Flume is a distributed, secure, high-availability massive log collection, aggregation and transmission systems. Java implementation, the plug-rich, distinct modules.

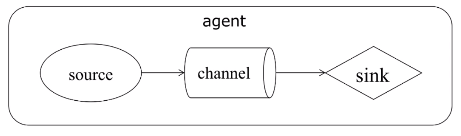
Data flow model: Source-Channel-Sink
Transaction mechanism to ensure the reliability of messaging
First, the basic components
Event: The basic unit of information, there are header and body composition. header is a key-value pairs, body is a byte array, the data stored in the specific
Agent: JVM process, responsible for the end of the message generated by external sources forwarded to another destination outside of the end
- Source: reading event from an external source, and write channel
- Channel: event staging assembly, the source writes, event will be saved until the sink successful consumer
- Sink: read event from the channel, and the write destination
Two, Flume common data stream
Simple data stream

Complex data stream 1
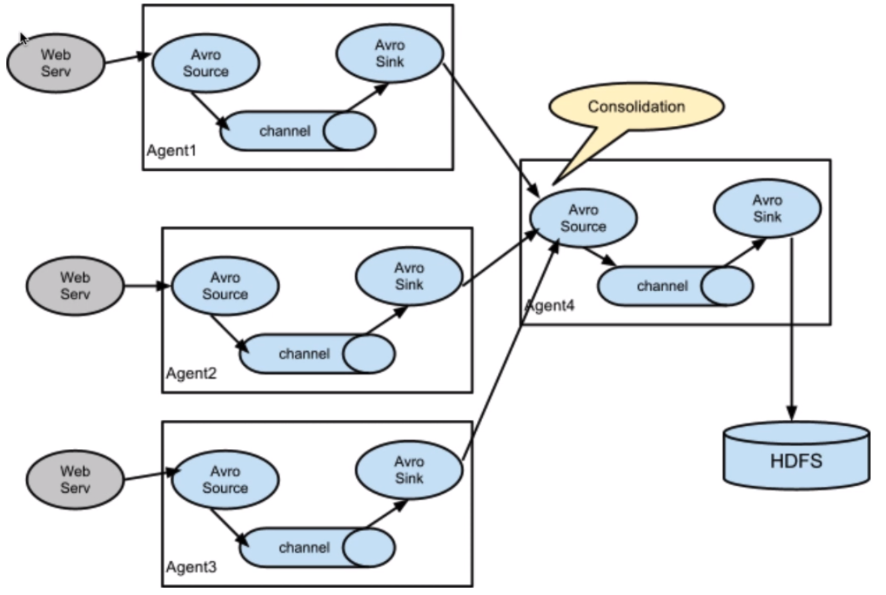
Complex data stream 2

