1. Index
1.1 indexing works
1. What is the index? -- table of Contents
Index is a storage structure built up a table in the storage stage there, and can accelerate the time of the query.
2. The index of importance:
Literacy ratio of 10: 1, all read (query) the speed is essential.
3. Index of principle:
block disk read-ahead principle
Equivalent to read file operations: for line in f

Each index block 4096 bytes can be stored
Hard disk io read the operation time is very long, much longer than the CPU to execute instructions, as much as possible to reduce the number of IO to read and write is the main problem to be solved data.
1.2 database storage
1. storage database:
1. The new data structure - Tree
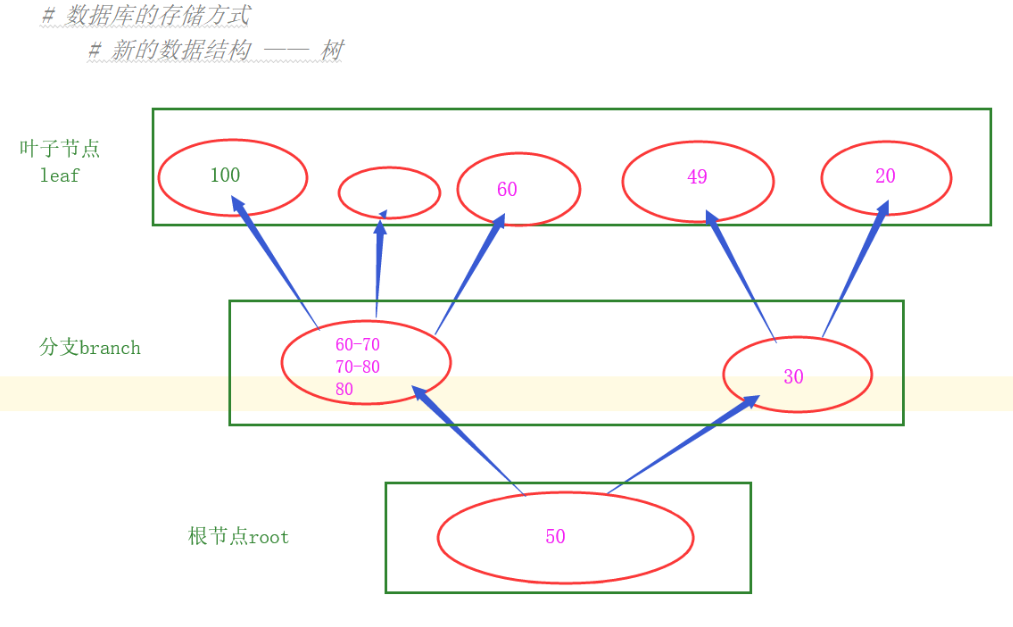
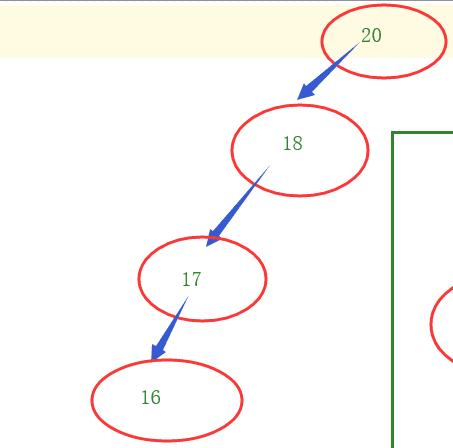
Disadvantages: prone data at only one end, resulting in slow read (IO operation multiple times).
