In a relational database, data tables generally disorderly state is stored on disk, in the absence of the corresponding index, to query the data in the table, you can only retrieve the entire table, all the records one by one to read, and then query conditions, it is clear that this approach will lead to a lot of disk I / O operations and CPU computing systems consume a lot of time, therefore, to establish index has become a must consider.
Use CREATE INDEX [index name] on the table names (column names, ......) statements can be established as the most commonly used key index data table, and the key index achieved mostly using B + tree data structure, it has some of the following properties:
1, is a balanced tree, from the root node to the leaf node depth by no more than 1;
2, the non-leaf node only stores pointers and pointers to child nodes key, data is not saved;
3, the leaf node holds the key value, the corresponding record list pointer address and the leaf nodes, the leaf node linked list is ordered key
However, these properties will be able to ensure the query performance to meet user needs? Below, we take time to bank accounts queries, for example, to explore the performance issues of the index.
For convenience of explanation, we are here to simplify the B + tree is the B + tree shown in Fig., To account number and transaction date as a key, as shown below:
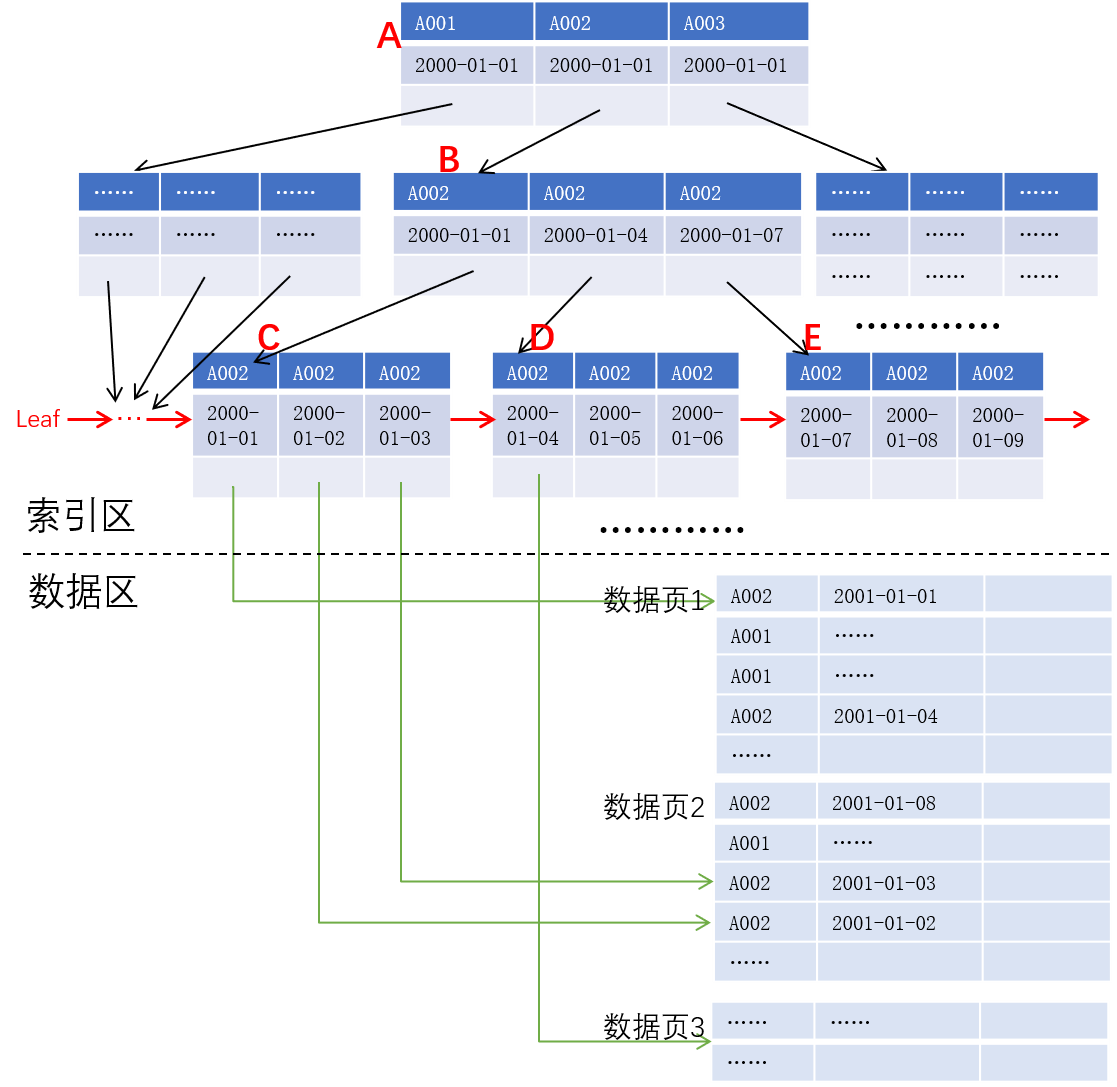
If we want to query account A002 transaction flow from 2000-01-01 to 2000-01-07, the database system will first look accounts for the A002, the leaf node date no earlier than 2000-01-01 keys where results sequentially reading the index blocks a, B, C, and C in the block to find the index key value satisfying the condition of recording address and read records are returned, if the index of the last block C date is earlier than or equal 2001-01- 07, it is possible to directly read the list according to the leaf nodes of the index column D, and so on until a certain date until the index block than 2001-01-07 large.
观察上述过程,我们发现 2000-01-01 对应的记录在数据页 1,2000-01-02 和 2000-01-03 对应的记录在数据页 2,2000-01-04 对应的记录则在数据页 3,4 条记录需要读取 3 个数据页,极端情况下甚至任意一条记录都在不同的数据页,而此时如果数据区中记录已按键值序存储则可以显著减少磁盘 IO。更进一步,如果记录数据直接保存在叶子节点,则可以减少查询过程中索引页与数据页之间的跳读,这对于机械硬盘的性能影响尤甚。
这些问题对于集算器的组表来说,可以非常轻松地得到解决。
我们还是以股票交易数据为例讲解组表的使用。
| A | |
| 1 | =file("d:/test/stktrade.ctx") |
| 2 | =A1.create@r(#sid,#tdate,open,close,volume) |
| 3 | =connect("mysql") |
| 4 | =A3.cursor("select * from stktrade order by sid,tdate") |
| 5 | =A2.append(A4) |
| 6 | =A3.close() |
| 7 | =A2.index(idx1;sid,tdate) |
A2: 创建数据结构为 (sid,tdate,open,close,volume) 的组表,且指定 sid 和 tdate 为键,@r 指定数据按行存储
A5: 将按 sid 和 tdate 有序的数据追加到组表中
A6: 以 sid 和 tdate 为键值建立索引 idx1
| A | |
| 1 | =file("d:/test/stktrade.ctx").create() |
| 2 | =A1.icursor(sid=="600036" && tdate>=date("2018-01-01") && tdate<=date("2018-01-10"),idx1) |
| 3 | =A2.fetch() |
A1: 读取组表
A2: define the query data according to the index idx1 cursor
A3: Remove the cursor in the data
When indexing idx1, may also be required data is stored in the index, for example, you want to open, close, volume 3 which is also stored in the index idx1 years, just in front of the table where A2.index (idx1; sid, tdate) instead A1.index (idx1; sid, tdate; open, close, volume) can be, so that when a query can not read data files, only reads the index file, the query faster.