Third, the complete transmission processing flow
In an event of a transfer agent in the process is as follows:
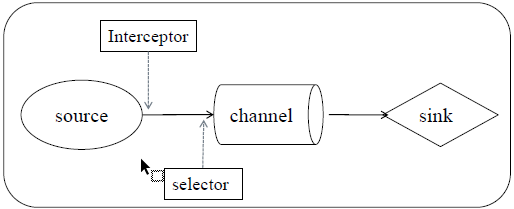
source - interceptor - selector -> channel -> sink processor - an agent> sink central storage / lower
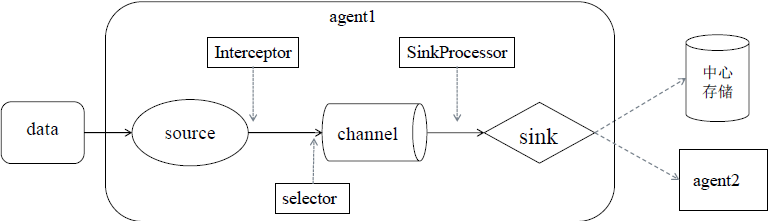
In addition to the source, channel and sink three basic components, as well as optional components Intercptor, Selector and SinkProcessor
source from the data source to obtain data package to the event, event header comprising header information and body
source collected event needs to be sent to the channel in temporary storage
Before being sent to Channel, if configured interceptors and a selector,
First through the interceptor, the interceptor can handle the event in the header information , you can add a time stamp in the header of the message processing, you can also add a host name, some static value, and so on. Can also filter the event based on regular expressions, you can continue to decide which event back for transmission, which terminate deleted. Interceptors can configure multiple, sequentially performs a plurality of interceptors .
And then passed selector can decide which way to write event to channel them
After the event is stored sink, can SinkProcessor, may be selected according to the configuration processor failover and load balancing processor, sink sends the event to the central storage or subsequent agent
Four, Source Components
Docking various external data sources, the collected event is sent to the Channel, one source may send event, The Flume built very rich plurality Source Channel, while the user can customize the Source
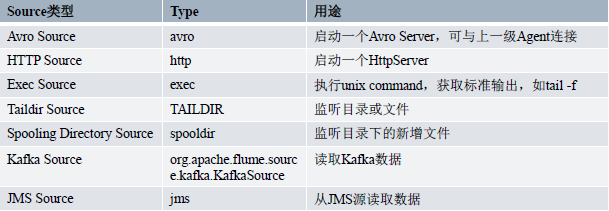
1.Avro Source
Avro protocol support, the event receives RPC request. Avro Avro the Source receives an external client stream event (event) by listening port Avro, often use the event received upstream Avro Sink transmitted in the multi-layer architecture Flume
Key Parameters:
- type: type name avro
- bind: Bound IP
- port: listening port
- threads: receiving a number of threads requested when clients need to receive multiple data streams avro to set the appropriate number of threads, which will cause avro client data streams backlog.
- compression-type: whether compression is used, if a compression is set to "deflate", avro source generally used for the data stream composed of a plurality Agent, avro sink from receiving the event, if avro source compression set, then the previous phase avro sink also set the compression, the default value none
- channels: Channel name Source docking
2.Exec Source
Linux command support, collect data or standard output monitor specified file tail -f file by the way
You can achieve real-time messaging, but it does not record the location of the file has been read, does not support the power failure resume, when Exec Source reboot or hang up will cause a subsequent increase of message loss, usually in a test environment using
key parameter:
- type: source type exec
- command: Linux command
- channels: Channel name Source docking
In the flume's conf directory, create a directory source
Creating avrosource.conf
avroagent.sources = r1
avroagent.channels = c1
avroagent.sinks = k1
avroagent.sources.r1.type = avro
avroagent.sources.r1.bind = 192.168.99.151
avroagent.sources.r1.port = 8888
avroagent.sources.r1.threads= 3
avroagent.sources.r1.channels = c1
avroagent.channels.c1.type = memory
avroagent.channels.c1.capacity = 10000
avroagent.channels.c1.transactionCapacity = 1000
avroagent.sinks.k1.type = logger
avroagent.sinks.k1.channel = c1
Creating execsource.conf
execagent.sources = r1
execagent.channels = c1
execagent.sinks = k1
execagent.sources.r1.type = exec
execagent.sources.r1.command = tail -F /bigdata/log/exec/exectest.log
execagent.sources.r1.channels = c1
execagent.channels.c1.type = memory
execagent.channels.c1.capacity = 10000
execagent.channels.c1.transactionCapacity = 1000
execagent.sinks.k1.type = avro
execagent.sinks.k1.channel = c1
execagent.sinks.k1.hostname = 192.168.99.151
execagent.sinks.k1.port = 8888
## 1.exec and avro source presentation
# agent consisting of two data collection process
execagent -> avroagent
start a avrosource agent of
bin / flume-ng agent --conf conf --conf-file conf / source / avrosource.conf - -name avroagent -Dflume.root.logger = INFO, console
to start a execsource agent transmits the data collected in a manner to rpc avroagent
bin / Flume ng agent --conf the conf-File---conf the conf / Source / execsource. conf --name execagent
listening /bigdata/log/exec/exectest.log file
3.Spooling Directory Source
Monitor a folder, file, folder, data collection, data collection finished with a file extension of the file name will be changed to .COMPLETED
The disadvantage is not supported collect new data file that already exists
key parameter:
- spoolDtype: source type spooldir
- spooDir: source listen folder
- fileHeader: whether to add the absolute path to the file header event, the default value is false
- fileHeaderKey: added to the event header file absolute path of the key, the default value is false
- fileSuffix: End of data collection in conjunction with the new file name suffix added to the file, the default value: .COMPLETED
- channels: Channel name Source docking
4.Taildir Source
Monitor a folder or a file by the regular expression matching data source file needs to be listened, Taildir Source file location by writing the file to listen to implement HTTP, and to ensure that no duplicate data read