2. balanced tree balance tree - b tree
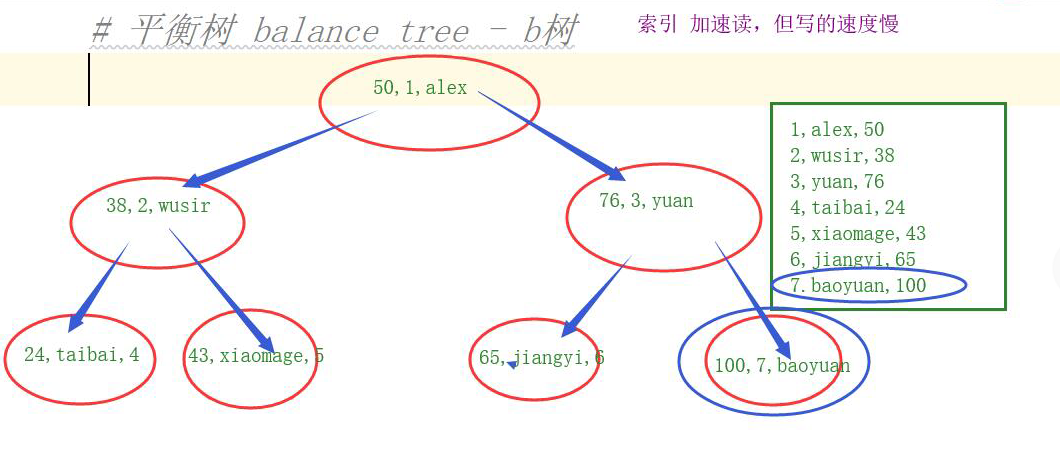
Disadvantages: storing large data length, the limited number of pieces of data can be stored, causing a relatively large height of the book, the reading efficiency is low.
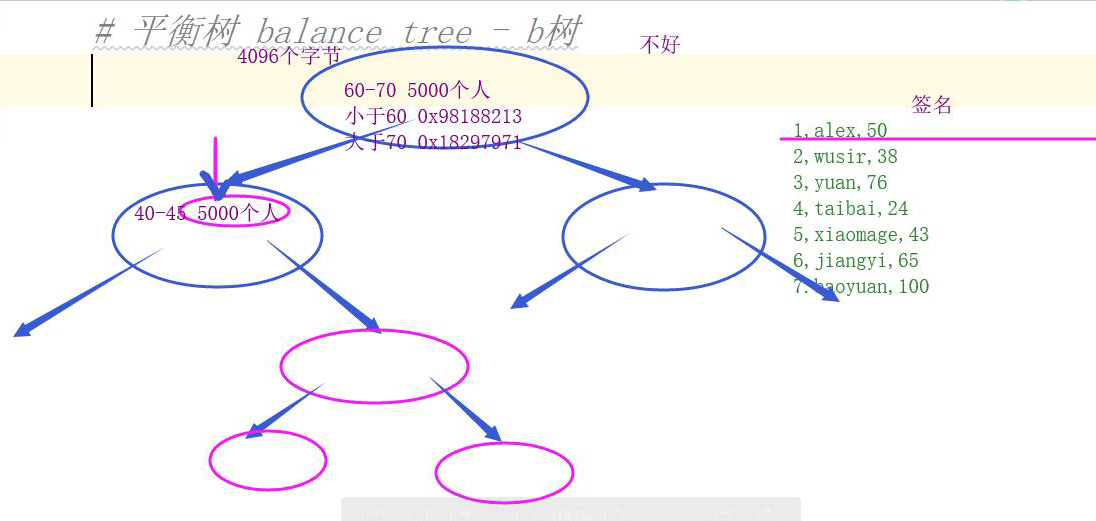
3. On the basis of the improvement of the b-tree - b + tree
- 1. branch root node and not the actual data in memory, so that the root and branch can store more information on the index, reduces the height of the tree, all the actual data is stored in the leaf nodes
- 2. In between leaf nodes to join the two-way chain structure, convenient range of conditions in the query.
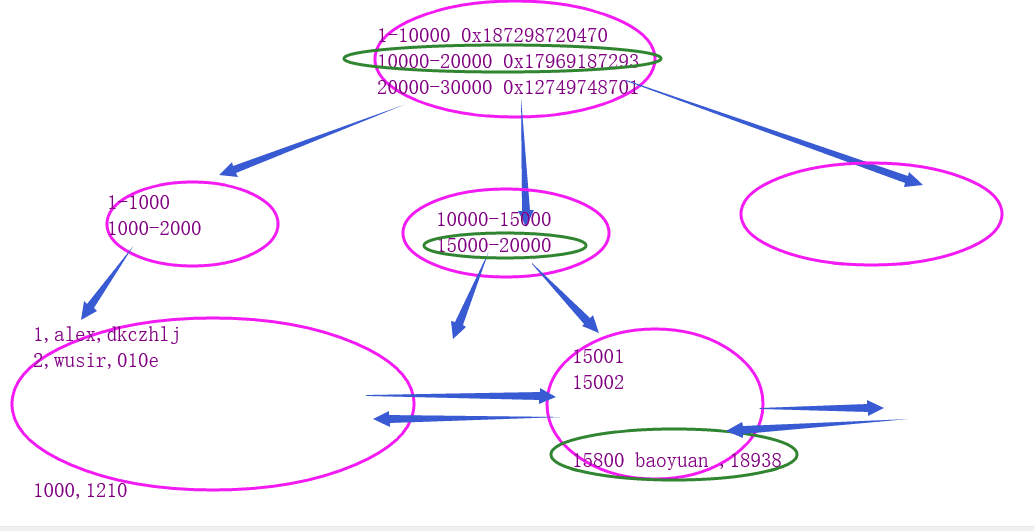
Among all 4.mysql height b + tree index layers are substantially at 3:
- The number of operations is very stable 1.io
- 2. favor by the scope of inquiry
5. What will affect the efficiency index -? Height of the tree
- 1. Create an index which column, select the column indexed as short as possible
- 2. distinguish high column built index, a repetition rate of more than 10%, not suitable for creating an index.
