In " DB - How to Read and Store Data ", we introduced the ways to affect data read, random IO and sequential IO, in " What exactly does the Sql optimizer do for you?" "Introduces some basic factors that affect the query, including the filter factor, the width and size of the index slice, and how the matching column and filter column are applied to the SQL query. In " What is Samsung Index ", the main factors required for index design and the recommended design method are introduced.
Then in this article, we will comprehensively use this knowledge and use two methods to quickly estimate the performance of the current index and the efficiency of the query. From this article you will get the following knowledge: BQ - Basic Question Method QUBE - Quick Upper Limit Estimation Method
table:
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_name` varchar(100) DEFAULT NULL, `sex` int(11) DEFAULT NULL, `age` int(11) DEFAULT NULL, `c_date` datetime DEFAULT NULL, PRIMARY KEY (`id`), # index KEY `id_name_sex` (`id`,`user_name`,`sex`), KEY `name_sex_age` (`user_name`,`sex`,`age`) ) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8;
1. Basic Question Method - BQ
The basic question method, this method must be known to those who use the database. In short, it is whether the index is used in the current select, but the BQ method will be more detailed.
How to evaluate :
Does the existing index or the index in the plan contain all the columns used in the WHERE, that is, the current query, is there an index that is a half-width index (matches all predicate columns after where)? If not, the missing predicate column should be added to the existing index.
Based on the knowledge introduced above, we can know that the half-width index can ensure that the return table access only occurs when all the query conditions are satisfied. That is, conditional filtering happens before the table scan, not after. Although random access to the main table cannot be avoided, at least sequential reads of the index table can be supported.
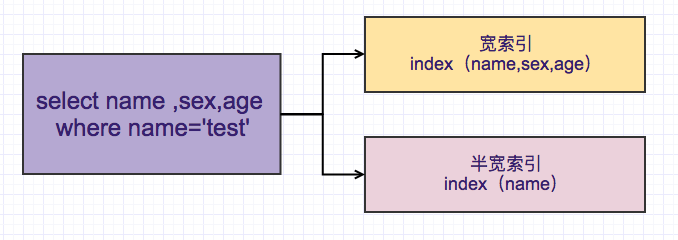
However, sufficient performance is not guaranteed for BQ. For example:
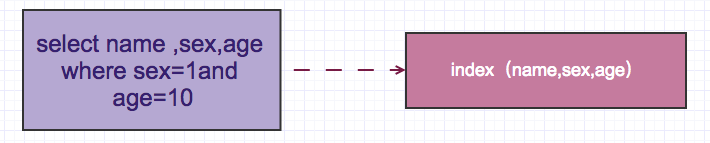
The predicates after where in the above are all included in the index (name, sex, age), but this query is a full index or full table scan, and Samsung does not own one. For specific reasons, you can check out "What exactly does the Sql optimizer do for you?" "Introduction.
So is there a more comprehensive assessment? The following QUBE is a more comprehensive and rapid evaluation method.
2. Quick Estimation Upper Limit Method - QUBE
QUBE is more time-consuming than BQ, but it can reveal all performance issues related to index or table design. The filter factor used by QUBE for each predicate is very close to the actual worst case, so although it will be more pessimistic, it will not miss some problems found like BQ.
The purpose of QUBE is to expose the problem of slow access paths during development. The output of this estimation method is the Local Response Time (LRT) for short.
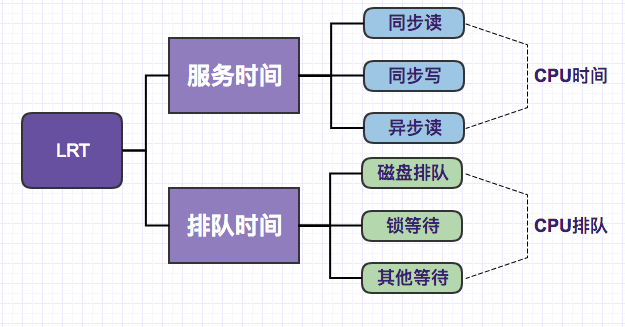
Let us first have a general understanding of the time composition of LRT. In a conventional multi-user environment, the concurrency of programs can lead to all kinds of contention for the required resources, and therefore have to queue up to obtain these resources. Then QUBE ignores all other types of queuing except disk drive queuing, and has provided a simple evaluation process.