key parameter:
type: source type TAILDIR
positionFile: Save the file to read monitor the location of a file path
idleTimeout: Close file idle time delay, if a new record is added to the closed free files taildir source, will continue to open the file is idle, the default value 120000 milliseconds (2 minutes)
writePosInterval: time to read the file location where the file data is written to the save interval, the default value 3000 milliseconds
batchSize: Batch write channel maximum number of event, the default value of 100
maxBackoffSleep: Every last attempt did not get to listen to the latest data file of the maximum delay time, the default value of 5000 milliseconds
cachePatternMatching: under the corresponding monitor folder, file by the regular expression matching the number may be much that will match the success of a list of files to listen, read the documents in the order have already mentioned it into the cache can improve performance, the default value true
fileHeader: whether to add the absolute path to the file header event, the default value is false
flleHeaderKey: Add to vent header in the key file absolute path, the default value is false
filegroups: a list of files group listening, taildirsource monitor multiple directories or files by file group
filegroups <filegroupName>:. listen using regular expressions to identify a file path
channels: Channel name Source docking
Creating taildirsource.conf
taildiragent.sources = r1
taildiragent.channels = c1
taildiragent.sinks = k1
taildiragent.sources.r1.type = TAILDIR
taildiragent.sources.r1.positionFile = /bigdata/flume/taildir/position/taildir_position.json
taildiragent.sources.r1.filegroups = f1 f2
taildiragent.sources.r1.filegroups.f1 = /bigdata/taildir_log/test1/test.log
taildiragent.sources.r1.filegroups.f2 = /bigdata/taildir_log/test2/.*\\.log
taildiragent.sources.r1.channels = c1
taildiragent.channels.c1.type = memory
taildiragent.channels.c1.capacity = 10000
taildiragent.channels.c1.transactionCapacity = 1000
taildiragent.sinks.k1.type = logger
taildiragent.sinks.k1.channel = c1
run
## 2.taildir source演示
bin/flume-ng agent --conf conf --conf-file conf/source/taildirsource.conf --name taildiragent -Dflume.root.logger=INFO,console
5.Kafka Source
Docking distributed message queue Kafka, Kafka as consumers continued to take data from Kafka and Latin America, if multiple simultaneous consumption Kafka Kafka source in the same topic (topic), then Kafka.consumer.group.id source of Kafka should be set to the same group id, duplicate data will not be spending the plurality Kafka source, each data source will pull in different topic
key parameter:
type: Type of setting the class path kafkasource, org.apache.flume.source.kafka.KafkaSource
channels: Channel name Source docking
kafka.bootstrap.servers: Kafka broker list, the format is ip1: port1, ip2: port2 ..., we recommended to configure multiple values increase fault tolerance, multiple values separated by commas
kafka.topics: topic name consumer
kafka.consumer.group.id:Kafka source owning group id, the default value flume
batchSize: maximum number of messages written to channel the bulk of the default value 1000
batchDurationMillis: the longest wait bulk of the write channel, this parameter and batchSize only two parameters to meet a write channel will trigger batch operations, the default value of 1000 milliseconds
Creating kafkasource.conf
kafkasourceagent.sources = r1
kafkasourceagent.channels = c1
kafkasourceagent.sinks = k1
kafkasourceagent.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
kafkasourceagent.sources.r1.channels = c1
kafkasourceagent.sources.r1.kafka.bootstrap.servers = 192.168.99.151:9092,192.168.99.152:9092,192.168.99.153:9092
kafkasourceagent.sources.r1.kafka.topics = flumetopictest1
kafkasourceagent.sources.r1.kafka.consumer.group.id = flumecg
kafkasourceagent.channels.c1.type = memory
kafkasourceagent.sinks.k1.type = logger
kafkasourceagent.sinks.k1.channel = c1
run
## 3.kafka source presentation
to create a theme kafka in
bin / kafka-topics.sh --create --zookeeper 192.168.99.151:2181 --replication- factor 1 --partitions 3 --topic flumetopictest
View topic
bin / kafka- topics.sh --list --zookeeper 192.168.99.151:2181
sends a message to flumetopictest1
bin / kafka-console-producer.sh --broker-List 192.168.99.151:9092,192.168.99.152:9092,192.168.99.153:9092 - flumetopictest -topic
# start Agent Flume
bin / Flume-ng Agent --conf conf --conf-File conf / Source / kafkasource.conf --name kafkasourceagent -Dflume.root.logger = INFO, Console
Five, Channel components
channel is designed to transfer event temporary storage area, is not stored Source and Sink collected event consumption, in order to balance the speed of reading data source and sink collection, it can be regarded as an internal message queue Flume
channel is thread-safe and has transactional, support source and sink write failure repeated write operations such as reading failure Repeatable read
Common Channel type:
Memory Channel
File Channel
Kafka Channel等
1.Memory Channel
Using memory as a Channel, Memory Channel read and write speed, but a small amount of data stored, Flume process hang, or reboot the server downtime will result in lost data. Adequate subordinates Flume Agent online server memory resources, without concern of data loss scenarios can be used
Parameter Description:

2.File Channel
The event is written to the disk file, compared with Memory Channel storage capacity, without risk of data loss
The Flume Event File Channel sequentially written to the end of the file, the configuration file by setting the parameter setting data maxFileSize maximum file size
When a closed file in read-only data is completely read complete Event, Sink has been submitted and read the completed transaction, the Flume store the data file will be deleted
Parameter Description:


Create a channel directory, create filechannel.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.channels = c1
a1.channels.c1.type = file
a1.channels.c1.dataDirs = /bigdata/flume/filechannel/data
a1.channels.c1.checkpointDir = /bigdata/flume/filechannel/checkpoint
a1.channels.c1.useDualCheckpoints = true
a1.channels.c1.backupCheckpointDir = /bigdata/flume/filechannel/backup
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
运行
## 1.file channel演示
在/bigdata/flume/filechannel目录手动创建backup、checkpoint、data文件夹
bin/flume-ng agent --conf conf --conf-file conf/channel/filechannle.conf --name a1 -Dflume.root.logger=INFO,console
使用telnet发送数据
telnet localhost 44444
3.Kafka Channel
将分布式消息队列Kafka作为channel
相比于Memory Channel和File Channel存储容量更大、容错能力更强,弥补了其他两种Channel的短板,如果合理利用Kafka的性能,能够达到事半功倍的效果
参数说明:

创建kafkachannel.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.channels = c1
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = 192.168.99.151:9092,192.168.99.152:9092,192.168.99.153:9092
a1.channels.c1.kafka.topic = flumechannel1
a1.channels.c1.kafka.consumer.group.id = flumecg1
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
运行
## 2.kafka channel演示
bin/kafka-topics.sh --create --zookeeper 192.168.99.151:2181 --replication-factor 1 --partitions 3 --topic kafkachannel
查看主题
bin/kafka-topics.sh --list --zookeeper 192.168.99.151:2181
bin/flume-ng agent --conf conf --conf-file conf/channel/kafkachannel.conf --name a1 -Dflume.root.logger=INFO,console
使用telnet发送数据
telnet localhost 44444
六、Interceptor拦截器
Source经event写入到Channel之前调用拦截器
Source和Channel之间可以有多个拦截器,不同的拦截器使用不同的规则处理Event
可选、轻量级、可插拔的插件
通过实现Interceptor接口实现自定义的拦截器
内置拦截器:Timestamp Interceptor、Host Interceptor、UUID Interceptor、Static Interceptor、Regex Filtering Interceptor等

1.Timestmap Interceptor
Flume使用时间戳拦截器在event头信息中添加时间戳信息,Key为timestamp,Value为拦截器拦截Event时的时间戳
头信息时间戳的作用,比如HDFS存储的数据采用时间分区存储,Sink可以根据Event头信息中的时间戳将Event按照时间分区写入到HDFS
参数说明:

2.Host Intercepor
Flume使用主机拦截器在Event头信息中添加主机名称或者IP
主机拦截器的作用:比如Source将Event按照主机名称写入到不同的Channel中便于后续的Sink对不同Channel中的数据分开处理
参数说明:

3.Static Intercepor
Flume使用static interceptor静态拦截器在event头信息添加静态信息
参数说明:

七、Sink组件
从Channel消费event,输出到外部存储,或者输出到下一个阶段的agent
一个Sink只能从一个Channel中消费event
当Sink写出event成功后,会向Channel提交事务。Sink事务提交成功,处理完成的event将会被Channel删除。否则Channel会等待Sink重新消费处理失败的event
Flume提供了丰富的Sink组件,如Avro Sink、HDFS Sink、Kafka Sink、File Roll Sink、HTTP Sink等
1.Avro Sink
常用于对接下一层的Avro Source,通过发送RPC请求将Event发送到下一层的Avro Source
为了减少Event传输占用大量的网络资源,Avro Sink提供了端到端的批量压缩数据传输
参数说明:

2.HDFS Sink
将Event写入到HDFS中持久化存储
提供了强大的时间戳转义功能,根据Event头信息中的timestamp时间戳信息转义成日期格式,在HDFS中以日期目录分层存储
参数说明:



创建HDFS目录,创建hdfssink.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /data/flume/%Y%m%d/%H%M
a1.sinks.k1.hdfs.filePrefix = hdfssink-
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 2
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 30
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
运行
## 1.hdfs sink演示
bin/flume-ng agent --conf conf --conf-file conf/sink/hdfssink.conf --name a1 -Dflume.root.logger=INFO,console
使用telnet发送数据
telnet localhost 44444
3.Kafka Sink
Flume通过KafkaSink将Event写入到Kafka指定的主题中
参数说明


