Spark Streaming Flume to integrate push mode and a pull mode by two modes
push mode: Spark Streaming end will start to receive a avro sink Flume is based on the data sent by the Receiver Avro Socket Server, this is the time Flume avro sink as a client
pull mode: This mode is a customized Spark Flume the sink as Avro Server, the data sent to the flume to collect the sink, and the sink data stored in the cache, and then start with Spark Streaming Avro Client from the Recevier since the sink Flume defined pulls data. Relative to the push mode, which is more reliable without losing data, this is because of two reasons:
1, Receiver pull model is a reliable Receiver, the Receiver is received data, and stores this data and sends a backup after ack response to the sink Flume
2, the transaction characteristics combined Flume to ensure that the data is not lost, will pull the data, if there is no pull successful (that is, Flume Sink does not receive ack Receiver sent), then the transaction fails
4 demo understand Flume
1, netcat data to display console
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name agent1 -Dflume.root.logger=INFO,console
## 定义 sources、channels 以及 sinks agent1.sources = netcatSrc agent1.channels = me moryChannel agent1.sinks = loggerSink ## netcatSrc 的配置 agent1.sources.netcatSrc.type = netcat agent1.sources.netcatSrc.bind = localhost agent1.sources.netcatSrc.port = 44445 ## loggerSink 的配置 agent1.sinks.loggerSink.type = logger ## memoryChannel 的配置 agent1.channels.memoryChannel.type = memory agent1.channels.memoryChannel.capacity = 100 ## 通过 memoryChannel 连接 netcatSrc 和 loggerSink agent1.sources.netcatSrc.channels = memoryChannel agent1.sinks.loggerSink.channel = memoryChannel
2, the data saved to the HDFS netcat, respectively, and use the memory file channal
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name agent1
telnet localhost 44445
## 定义 sources、channels 以及 sinks agent1.sources = netcatSrc agent1.channels = memoryChannel agent1.sinks = hdfsSink ## netcatSrc 的配置 agent1.sources.netcatSrc.type = netcat agent1.sources.netcatSrc.bind = localhost agent1.sources.netcatSrc.port = 44445 ## hdfsSink 的配置 agent1.sinks.hdfsSink.type = hdfs agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9999/user/hadoop-twq/spark-course/steaming/flume/%y-%m-%d agent1.sinks.hdfsSink.hdfs.batchSize = 5 agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true ## memoryChannel 的配置 agent1.channels.memoryChannel.type = memory agent1.channels.memoryChannel.capacity = 100 ## 通过 memoryChannel 连接 netcatSrc 和 hdfsSink agent1.sources.netcatSrc.channels = memoryChannel agent1.sinks.hdfsSink.channel = memoryChannel
3, save the log file data to HDFS
