https://blog.csdn.net/girlgolden/article/details/89226528
MySQL asynchronous replication and semi-sync semi-sync, they are based on MySQL the binlog, native replication is completely asynchronous, master necessarily guarantee slave receives and executes the binlog, to ensure master maximum performance, but the slave may be a delay, standby data can not guarantee the consistency, if the master goes down, lifting slave for the new main library, you will lose data under the premise of non-stop services.
semi-sync in asynchronous replication of data protection based on the increase of consideration, so that the slave master must confirm receipt binlog (but does not guarantee the slave execute the transaction) to finally commit the transaction, if more binding MHA (Master High Availability) High after architecture available, hang after this time master, slave relay log can be finished in all apply to the master switch to provide read and write services.
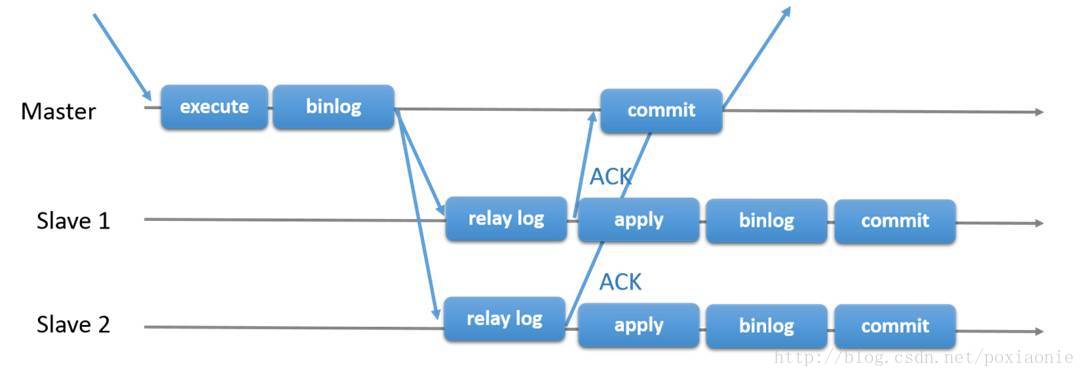
semi-sync works semi-sync, as shown in FIG.
Primal respect MySQL replication and semi-sync semi-sync, the differences Group Replication is fully synchronous replication:
- Fully synchronous replication, standby without delay, the other two nodes can provide services immediately after a node goes down, while the semi-sync need to apply (execution) When all relay log, and relies on third-party software to achieve high availability data is not lost;
- Transaction conflict detection ensure data consistency, multiple nodes can simultaneously read and write data, data access can be greatly simplified;
- Row-level parallel replication, MySQL 5.7 / MariaDB before 10.0 slave sql only one thread, this long criticized, is the main cause behind the master of the slave.
1, Group Replication Works
Using replication-based authentication, the process as shown below:
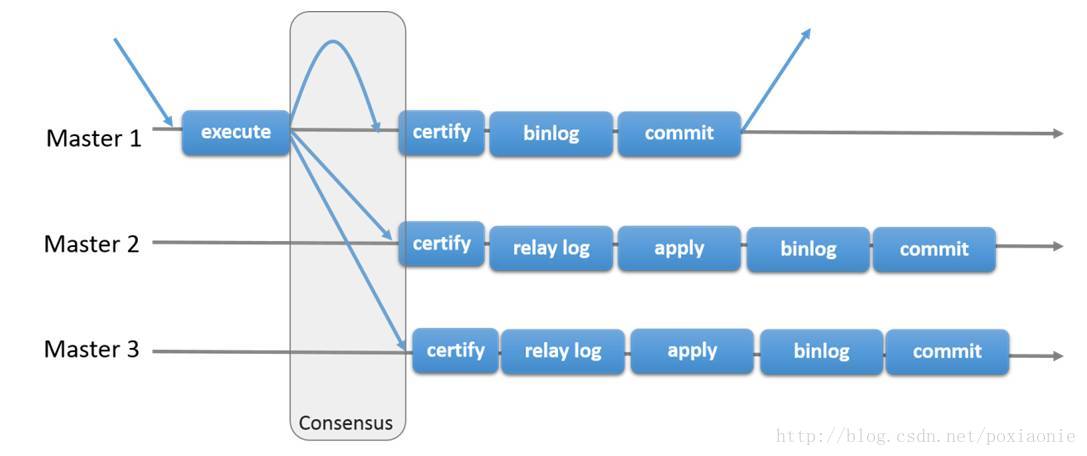