创建kafkasink.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.channels = c1
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.channel = c1
a1.sinks.k1.kafka.topic = kafkasink
a1.sinks.k1.kafka.bootstrap.servers = 192.168.99.151:9092,192.168.99.152:9092,192.168.99.153:9092
a1.sinks.k1.kafka.flumeBatchSize = 100
a1.sinks.k1.kafka.producer.acks = 1
运行
## 2.kafka sink演示 创建主题FlumeKafkaSinkTopic1 bin/kafka-topics.sh --create --zookeeper 192.168.99.151:2181 --replication-factor 1 --partitions 3 --topic kafkasink 查看主题 bin/kafka-topics.sh --list --zookeeper 192.168.99.151:2181 bin/flume-ng agent --conf conf --conf-file conf/sink/kafkasink.conf --name a1 >/dev/null 2>&1 & bin/kafka-console-consumer.sh --zookeeper 192.168.99.151:2181 --from-beginning --topic kafkasink 使用telnet发送数据 telnet localhost 44444
八、Selector选择器
Source将event写入到Channel之前调用拦截器,如果配置了Interceptor拦截器,则Selector在拦截器全部处理完之后调用。通过selector决定event写入Channel的方式
内置Replicating Channel Selector复制Channel选择器、Multiplexing Channel Selector复用Channel选择器
1.Replicating Channel Selector
如果Channel选择器没有指定,默认值。即一个Source以复制的方式将一个event同时写入到多个Channel中,不同的Sink可以从不同的Channel中获取相同的event
参数说明:

创建replicating_selector目录,创建replicating_selector.conf
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
#定义source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#设置复制选择器
a1.sources.r1.selector.type = replicating
#设置required channel
a1.sources.r1.channels = c1 c2
#设置channel c1
a1.channels.c1.type = memory
#设置channel c2
a1.channels.c2.type = memory
#设置kafka sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = flumeselector
a1.sinks.k1.kafka.bootstrap.servers = 192.168.99.151:9092,192.168.99.152:9092
a1.sinks.k1.kafka.flumeBatchSize = 10
a1.sinks.k1.kafka.producer.acks = 1
#设置file sink
a1.sinks.k2.channel = c2
a1.sinks.k2.type = file_roll
a1.sinks.k2.sink.directory = /bigdata/flume/selector
a1.sinks.k2.sink.rollInterval = 60
运行
## 1.replicating selector演示
一个source将一个event拷贝到多个channel,通过不同的sink消费不同的channel,将相同的event输出到不同的地方
配置文件:replicating_selector.conf
分别写入到kafka和文件中
创建主题flumeselector
bin/kafka-topics.sh --create --zookeeper 192.168.99.151:2181 --replication-factor 1 --partitions 3 --topic flumeselector
启动flume agent
bin/flume-ng agent --conf conf --conf-file conf/replicating_selector/replicating_selector.conf --name a1
查看kafka FlumeSelectorTopic1主题数据
bin/kafka-console-consumer.sh --zookeeper 192.168.99.151:2181 --from-beginning --topic flumeselector
使用telnet发送数据
telnet localhost 44444
查看/bigdata/flume/selector路径下的数据
2.Multiplexing Channle Selector
多路复用选择器根据evetn的头信息中不同键值数据来判断Event应该被写入到哪个Channel中。
参数说明:

