Ultra-Scalable Spectral Clustering and Ensemble Clustering
1.Abstract:
In the U-SPEC, the sparse structure for similar sub-matrix presented on behalf of a hybrid selection strategy and k - nearest neighbor method fast approaching representatives. Sparse similarity matrix is interpreted as two sub-view of the cutting transfer using FIG effective segmentation, clustering results:
In the U-SENC, a plurality of U-SPEC clustering is further integrated into an integrated cluster frame, while maintaining an efficient improves the robustness of the U-SPEC. Integrated multi-U-SEPC s generated based on the bipartite graph structure between a target and a new base cluster, and dividing its effective to achieve consistent clustering results
U-SPEC having a U-SENC and complexity near linear time and space
2.Inrtoduction
Spectral clustering processing because of its good capacity separable nonlinear data sets, however, a key limitation of the conventional spectral clustering is its great complexity in time and space; consumption generally comprises two spectral clustering time and memory consuming phase, i.e., similarity matrix construct and decomposition characteristics. Construction similarity matrix generally requires 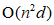 time and
time and 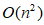 memory, problem solving eigen decomposition requires
memory, problem solving eigen decomposition requires 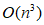 time and
time and 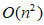 memory, where N is the data size, d is the dimension. As the amount of data N, spectral clustering calculation amount also increases.
memory, where N is the data size, d is the dimension. As the amount of data N, spectral clustering calculation amount also increases.
To reduce the computational burden huge spectral clustering strategy is used: 1. thinning similarity matrix, with sparse solvers Eigen Decomposition of features. Sparse matrix strategy can reduce the cost of the memory matrix memory, to facilitate decomposition characteristics, still we need to calculate all the original similarity matrix. 2. The sub-matrix is constructed based on: p representative selected randomly from the raw data, to build a similar submatrix n * p, landmark based spectral clustering (LSC) method on the data set performs k-means, as the cluster centers to give p p delegates. However, these are usually sub-matrix by spectral clustering method based on limiting the complexity of the bottleneck (N * p), which is a critical obstacle to large scale data processing are set, the data focus on large scale, usually in order to obtain a better approximation the need for greater p. In addition, the clustering results of these methods rely heavily on one approach (approximation of the actual n * n matrix) sub-matrix, which resulted in robust clustering instability.
This paper proposes two new large-scale algorithm, ultra-scalable spectral clustering (U-SPEC) and ultra-scalable integrated clustering (U-SENC). In the U-SPEC proposes a representative of a new hybrid selection strategy, efficiently find a representative set of p, based on k-means from reducing the selection 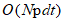 to
to 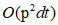 the time complexity. Then, a method for designing a fast approaching the K-nearest, having effectively establish a
the time complexity. Then, a method for designing a fast approaching the K-nearest, having effectively establish a 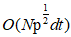 time and
time and  a sparse memory sub-matrix. Submatrix as sparse cross-affinity matrix, set between the data set representing the configuration of bipartite graph. Calculated matrix decomposition problem of excessive by two configuration FIG transfer cut, finally, using the k-means method to construct a discrete clustering result k eigenvectors, the process time-consuming
a sparse memory sub-matrix. Submatrix as sparse cross-affinity matrix, set between the data set representing the configuration of bipartite graph. Calculated matrix decomposition problem of excessive by two configuration FIG transfer cut, finally, using the k-means method to construct a discrete clustering result k eigenvectors, the process time-consuming 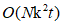 . Integration: Furthermore, in order to go beyond the U-SPEC-time approximation, providing better clustering robust, U-SENC proposed algorithm, a plurality of U-SPEC clustering integrated into a single integrated clustering framework time and space complexity of the frame is mainly composed
. Integration: Furthermore, in order to go beyond the U-SPEC-time approximation, providing better clustering robust, U-SENC proposed algorithm, a plurality of U-SPEC clustering integrated into a single integrated clustering framework time and space complexity of the frame is mainly composed  and
and 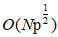 controlled.
controlled.
which is:
New hybrid representing the selected strategy: find p delegates
K-nearest fast approaching method is: the establishment of a sub-np sparse matrix
The bipartite graph transfer cut: np submatrix will be interpreted as a bipartite graph and its effective segmentation, final clustering result
3.PROPOSED FRAMEWORK
3.1 represents the new hybrid selection strategy:
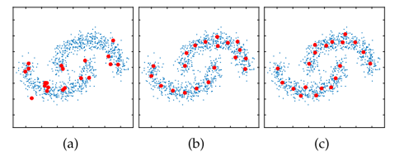
FIG1: a red dot FIG randomly selected as the representative point, panel b is selected from the representative point k_means centroid, c is a mixing method results in FIG.
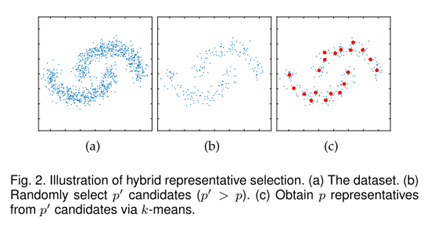
While representing the selected random computationally efficient, but the inherent randomness may cause a group representing a low quality; and k_means Processed; mixing method is to start and the total data set is randomly selected part of the data, and then the extracted partial data with Science k_means the p centroid as a representative. FIG. 2.
 3.2 Approximation of K-Nearest Representatives
3.2 Approximation of K-Nearest Representatives
After obtaining p delegates, the next goal is to encode the entire data set twenty-two relations representative by p,
The method of the conventional sub-matrix representation, Np between the object and the sub-matrices represent like need O (Npd) time and O (Np) of memory; subsequently presented withK-Nearest np sparse similarity matrix (each object is only representative of its k nearest connected), however, it is still necessary to calculate all the N objects to the distance between the p representative. In addition to the total number Np term calculation, the thinning step further consumption O (NpK) time; (Ps: Note that legacy knn and K-Nearest have common features, but faces different problems in practical use; in structural problems submatrix traditional knn not applicable, because the structure is much less than the unbalanced p N.)
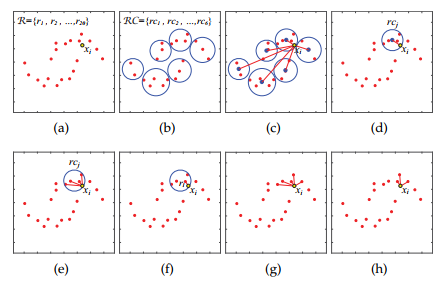
In order to break the efficiency bottleneck, the key issue here is how to build the sub-matrix for the representative K-Nearest to significantly reduce the computational these intermediate terms, we propose a method based on the coarse to fine mechanism K-Nearest represents approximation method, and using this method to establish sub-sparse affinity matrix
: Our k - nearest neighbor representative of the approximate area of the main idea is to find the nearest neighbor (the p representative points clustering, sample and calculate the distance P cluster centers recently elected cluster), then in the nearest neighbor find the nearest representative (defined as the area  ) (calculated nearest point in a recent representative cluster), and finally in
) (calculated nearest point in a recent representative cluster), and finally in 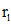 the neighborhood to find the k - nearest neighbors representatives (in the vicinity of the point k values recently as the selected point).
the neighborhood to find the k - nearest neighbors representatives (in the vicinity of the point k values recently as the selected point).
3.3 Bipartite Graph Partitioning
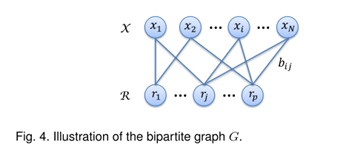
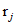 : Represents the j-th
: Represents the j-th
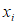 : I-th sample
: I-th sample
This is part of the continued