1.3 clustered index and secondary indexes
In the innodb: clustered index and secondary indexes coexistence
Clustered index - the primary key, faster
Only the primary key is the clustered index
Data is stored directly in the leaf nodes of the tree structure
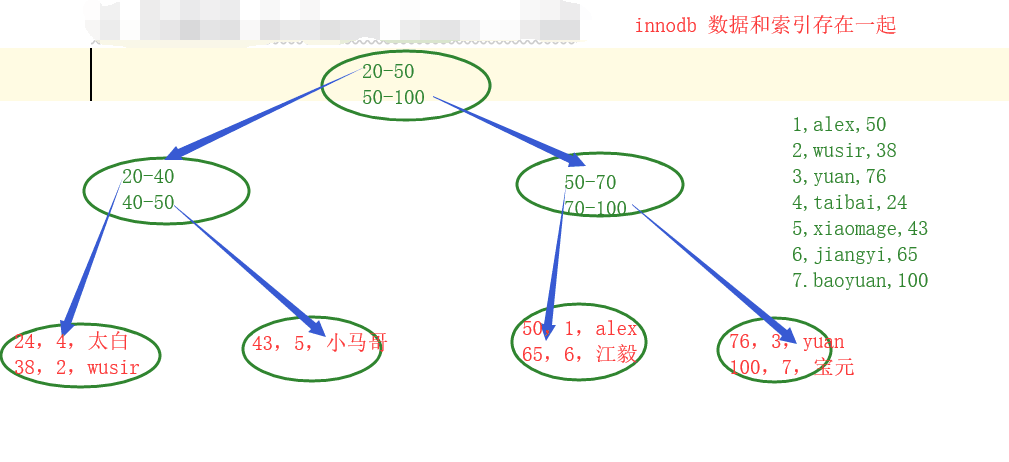
Secondary indexes - all in addition to the primary key indexes are secondary indexes, slower
Data is not directly stored in the tree

In myisam in: Only secondary indexes, there is no clustered index
1.4 Index of species
1. index categories:
primary key primary key, a clustered index, the effect of the constraint: The only non-null +
Primary key
comes with unique index is a secondary index, constraint effects: the only
The only union
index is a secondary index, no binding effect
Joint index
Note: According to major items divided in three categories: primary key, unique, index
There are six types of segments: primary key, primary key, unique, unique joint, index, joint index
2. look at how to create an index after the change, to create an index
create index index name on table (field)
Delete Index: drop index index name on table name;
3. The index is how to play a role?
select * from 表 where id = xxxxx;
- As a condition to email inquiries:
- Do not add an index when, certainly slow
- Query field is not indexed field, but also slow
- id as a condition when:
- When id field without an index, low efficiency
- After the id field has an index, high efficiency
The reason is not effective index of 1.5
1. The index of the reasons not to take effect:
<1> a large range of the data to be queried
With a range of related:
1. <> = <=! = (! = Not hit almost Index)
2.between and
select * from 表 order by age limit 0,5;
select * from 表 where id between 1000000 and 1000005;
3.like
- The results of a large range of index does not take effect
- If the index take effect abc%,% abc index does not take effect
<2> If the discrimination of a content is not high, the index does not take effect
- Such as: name row
<3> index column conditions can not participate in the calculation
- select * from s1 where id * 10 = 1000000; index does not take effect
<4> The contents of two query conditions
and: the content and condition ends, a preference index, and a better tree structure, to query (efficiency will be higher). Both conditions are fulfilled to complete the conditions where the first complete range of small, narrow back pressure conditions.