创建multiplexing_selector目录
创建avro_sink1.conf
agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1
agent1.sources.r1.type = netcat
agent1.sources.r1.bind = localhost
agent1.sources.r1.port = 44444
agent1.sources.r1.interceptors = i1
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = logtype
agent1.sources.r1.interceptors.i1.value = ad
agent1.sources.r1.channels = c1
agent1.channels.c1.type = memory
agent1.sinks.k1.type = avro
agent1.sinks.k1.channel = c1
agent1.sinks.k1.hostname = 192.168.99.151
agent1.sinks.k1.port = 8888
创建avro_sink2.conf
agent2.sources = r1
agent2.channels = c1
agent2.sinks = k1
agent2.sources.r1.type = netcat
agent2.sources.r1.bind = localhost
agent2.sources.r1.port = 44445
agent2.sources.r1.interceptors = i1
agent2.sources.r1.interceptors.i1.type = static
agent2.sources.r1.interceptors.i1.key = logtype
agent2.sources.r1.interceptors.i1.value = search
agent2.sources.r1.channels = c1
agent2.channels.c1.type = memory
agent2.sinks.k1.type = avro
agent2.sinks.k1.channel = c1
agent2.sinks.k1.hostname = 192.168.99.151
agent2.sinks.k1.port = 8888
创建avro_sink3.conf
agent3.sources = r1
agent3.channels = c1
agent3.sinks = k1
agent3.sources.r1.type = netcat
agent3.sources.r1.bind = localhost
agent3.sources.r1.port = 44446
agent3.sources.r1.interceptors = i1
agent3.sources.r1.interceptors.i1.type = static
agent3.sources.r1.interceptors.i1.key = logtype
agent3.sources.r1.interceptors.i1.value = other
agent3.sources.r1.channels = c1
agent3.channels.c1.type = memory
agent3.sinks.k1.type = avro
agent3.sinks.k1.channel = c1
agent3.sinks.k1.hostname = 192.168.99.151
agent3.sinks.k1.port = 8888
创建multiplexing_selector.conf
a3.sources = r1
a3.channels = c1 c2 c3
a3.sinks = k1 k2 k3
a3.sources.r1.type = avro
a3.sources.r1.bind = 192.168.99.151
a3.sources.r1.port = 8888
a3.sources.r1.threads= 3
#设置multiplexing selector
a3.sources.r1.selector.type = multiplexing
a3.sources.r1.selector.header = logtype
#通过header中logtype键对应的值来选择不同的sink
a3.sources.r1.selector.mapping.ad = c1
a3.sources.r1.selector.mapping.search = c2
a3.sources.r1.selector.default = c3
a3.sources.r1.channels = c1 c2 c3
a3.channels.c1.type = memory
a3.channels.c2.type = memory
a3.channels.c3.type = memory
#分别设置三个sink的不同输出
a3.sinks.k1.type = file_roll
a3.sinks.k1.channel = c1
a3.sinks.k1.sink.directory = /bigdata/flume/multiplexing/k1
a3.sinks.k1.sink.rollInterval = 60
a3.sinks.k2.channel = c2
a3.sinks.k2.type = file_roll
a3.sinks.k2.sink.directory = /bigdata/flume/multiplexing/k2
a3.sinks.k2.sink.rollInterval = 60
a3.sinks.k3.channel = c3
a3.sinks.k3.type = file_roll
a3.sinks.k3.sink.directory = /bigdata/flume/multiplexing/k3
a3.sinks.k3.sink.rollInterval = 60
运行
## 2.multiplexing selector演示 配置文件multiplexing_selector.conf、avro_sink1.conf、avro_sink2.conf、avro_sink3.conf 向不同的avro_sink对应的配置文件的agent发送数据,不同的avro_sink配置文件通过static interceptor在event头信息中写入不同的静态数据 multiplexing_selector根据event头信息中不同的静态数据类型分别发送到不同的目的地 在/bigdata/flume/multiplexing目录下分别创建看k1 k2 k3目录 bin/flume-ng agent --conf conf --conf-file conf/multiplexing_selector/multiplexing_selector.conf --name a3 -Dflume.root.logger=INFO,console bin/flume-ng agent --conf conf --conf-file conf/multiplexing_selector/avro_sink1.conf --name agent1 >/dev/null 2>&1 & bin/flume-ng agent --conf conf --conf-file conf/multiplexing_selector/avro_sink2.conf --name agent2 >/dev/null 2>&1 & bin/flume-ng agent --conf conf --conf-file conf/multiplexing_selector/avro_sink3.conf --name agent3 >/dev/null 2>&1 & 使用telnet发送数据 telnet localhost 44444
九、Sink Processor
协调多个sink间进行load balance和failover

1.Load-Balance Sink Processor
负载均衡处理器
参数说明:

2.Failover Sink Processor
容错处理器,可定义一个sink优先级列表,根据优先级选择使用的sink
参数说明:

创建failover目录
创建collector1.conf
collector1.sources = r1
collector1.channels = c1
collector1.sinks = k1
collector1.sources.r1.type = avro
collector1.sources.r1.bind = 192.168.99.151
collector1.sources.r1.port = 8888
collector1.sources.r1.threads= 3
collector1.sources.r1.channels = c1
collector1.channels.c1.type = memory
collector1.sinks.k1.type = logger
collector1.sinks.k1.channel = c1
创建collector2.conf
collector2.sources = r1
collector2.channels = c1
collector2.sinks = k1
collector2.sources.r1.type = avro
collector2.sources.r1.bind = 192.168.99.151
collector2.sources.r1.port = 8889
collector2.sources.r1.threads= 3
collector2.sources.r1.channels = c1
collector2.channels.c1.type = memory
collector2.sinks.k1.type = logger
collector2.sinks.k1.channel = c1
创建failover.conf
agent1.sources = r1
agent1.channels = c1
agent1.sinks = k1 k2
agent1.sources.r1.type = netcat
agent1.sources.r1.bind = localhost
agent1.sources.r1.port = 44444
agent1.sources.r1.channels = c1
agent1.channels.c1.type = memory
agent1.sinkgroups = g1
agent1.sinkgroups.g1.sinks = k1 k2
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 5
agent1.sinks.k1.type = avro
agent1.sinks.k1.channel = c1
agent1.sinks.k1.hostname = 192.168.99.151
agent1.sinks.k1.port = 8888
agent1.sinks.k2.type = avro
agent1.sinks.k2.channel = c1
agent1.sinks.k2.hostname = 192.168.99.151
agent1.sinks.k2.port = 8889
运行
## 1.failover processor演示
分别启动两个collector agent
bin/flume-ng agent --conf conf --conf-file conf/failover/collector1.conf --name collector1 -Dflume.root.logger=INFO,console
bin/flume-ng agent --conf conf --conf-file conf/failover/collector2.conf --name collector2 -Dflume.root.logger=INFO,console
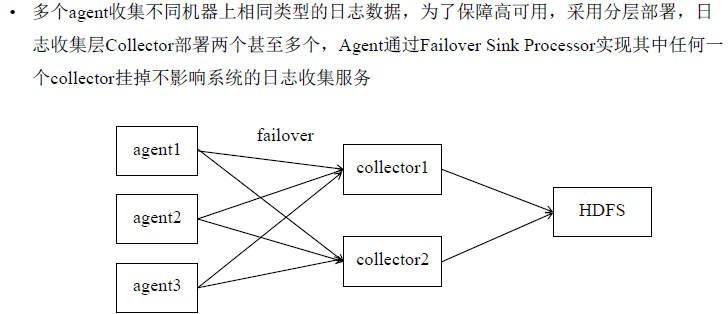
agent1通过failover方式,配置sink优先级列表,k1发送到collector1,k2发送到collector2。k1的优先级高于k2,所以在启动的时候
source将event发送到collector1,杀掉collector1,agent1会切换发送到collector2,实现高可用
bin/flume-ng agent --conf conf --conf-file conf/failover/failover.conf --name agent1 -Dflume.root.logger=INFO,console
bin/flume-ng agent --conf conf --conf-file conf/failover/coll1.conf --name collector1 -Dflume.root.logger=INFO,console
bin/flume-ng agent --conf conf --conf-file conf/failover/coll2.conf --name collector2 -Dflume.root.logger=INFO,console
3.Failover应用场景
分布式日志收集场景
十、数据收集系统实现
单层日志收集架构

分层日志收集架构

案例flume+kafka
Producer
kafka0.10.2版本官方文档地址:http://kafka.apache.org/0102/documentation.html
1.在Maven项目的pom.xml文件中添加kafka客户端相关依赖,本项目使用的是kafka0.10版本的API
<properties> <kafka-version>0.10.2.0</kafka-version> </properties> <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>${kafka-version}</version> </dependency> </dependencies>
2.Producer生产逻辑
1)配置Producer相关参数
2)创建Producer实例
3)构建待发送的消息
4)发送消息
5)关闭Producer实例
3.Producer相关参数说明
Producer相关配置文档:http://kafka.apache.org/0102/documentation.html#producerconfigs
bootstrap.servers(必选项):通过该参数设置producer连接kafka集群所需的broker地址列表。
格式:host1:port1,host2:post2,...可以设置一个或者多个地址,中间用逗号隔开,该参数默认值是""。
注意:该参数值建议设置两个及以上broker地址,这样可以保障任意一个broker宕机不可用,producer还可以连接到kafka。可以不设置全部的broker地址,因为producer可以从给定的broker里查找其它broker信息。
key.serializer和value.serializer(必选项):这两个参数用于设置key和value的序列化器,producer需要通过序列化器将key和value序列化成字节数组通过网络发送到kafka。
kafka客户端内置的序列化器:String / Double / Long / Integer / ByteArray / ByteBuffer / Bytes
注意:在配置序列化器的时候,要写序列化器的全路径,如:org.apache.kafka.common.serialization.StringSerializer
client.id(可选项):用户设置客户端id,如果不设置,kafka客户端会自动生成一个非空字符串作为客户端id,自动生成的客户端id形式“producer-1”
acks(可选项):默认是值是1,可选值范围[all, -1, 0, 1]。用于设置Producer发送消息到Borker是否等待接收Broker返回成功送达信号。
0:表示Producer发送消息到Broker之后不需要等待Broker返回成功送达的信号,这种方式吞吐量高,但是存在数据丢失的风险,“retries”参数配置的发送消息失败重试次数将失效。
1:表示Broker接收到消息成功写入本地log文件后,向Producer返回成功接收的信号,不需要等待所有的Follower全部同步完消息后再做回应,这种方式在数据丢失风险和吞吐量之间做了平衡。
-1(或者all):表示Broker接收到Producer的消息成功写入本地log并且等待所有的Follower成功写入本地log后,向Producer返回成功接收的信号,这种方式能够保证消息不丢失,但是性能最差。
retries:Producer发送消息失败后的重试次数。默认值是0,即发送消息出现异常不做任何重试。
retry.backoff.ms:用来设置两次重试之间的时间间隔,默认值是100ms。
4.ProducerConfig工具类
注意:在平时的开发过程中,由于kafka的参数非常多,为了防止由于人为书写错误,导致参数名出错,kafka客户端提供了ProducerConfig工具类,在ProducerConfig工具类中定义个kafka相关的各种参数。
ProducerConfig的定义如下:

5.kafka客户端代码请参考本课时资料中的ProducerClient.java文件
在ProducerClient类中定义了4个客户端发送消息的方法,每个方法实现了一种发送消息的方法,可以参考ProducerClient类的具体实现,学习kafka Producer Java API的使用。
Consumer
Consumer客户端消费逻辑步骤
1)配置Consumer相关参数
2)创建Consumer实例
3)订阅主题
4)拉取消息并消费
5)提交已消费的消息的偏移量
6)关闭Consumer实例
Consumer相关参数说明
1)bootstrap.servers
(必选项)通过该参数设置producer连接kafka集群所需的broker地址列表。
格式:host1:port1,host2:post2,...可以设置一个或者多个地址,中间用逗号隔开,该参数默认值是""。
2)group.id
(必选项)消费者所属的消费者组id,默认值为“”。
3)key.deserializer和value.deserializer
(必选项)这两个参数用于设置key和value的反序列化器,consumer需要通过反序列化器将key和value反序列化成原对象格式。
注意在配置序列化器的时候,要写序列化器的全路径,如:org.apache.kafka.common.serialization.StringDeserializer
4)auto.offset.reset
当一个新的消费者组被建立,之前没有这个新的消费者组消费的offset记录。或者之前存储的某个Consumer已消费的offset被删除了,查询不到该Consumer已消费的offset。诸如上述的两种情况,消费者找不到已消费的offset记录时,就会根据客户端参数auto.offset.reset参数的配置来决定从哪里开始消费。
该参数默认值是“latest”,表示从分区的末尾开始消费消息。
如果设置值为“earliest”,表示从从分区的最早的一条消息开始消费。
如果设置值为“none”,表示从如果查询不到该消费者已消费的offset,就抛出异常。
Consumer客户端消费消息的方式
Kafka Consumer采用从指定topic拉取消息的方式消费数据,并不是kafka服务器主动将消息推送给Consumer。Consumer通过不断地轮询,反复调用poll方法从订阅的主题的分区中拉取消息。
poll方法定义:public ConsumerRecords<K, V> poll(long timeout)
调用poll方法时需要传入long类型的timeout超时时间,单位毫秒,返回值是拉取到的消息的集合ConsumerRecords。timeout超时时间用来控制poll方法的阻塞时间,当poll方法拉取到消息时,会直接将拉取到的数据集返回;当使用poll方法没有拉取到消息时,则poll方法阻塞等待订阅的主题中有新的消息可以消费,直到到达超时时间。
消息偏移量offset
在kafka的分区中,每条消息都有一个唯一的offset,用来表示消息在分区中的位置。消费者使用offset来表示消费到分区中的某个消息所在的位置,并且消费者要保存已消费消息的offset,消费者下次拉取新消息会从已消费的offset之后拉取。
Kafka Consumer默认是由客户端自动提交offset,在kafka老的版本中将Consumer已消费的offset保存在Zookeeper中,在Kafka0.10版本之后将已消费的消息的offset保存在kafka的__consumer_offsets中。Consumer客户端通过enable.auto.commit参数设置是否自动提交offset,默认值是true自动提交。自动提交的时间间隔由auto.commit.interval.ms参数控制,默认值是5秒。所以Consumer客户端默认情况下是每隔5秒钟提交一次已消费的消息的offset。