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name agent1
echo testdata >> webserver.log
## 定义 sources、channels 以及 sinks agent1.sources = logSrc agent1.channels = fileChannel agent1.sinks = hdfsSink ## logSrc 的配置 agent1.sources.logSrc.type = exec agent1.sources.logSrc.command = tail -F /home/hadoop-twq/spark-course/steaming/flume-course/demo3/logs/webserver.log ## hdfsSink 的配置 agent1.sinks.hdfsSink.type = hdfs agent1.sinks.hdfsSink.hdfs.path = hdfs://master:9999/user/hadoop-twq/spark-course/steaming/flume/%y-%m-%d agent1.sinks.hdfsSink.hdfs.batchSize = 5 agent1.sinks.hdfsSink.hdfs.useLocalTimeStamp = true ## fileChannel 的配置 agent1.channels.fileChannel.type = file agent1.channels.fileChannel.checkpointDir = /home/hadoop-twq/spark-course/steaming/flume-course/demo2-2/checkpoint agent1.channels.fileChannel.dataDirs = /home/hadoop-twq/spark-course/steaming/flume-course/demo2-2/data ## 通过 fileChannel 连接 logSrc 和 hdfsSink agent1.sources.logSrc.channels = fileChannel agent1.sinks.hdfsSink.channel = fileChannel
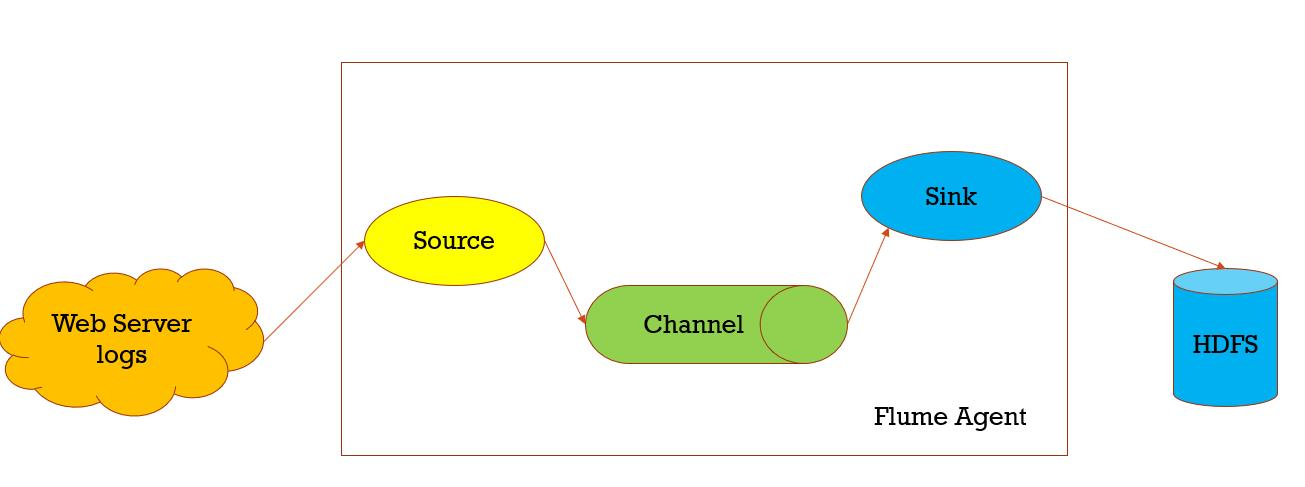
Data collection, to a storage structure, event sent from a data source manner through channels, Sink

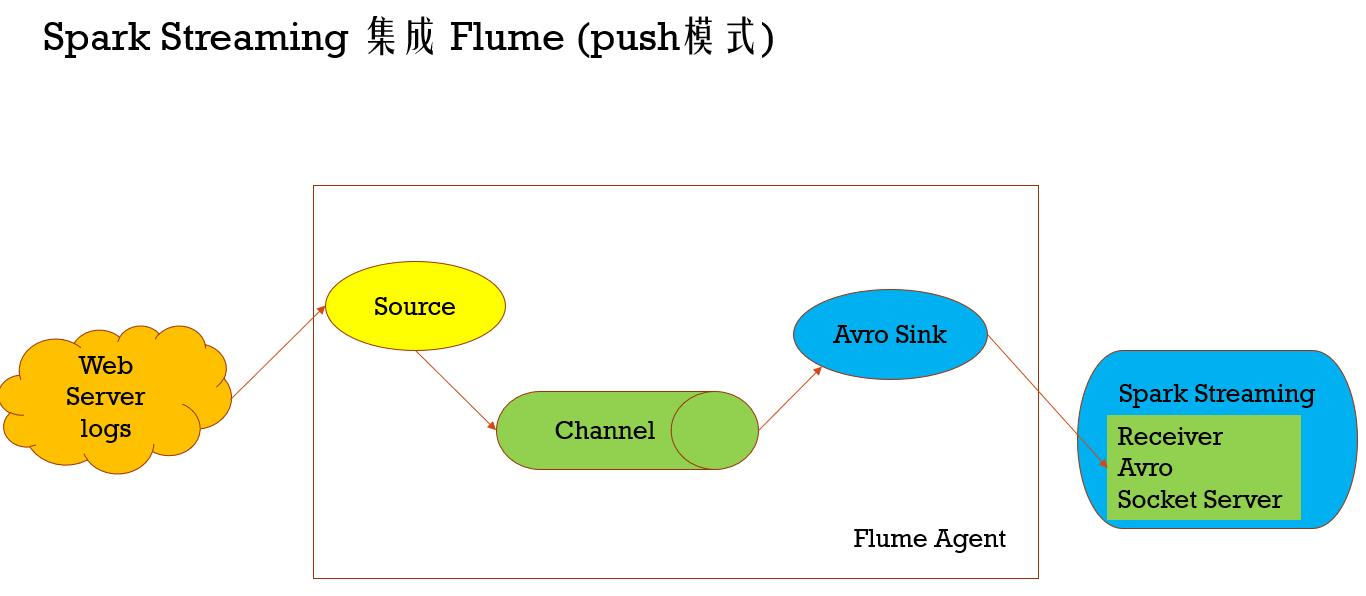
Spark Streaming integrated Flume (push mode)
Spark Streaming Flume to integrate push mode and a pull mode by two modes
push mode: Spark Streaming end will start to receive a avro sink Flume is based on the data sent by the Receiver Avro Socket Server, this is the time Flume avro sink as a client
pull mode: This mode is a customized Spark Flume the sink as Avro Server, the data sent to the flume to collect the sink, and the sink data stored in the cache, and then start with Spark Streaming Avro Client from the Recevier since the sink Flume defined pulls data. Relative to the push mode, which is more reliable without losing data, this is because of two reasons:
1, Receiver pull model is a reliable Receiver, the Receiver is received data, and stores this data and sends a backup after ack response to the sink Flume
2, the transaction characteristics combined Flume to ensure that the data is not lost, will pull the data, if there is no pull successful (that is, Flume Sink does not receive ack Receiver sent), then the transaction fails
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.flume._
import org.apache.spark.util.IntParam
/**
* Produces a count of events received from Flume.
*
* This should be used in conjunction with an AvroSink in Flume. It will start
* an Avro server on at the request host:port address and listen for requests.
* Your Flume AvroSink should be pointed to this address.
*
* Flume-style Push-based Approach(Spark Streaming作为一个agent存在)
*
* 1、在slave1(必须要有spark的worker进程在)上启动一个flume agent
* bin/flume-ng agent -n agent1 -c conf -f conf/flume-conf.properties
*
* 2、启动Spark Streaming应用
spark-submit --class com.twq.streaming.flume.FlumeEventCountPushBased \
--master spark://master:7077 \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 4 \
--executor-cores 2 \
/home/hadoop-twq/spark-course/streaming/spark-streaming-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar \
172.26.232.97 44446
3、在slave1上 telnet slave1 44445 发送消息
*/
object FlumeEventCountPushBased {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println(
"Usage: FlumeEventCount <host> <port>")
System.exit(1)
}
val Array(host, port) = args
val batchInterval = Milliseconds(2000)
// Create the context and set the batch size
val sparkConf = new SparkConf().setAppName("FlumeEventCount")
val ssc = new StreamingContext(sparkConf, batchInterval)
// Create a flume stream
val stream: DStream[SparkFlumeEvent] = FlumeUtils.createStream(ssc, host, port.toInt, StorageLevel.MEMORY_ONLY_SER_2)
// Print out the count of events received from this server in each batch
stream.count().map(cnt => "Received " + cnt + " flume events." ).print()
ssc.start()
ssc.awaitTermination()
}
}
org.apache.spark.SparkConf Import
Import org.apache.spark.streaming._
Import org.apache.spark.streaming.flume._
Import org.apache.spark.util.IntParam
/ **
* Produces A COUNT of Events Received from The Flume.
*
* This Should BE Used in conjunctions of with The the Spark Sink running in a The Flume Agent. See
* The the Spark Streaming Programming Guide for More Details.
*
* the Pull-based Approach the using a the Custom Sink (the Spark Streaming as a Sink present)
*
* 1, the jar package scala-library_2.11.8.jar (here we must note whether there are other versions of the scala under classpath flume, and if so, then deleted, with this, there will be general, because flume dependence kafka, kafka dependent Scala),
* Commons-lang3-3.5.jar, Spark-Streaming-Flume-sink_2.11-2.2.0.jar
* Under placed on the master /home/hadoop-twq/spark-course/streaming/spark-streaming-flume/apache-flume-1.8.0-bin/lib
*
* 2, configuration / home / hadoop-twq / spark -course / Streaming / Spark-Streaming-Flume / Flume-Apache-1.8.0-bin / the conf / flume-conf.properties
*
*. 3, the starting Flume Agent
* bin / Flume AGENT1 -C -n-ng the conf Agent - conf f / flume-conf.properties
*
* 4, starting Spark Streaming use
the Spark-the Submit --class com.twq.streaming.flume.FlumeEventCountPullBased \
--master the Spark: // Master: 7077 \
the --deploy the MODE-Client \
Memory-512M --driver \
--executor-Memory 512M \
--total-Executor. 4-Cores \
--executor-2 Cores \
/home/hadoop-twq/spark-course/streaming/spark-streaming-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar \
master 44446
3、在master上 telnet localhost 44445 发送消息
*/
object FlumeEventCountPullBased {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println(
"Usage: FlumePollingEventCount <host> <port>")
System.exit(1)
}
val Array(host, port) = args
val batchInterval = Milliseconds(2000)
// Create the context and set the batch size
val sparkConf = new SparkConf().setAppName("FlumePollingEventCount")
val ssc = new StreamingContext(sparkConf, batchInterval)
// Create a flume stream that polls the Spark Sink running in a Flume agent
val stream = FlumeUtils.createPollingStream(ssc, host, port.toInt)
// Print out the count of events received from this server in each batch
stream.count().map(cnt => "Received " + cnt + " flume events." ).print()
ssc.start()
ssc.awaitTermination()
}
}