JDK1.8后HashMapIn-depth analysis of source code:
1. Member variables:
1.1 Initialization capacity-the number of buckets (16):static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
1.2 Maximum capacity:static final int MAXIMUM_CAPACITY = 1 << 30;
1.3 Load factor:static final float DEFAULT_LOAD_FACTOR = 0.75f;
1.4 Treeing threshold (default is 8):static final float DEFAULT_LOAD_FACTOR = 0.75f;
1.5 The minimum number of elements in the tree (64):static final int MIN_TREEIFY_CAPACITY = 64;
1.6 Remove the tree and return the threshold of the linked list (6):static final int UNTREEIFY_THRESHOLD = 6;
1.7 The hash table that actually stores the elements:transient Node<K,V>[] table;
2. Logical analysis
2.1 Tree logic:
- When the number of elements in the linked list in a bucket is greater than or equal to 8 , and the number of all elements in the hash table exceeds 64 , the structure of the linked list in the bucket will be converted into a red-black tree structure. Otherwise, only expansion will be carried out without treeing.
- Benefits: The optimization of the linked list is too long, which leads to a sharp decrease in search performance
O(n)-->O(logn), and can reduce hash collisions to improve security
2.2 Search logic:
- First find out which bucket it is located in according to its hash value, and then find it in the linked list behind the bucket according to the value value, and find
(O(n))it in the binary tree(O(logn))
3. Constructor
3.1 No-parameter construction: initial load factor
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // 默认0.75
}
3.2 Parameter structure:
//传入初始化容量
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//传入初始化容量和负载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
3.3 constructor is apparent from the above HashMapas ArrayListtaken an equally lazy loading strategy, the object initialization is not generated when the hash table
4. Core method
4.1 put method:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value 如果是false,则可以替换掉key值相同的value值
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
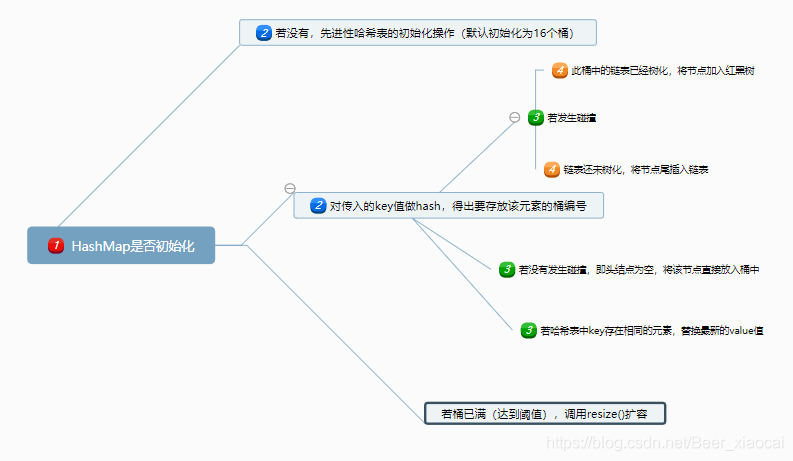
putVal方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断当前哈希表是否初始化
if ((tab = table) == null || (n = tab.length) == 0)
//resize方法完成哈希表的初始化
n = (tab = resize()).length;
//判断以key值哈希后得到的下标的桶,其中是否存在元素(这里就是要保证桶的数量为2^n,因为当n位2^n时 (n-1) & hash 相当于 hash % (n-1))
if ((p = tab[i = (n - 1) & hash]) == null)
//将要保存的节点放在此桶的第一位置
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//判断节点是否处于同一个桶并且key值完全相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//替换头结点
e = p;
//hash(key)桶中元素不为空,判断此桶是否树化
else if (p instanceof TreeNode)
//调用树化后的方法,将新节点添加到红黑树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//桶中元素不为空,并且仍是链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//将新节点链到链表尾部
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断添加元素后的哈希表大小是否超过阈值(而ArrayList是先检查再添加元素)
if (++size > threshold)
//扩容
resize();
afterNodeInsertion(evict);
return null;
}
putValueLogic diagram
5. Frequently Asked Questions
5.1 Why not use the hashCode()calculated key value provided by the Object class as the bucket subscript:
- There is basically no collision. At this time, there is basically no difference between a hash table and an ordinary array.
5.2 Why h >>> 16?
- Because the hash basically performs the hash operation in the upper 16 bits
5.3 Why is the HashMapmedium capacity 2^n?
- Because when n bits are 2^n (n-1) & hash is equivalent to hash% (n-1)