当客户端发起commit命令时(此时仍然没有发生真正的commit),所有本事务内对数据库的更改行的主键都会被搜集到一个写入集(writeset)中,该写入集随后会被复制到其他节点,该写入集会在每个节点上使用搜索到的主键进行确认性认证测试来判断该写入集是否可以被应用。如果认证测试失败,写入集会被丢弃并且原始事务会被回滚;如果认证成功,事务会被提交并且写入集会被在剩余节点进行应用。最终,这意味着所有服务器以相同的顺序接收同一组事务。
其他节点只要验证成功了,就会返回成功的信号,即使当前数据并没有真正的写入当前节点,固这里的全同步复制,其实是虚拟的全同步复制。这段时间内,数据是有延迟的,但很小,如果应用程序访问的是远端节点,读到的数据是未改变之前的旧数据。固在生产环境里,对数据延迟要求很苛刻的情况下,建议在一个主节点上读写,避免造成数据不一致的情况发生。
(注:Galera通过设置参数wsrep_causal_reads = ON可以避免,这种情况下需要等待远端节点应用完事务后,才返回客户端读取请求,这将增加读取的响应时间。Group Replication未发现相关参数,如有朋友知道也请告知。)
而真正意义上的全同步复制,是要等所有节点事务都提交落地,才成功返回客户端。因此虚拟全同步复制的性能会更好一些。
Group Replication内部实现了flow control限流措施,作用就是协调各个节点,保证所有节点执行事务的速度大于队列增长速度,从而避免丢失事务。实现原理和简单:整个Group Replication集群中,同时只有一个节点可以广播消息(数据),每个节点都会获得广播消息的机会(获得机会后也可以不广播),当慢节点的待执行队列超过一定长度后,它会广播一个FC_PAUSE消息,所以节点收到消息后都会暂缓广播消息并不提供写操作,直到该慢节点的待执行队列长度减小到一定长度后,Group Replication数据同步又开始恢复。
变量参数:
-
group_replication_flow_control_applier_threshold = 25000
-
group_replication_flow_control_certifier_threshold = 25000
待执行队列长度超过该值时,flow control被触发,默认是25000。
2、Group Replication的特性和注意事项
- 全同步复制,事务要么在所有节点都提交,要么都回滚;
- 多主复制,可以在任意节点进行写操作;
- 在从服务器上并行应用事件,真正意义上的并行复制;
- 节点自动配置–故障节点自动从集群中移除,当故障节点再次加入集群,无需手工备份当前数据库并拷贝至故障节点;
- 应用程序的兼容性:无需更改应用程序,原生的MySQL接口;
- 生产环境上集群推荐配置3个节点; 每个节点都包含完整的数据副本;
- 各个节点的同步复制,通过GTID binlog ROW实现。
优点:
- 真正的多主架构,任何节点都可以进行读写,无需进行读写分离;(注:生产环境建议只在一台机器上写,由于集群是乐观锁并发控制,事务冲突的情况会在commit阶段发生。如果有两个事务在集群中不同的节点上对同一行写入并提交,失败的节点将回滚,客户端返回报错,作为DBA你不想被一群开发投诉的话,还是默默的开启Single-Primary写入模式)
- 无集中管理,可以在任何时间点失去任何一个节点,集群将正常工作不受影响;
- 节点宕机不会导致数据丢失;
- 对应用透明。
缺点:
- 加入新节点,开销大,需要复制完整的数据。
- 不能有效的解决写扩展问题,磁盘空间满了,无法自动扩容,不能像MongoDB分片那样自动移动chunk做balance
- 有多少个节点就有多少份重复的数据
- 由于事务提交需要跨节点通讯(分布式事务),写入会比主从复制慢
- 对网络要求非常高,如果网络出现波动或机房被ARP攻击,造成两个节点失联,Group Replication集群发生脑裂,服务将不可用。
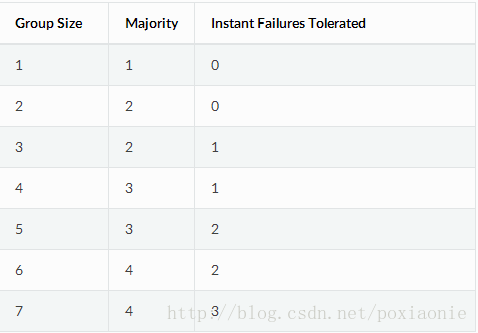
下面是官方集群节点投票示意图,如果是3个节点,必须满足大多数节点2个投票:
集群自身不提供VIP机制,也没有像MongoDB副本集那样提供JAVA/PHP客户端API接口实现故障切换(需要开发自己写,成本较高),需要结合第三方HaProxy软件(建议2块网卡做bond0)+自定义脚本实现秒级故障切换,另通过代理方式,性能会降低,因为多了一层网络转发。
局限性:
- 目前的复制仅仅支持InnoDB存储引擎
- 每张表必须有主键
- 只支持ipv4网络
- 集群最大支持9个节点
- 不支持Savepoints
- 不支持SERIALIZABLE隔离级别在Multi-Primary多主模式
- 不支持外键在Multi-Primary多主模式