After excluding the above factors, what we get is a very simple estimation process that only needs the following variables to deal with.
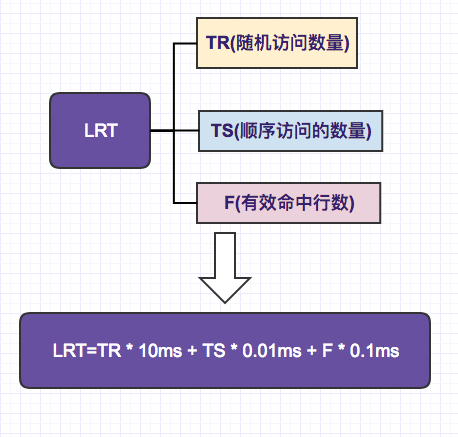
The final QUBE formula is:
LRT=TR * 10ms + TS * 0.01ms + F * 0.1ms
We define the time of random access as 10ms, and the time of sequential read as 0.01ms. This is introduced in " DB - Data Reading and Storage Method ". If you don't know it, you can take a look.
3. Examples
We assume that the table testhas 1000w of data, and also has the following two indexes, one is the joint primary key and the other is the auxiliary index:
Joint primary key: PRIMARY KEY (
id,user_name,sex)Secondary index: KEY
name_sex_age(user_name,sex,age)
1. Example 1 - Auxiliary Index Access
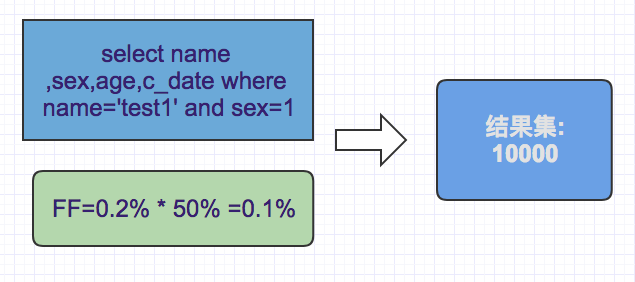
select
user_name,sex,age,c_datefromtestwhereuser_name=’test1’ and sex=1Animal arrangement
user_namesexmatch index
name_sex_age(user_name,sex,age),
Filter factor:
where
user_namethere are 500 distinct values with a filter factor of 0.2% (1/500)where
sexhas 2 different values with a filter factor of 50% (1/2)Combined filter factor = 0.2% * 50% = 0.1% result set = 1000w * 0.2% * 50% = 10000
LRT estimation:
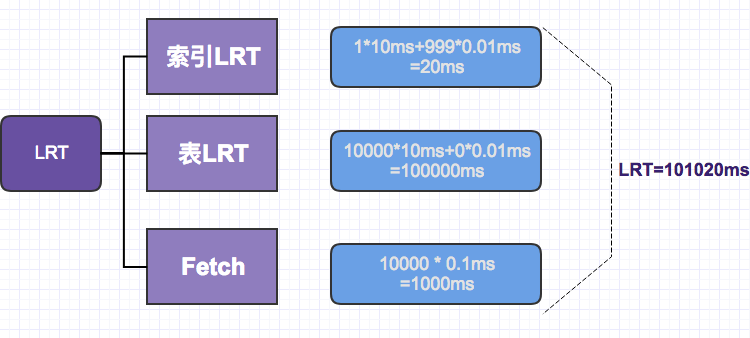
1. Access the index table
The query matches the index name_sex_age( user_name, sex, age), and the filter factor is 0.1%. It needs to scan the index table data, which is 10,000 rows, including 1 random query (the first positioning page) and 9999 sequential queries.
