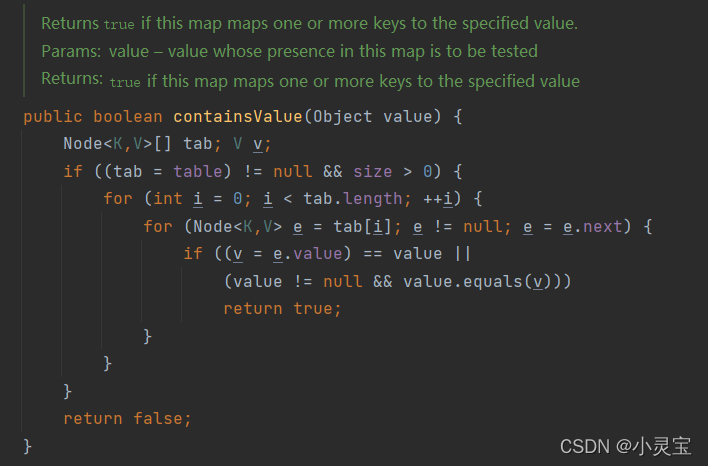
The corresponding containsValue method, which is a method to find out whether there is a value value, is very inefficient. It is used to traverse the array and search: