1. Single proxy flow configuration
1.1 Introduction to the official website
http://flume.apache.org/FlumeUserGuide.html#avro-source
Link the source and sink through a channel. Sources, sinks and channels need to be listed, for a given proxy, and then point to sources and sinks and channels. An instance of a source can specify multiple channels, but only one instance of a sink. The format is as follows:

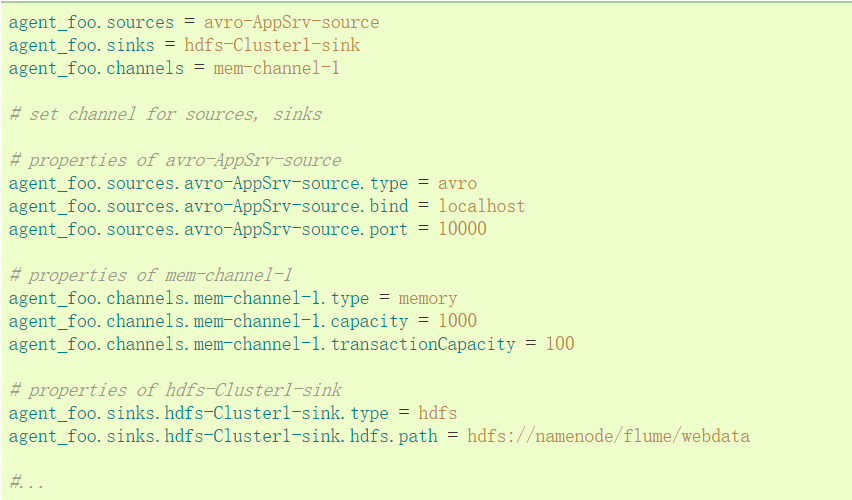
Example analysis: an agent named agent_foo, externally through the avro client, and sends data to hdfs through the memory channel. The configuration file foo.config might look like this:

Case note: This will make the event flow from avro-appserver-src-1 to hdfs-sink-1 through memory channel mem-channel-1. When the proxy starts foo.config as its configuration file, it instantiates the stream.
Configure individual components
After defining the stream, the properties of each source, sink and channel need to be set. Component properties can be set individually.

The "type" property must be set for each component to know what kind of object it needs. Each source, sink and channel type has its own set of performance it needs to function as intended. All of these must be set as required. In the previous example, from the stream in hdfs-sink-1 to HDFS, the avro-appserver-src-1 source through the memory channel mem-channel-1. Below is an example showing the configuration of these components.
1.2 Test Example (1)
Use flume to monitor a directory, and output the contents of the file to the console when there are new files in the directory.
#Configure an agent, the name of the agent can be customized (such as a1)
#Specify the agent's sources (such as s1), sinks (such as k1), channels (such as c1)
#Specify the names of the agent's sources, sinks, and channels respectively. The names can be customized
a1.sources = s1
a1.sinks = k1
a1.channels = c1
#describe source
#Configure directory scource
a1.sources.s1.type =spooldir
a1.sources.s1.spoolDir =/home/hadoop/logs
a1.sources.s1.fileHeader= true
a1.sources.s1.channels =c1
#Configure sink
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
#Configure channel (memory as cache)
a1.channels.c1.type = memory
start command
[hadoop@hadoop1 ~]$ flume-ng agent --conf conf --conf-file /home/hadoop/apps/flume/examples/case_spool.properties --name a1 -Dflume.root.logger=INFO,console
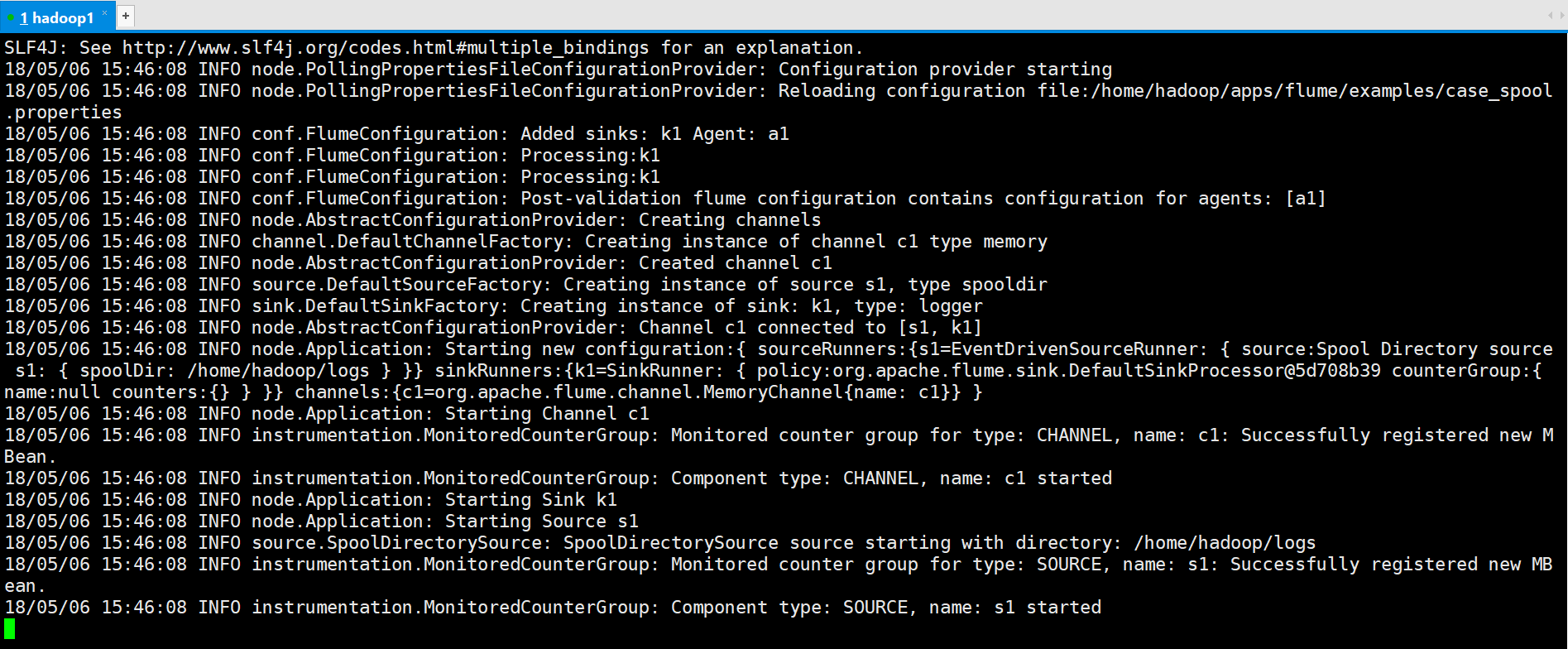
Move 123.log to the logs directory

operation result

1.3 Test case (2)
Case 2: Real-time simulation of reading data from a web server to hdfs
Use exec source here to refer to http://www.cnblogs.com/qingyunzong/p/8995554.html for details
Inside the 2.3Exec Source introduction
2. Single-agent multi-stream configuration
A single Flume agent can contain several independent streams. You can list multiple sources, sinks and channels in one configuration file. These components can be connected to form multiple streams.
Sources and sinks can be connected to their corresponding channels to set up two different streams. For example, if you need to set up an agent_foo to proxy two streams, one from an external Avro client to HDFS, and one to tail the output to an Avro sink, then make a configuration here
2.1 Official case

Third, configure the multi-agent process
Setting up a multi-layer stream requires a first-hop avro sink that points to the next-hop avro source. This will cause the first Flume agent to forward the event to the next Flume agent. For example, if files are sent periodically, per event (1 file) AVRO client uses a local Flume proxy, then this local proxy can be forwarded to another proxy that has storage.
The configuration is as follows
3.1 Official Case
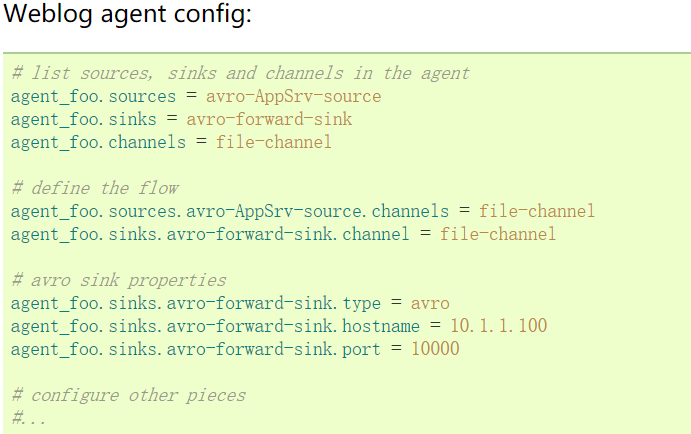
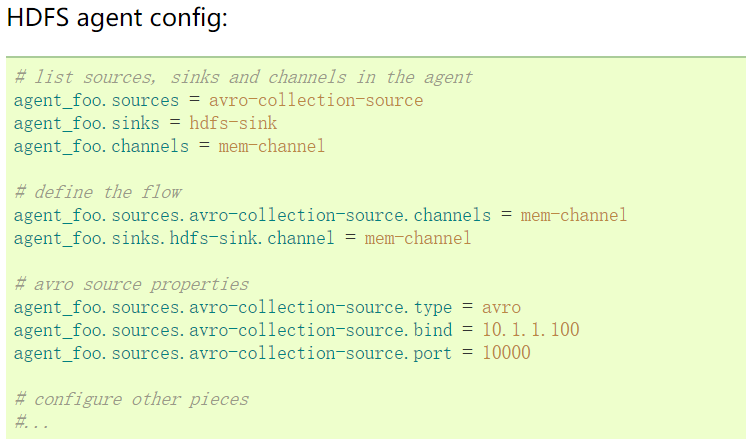
This connects the collection source from avro-forward-sink of weblog-agent to avro-collection-source of hdfs-agent. The eventual result from an external source appserver is ultimately stored in HDFS.
3.2 Test case
case_avro.properties
a1.sources = s1
a1.sinks = k1
a1.channels = c1
a1.sources.s1.type = avro
a1.sources.s1.channels = c1
a1.sources.s1.bind = 192.168.123.102
a1.sources.s1.port = 22222
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
case_avro_sink.properties
a2.sources = s1
a2.sinks = k1
a2.channels = c1
a2.sources.s1.type = syslogtcp
a2.sources.s1.channels = c1
a2.sources.s1.host = 192.168.123.102
a2.sources.s1.port = 33333
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = 192.168.123.102
a2.sinks.k1.port = 22222
a2.sinks.k1.channel = c1
Description: case_avro_sink.properties is the previous Agent, case_avro.properties is the latter Agent
#Start Avro 's Source first and listen to the port
[hadoop@hadoop1 ~]$ flume-ng agent --conf conf --conf-file ~/apps/flume/examples/case_avro.properties --name a1 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true
#Restart Avro 's Sink
flume-ng agent --conf conf --conf-file ~/apps/flume/examples/case_avro_sink.properties --name a2 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true
You can see that the connection has been established

#Generate test log on Avro Sink
[hadoop@hadoop1 ~]$ echo "hello flume avro sink" | nc 192.168.123.102 33333

View other results

4. Multiplexing Streams
Flume supports fanout streams from one source to multiple channels. There are two modes of fanout, replication and multiplexing. Events in the replication stream are sent to all configured channels. In the case of multiplexing, events are sent to only a subset of eligible channels. Fanout flow requires rules specifying source and fanout channels. This is done by adding a channel "select" that can be duplicated or multiplexed. Go further and specify the selection rule, if it is a multiplexer. If you don't specify a selection, it copies by default.
The properties of the multiplexed selection set are further forked. This requires specifying an event attribute to map to a set of channels. Select each event header check in the configuration properties. If the specified value matches, then the event is sent to all channels mapped to that value. If there is no match, then the event is sent to the channel set to the default configuration.
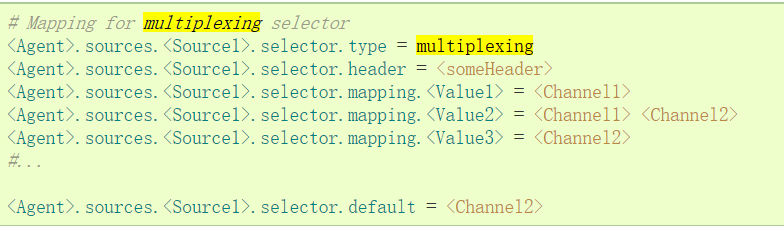
Mapping allows each value channel to overlap. The default value can contain any number of channels. The example below has a single stream multiplexing two paths. The proxy has a single avro source and two channels connecting the two sinks.
4.1 Official Case
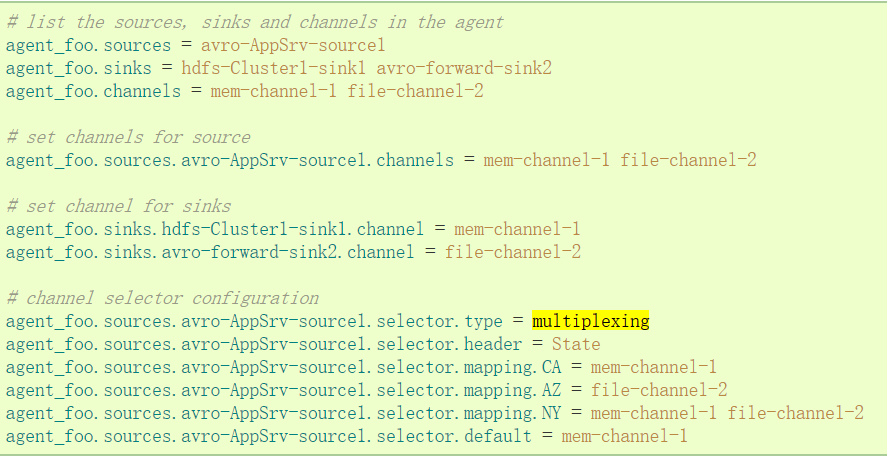
"State" as a selection check for Header. If the value is "CA" then send it to mem-channel-1, if it's "AZ" then jdbc-channel-2, if it's "NY" then send it to both. If the "State" header is not set or does not match any of the three, then go to the default mem-channel-1 channel.
4.2 Test Case (1) Replication
case_replicate_sink.properties
a1.sources = s1
a1.sinks = k1 k2
a1.channels = c1 c2
a1.sources.s1.type = syslogtcp
a1.sources.s1.channels = c1 c2
a1.sources.s1.host = 192.168.123.102
a1.sources.s1.port = 6666
a1.sources.s1.selector.type = replicating
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.123.102
a1.sinks.k1.port = 7777
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.123.102
a1.sinks.k1.port = 7777
a1.sinks.k1.channel = c2
case_replicate_s1.properties
a2.sources = s1
a2.sinks = k1
a2.channels = c1
a2.sources.s1.type = avro
a2.sources.s1.channels = c1
a2.sources.s1.host = 192.168.123.102
a2.sources.s1.port = 7777
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
a2.sinks.k1.type = logger
a2.sinks.k1.channel = c1
case_replicate_s2.properties
a3.sources = s1
a3.sinks = k1
a3.channels = c1
a3.sources.s1.type = avro
a3.sources.s1.channels = c1
a3.sources.s1.host = 192.168.123.102
a3.sources.s1.port = 7777
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
a3.sinks.k1.type = logger
a3.sinks.k1.channel = c1
#Start Avro 's Source first and listen to the port
flume-ng agent --conf conf --conf-file ~/apps/flume/examples/case_replicate_s1.properties --name a2 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true
flume-ng agent --conf conf --conf-file ~/apps/flume/examples/case_replicate_s2.properties --name a3 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true
#Restart Avro 's Sink
flume-ng agent --conf conf --conf-file ~/apps/flume/examples/case_replicate_sink.properties --name a1 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true
#Generate test log
echo "hello via channel selector" | nc 192.168.123.102 6666
4.3 Test Case (2) Reuse
case_multi_sink.properties
#Configuration files for 2 channels and 2 sinks
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# Describe/configure the source
a1.sources.r1.type = org.apache.flume.source.http.HTTPSource
a1.sources.r1.port = 5140
a1.sources.r1.host = 0.0.0.0
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.channels = c1 c2
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2
a1.sources.r1.selector.default = c1
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 172.25.4.23
a1.sinks.k1.port = 4545
a1.sinks.k2.type = avro
a1.sinks.k2.channel = c2
a1.sinks.k2.hostname = 172.25.4.33
a1.sinks.k2.port = 4545
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
case_ multi _s1.properties
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.channels = c1
a2.sources.r1.bind = 172.25.4.23
a2.sources.r1.port = 4545
# Describe the sink
a2.sinks.k1.type = logger
a2.sinks.k1.channel = c1
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
case_ multi _s2.properties
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.channels = c1
a3.sources.r1.bind = 172.25.4.33
a3.sources.r1.port = 4545
# Describe the sink
a3.sinks.k1.type = logger
a3.sinks.k1.channel = c1
# Use a channel which buffers events in memory
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
#Start Avro 's Source first and listen to the port
flume-ng agent -c . -f case_ multi _s1.conf -n a2 -Dflume.root.logger=INFO,console
flume-ng agent -c . -f case_ multi _s2.conf -n a3 -Dflume.root.logger=INFO,console
#Restart Avro 's Sink
flume-ng agent -c . -f case_multi_sink.conf -n a1-Dflume.root.logger=INFO,console
#Generate a POST request with the test header as state according to the configuration file
curl -X POST -d '[{ "headers" :{"state" : "CZ"},"body" : "TEST1"}]' http://localhost:5140
curl -X POST -d '[{ "headers" :{"state" : "US"},"body" : "TEST2"}]' http://localhost:5140
curl -X POST -d '[{ "headers" :{"state" : "SH"},"body" : "TEST3"}]' http://localhost:5140