- 整个集群的写入吞吐量是由最弱的节点限制,如果有一个节点变得缓慢,比如硬盘故障(RAID10坏了一块盘),那么整个集群将是缓慢的。为了稳定的高性能要求,所有的节点应使用统一的硬件。
3、Group Replication的使用
Single-Primary模式配置环境:
1、设置host解析
三台服务器的配置如下:
-
# cat /etc/hosts
-
192.168.17.133 node1
-
192.168.17.134 node2
-
192.168.17.135 node3
2、编辑/etc/my.cnf配置参数(三个节点按照如下设置)
-
log-bin = /data/mysql57/binlog/mysql-bin
-
binlog_format = ROW
-
sync_binlog = 1
-
binlog_checksum = NONE
-
log_slave_updates = 1
-
gtid_mode = ON
-
enforce_gtid_consistency = ON
-
master_info_repository = TABLE
-
relay_log_info_repository = TABLE
3、安装插件
INSTALL PLUGIN group_replication SONAME 'group_replication.so';- 1
4、设置集群参数(三个节点都执行)
注:group_replication_group_name名字要通过select uuid()来生成
group_replication_local_address在节点2和节点3上改成本地IP地址
执行完了,别忘了修改my.cnf里加入到配置文件里。
5、节点加入集群
Primary节点上执行
注:待replication_group_members表查询结果MEMBER_STATE字段状态为ONLINE,再执行关闭初始化。
两台Secondary上执行
-
SET SQL_LOG_BIN=0;
-
GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'repl'@'%' IDENTIFIED BY 'repl';
-
FLUSH PRIVILEGES;
-
SET SQL_LOG_BIN=1;
-
CHANGE MASTER TO MASTER_USER='repl',
-
MASTER_PASSWORD= 'repl' FOR CHANNEL
-
'group_replication_recovery';
-
START GROUP_REPLICATION;
-
select * from performance_schema.replication_group_members;
As shown below, represents the cluster has been running successfully.

4, Group Replication maintenance
If the Secondary node goes down, for various reasons after the restart to join the cluster fails, it is required to restore, follow these steps:
1, on the other node Secondary total amount mysqldump
-
mysqldump -uroot -p123456 -q --single-transaction
-
--master-data=2 -B yourDB > /root/yourDB.sql
This step will be automatically generated in yourDB.sql
SET @@GLOBAL.GTID_PURGED='23e510dc-d30b-11e6-a4c6-b82a72d18b06:1,4d1fd6ec-d2fd-11e6-ae4b-549f3503ab31:1-1543112:2003786-2003789:3003787,e4e34dd3-d2fa-11e6-984b-b82a72d18b06:1';2, introduced into
Then execute the following statement to
-
CHANGE MASTER TO MASTER_USER='repl',
-
MASTER_PASSWORD= 'repl' FOR CHANNEL
-
'group_replication_recovery';
-
START GROUP_REPLICATION;