Index LRT:
TR =1 * 10ms=10ms
TS=9999 * 0.01ms=100ms
index_LRT=10ms+100ms=110ms
2. Access the main table
Because the index name_sex_age( user_name, sex, age) is a secondary index and the field 'c_date' is not in the index, a primary table scan is required. This index is not a clustered index, so 10,000 random IO queries are required for back-to-table queries.
Table LRT:
TR=10000 *10ms=100000ms
TS=0 * 0.01ms=0ms
LRT = 100000ms+0ms = 100000ms
3. Total time of LRT
Fetch =10000*0.1ms=1000ms
LRT=Index LRT+Table LRT+Fetch=110ms+100000ms+1000ms=101110ms=101s
The estimated query time for the above query is about 101s. In reality, the speed will be faster than this due to the disk cache and table pre-reading. However, we do not consider these. I can use the estimation of this value to understand the performance of the current query and index for my own judgment and optimization.
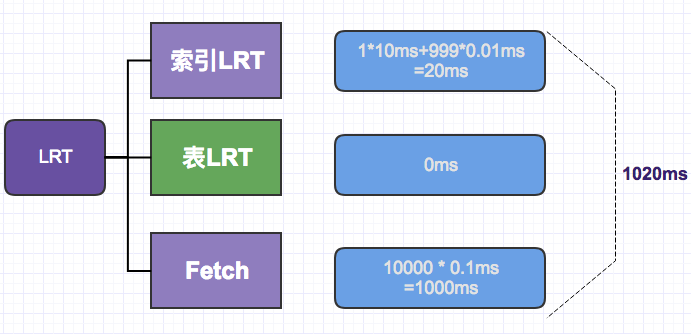
4. Improve & optimize
In the above query, we can see that the most time-consuming place occurs in the main table lookup, because the field 'c_date' is not in the auxiliary index name_sex_age, resulting in too many random accesses.
We can add matching fields ( user_name, sex, age, c_date) to the index, so that we can directly index the table access instead of returning to the table. We can see that the index at this time is a Samsung index. This can save 100000ms, leaving only about 1020ms.
2. Example 2 - Clustered Index Access
select
user_name,sex,age,c_datefromtestwhereuser_name='test1' and sex=1 and id between 1000 and 101000;Animal arrangement
idfilter column
user_namesexMATCH INDEX PRIMARY KEY (
id,user_name,sex)
filter factor
idbetween 1000 and 101000, there are 100000 rows of data.
user_nameThere are 500 distinct values with a filter factor of 0.2% (1/500)
sexThere are 2 different values with a filter factor of 50% (1/2)Combined filter factor = 0.2% * 50% = 0.1%
Result set = 10w * 0.2% * 50% = 100
LRT estimation:
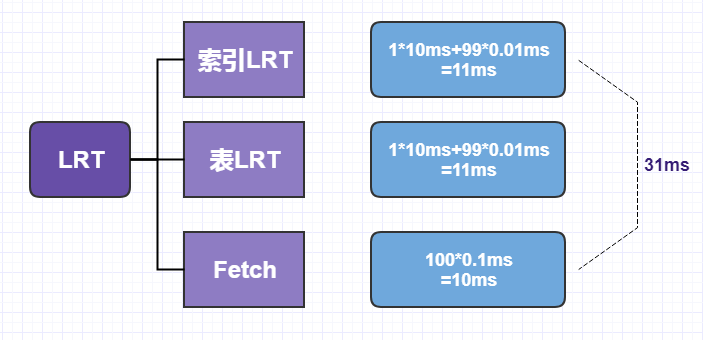
Since the index we applied this time is the primary key index (that is, the dinner index (engine innodb)), when my table LRT is accessed, it is a sequential access, not a random IO access.
LRT = Index LRT + Table LRT + Fetch = 11ms + 11ms + 10ms = 31ms