- select * from s1 where id =1000000 and email = 'eva1000000@oldboy';
or: or with the conditions, it will not be optimized, but in turn filtered according to conditions from left to right.
To hit with a condition or an index of these conditions in all of the columns are indexed columns.
- select * from s1 where id =1000000 or email = 'eva1000000@oldboy';
<5> joint index
Create a joint index: create index ind_mix on s1 (id, name, email);
select * from s1 where id =1000000 and email = 'eva1000000@oldboy'; 能命中索引1. If the index will not take effect or condition in a joint index:
select * from s1 where id = 1000000 or email = 'eva1000000 @ oldboy'; not hit index
2. The most left-prefix principles: the joint index, the conditions must contain the first index column when creating the index.
select * from s1 where id =1000000; 能命中索引 select * from s1 where email = 'eva1000000@oldboy'; 不能命中索引 # 联合索引 (a,b,c,d) a,b 、 a,c 、 a 、 a,d 、 a,b,d 、 a,c,d 、 a,b,c,d # 等含有a索引的都能命中索引 # 不含a索引的其他索引都不能命中。3. Throughout the conditions, from the moment began to appear fuzzy matching, the index becomes ineffective
select * from s1 where id >1000000 and email = 'eva1000001@oldboy'; 不能命中索引 select * from s1 where id =1000000 and email like 'eva%'; 能命中引
2. When a joint index?
- Only a, abc conditions of index B would not, when the index for a single column of c.
3. For single-column index:
- Selecting a high distinction column is indexed, the conditions do not participate in the calculation of the column, the range of conditions as possible, and to use as a condition of connector
4. Use or to connect a plurality of conditions:
- On the basis of satisfying the above conditions (single-column index) on all columns of or related to each create an index.
Some 1.6 index terms
1. coverage index
If we use the index as a condition for a query, after the query is completed, do not need to check back to the table, it is covered by the index.

explain select id from s1 where id = 1000000;
explain select count(id) from s1 where id > 1000000;
2. The combined index
Create an index on two fields respectively, due to the condition of sql make two indexes into force at the same time, then this time both indexes has become a consolidated index
3. Plan of Implementation explain
If you want to know before executing the sql statement on the implementation of sql statement, you can use the execution plan.
# 情况1:
如果有30000000条数据,使用sql语句查询需要20s,
explain sql语句 --> 并不会真正的执行sql,而是会给你列出一个执行计划
# 情况2:
20条数据 --> 30000000
explain sql4. Recommendations
<1> to build the table, use sql statement when the attention of:
- char instead of varchar
- Even the table instead of a subquery
- When creating the table: fixed-length fields on the front
<2> utf8 与 utf8mb4 :
- utf8 not able to display Chinese full amount of coding, as many unusual and rare words Emoji expression (Emoji is a special Unicode encoding, common in the ios and android mobile phones), as well as any new Unicode characters and so on
- utf8mb4 full amount can display Chinese encoding
If you encounter later use utf8 garbled, you can be encoded to change utf8mb4.
1.7 The basic steps slow query optimization
- First run to see if really slow, pay attention to set SQL_NO_CACHE
1.where single table search condition, the locking minimum return record table. This means that where the query are applied to the number of records in the table to return the smallest table search from the start, single-table queries each field separately, the highest distinction see which fields
2.explain view the execution plan, whether step 1 is consistent with the expected (from the beginning of the lock fewer records table query)
3.order limit by the form of the sql statement to sort of let the investigation take precedence table
4. understand the business side usage scenarios
indexed reference 5. indexed several principles
6. observe the results do not meet expectations continue from 0 analysis
Slow Log Management 1.8
1. Slow Log
- The execution time> 10
- Misses Index
- Log File Path
2. Configuration:
RAM
show variables like '%query%';
show variables like '%queries%';
set global variable name = value
Profiles
mysqld --defaults-file='E:\wupeiqi\mysql-5.7.16-winx64\mysql-5.7.16-winx64\my-default.ini'
my.conf content:
- slow_query_log = ON
- slow_query_log_file = D:/....
Note: After modifying the configuration file, need to restart the service
3. Log Management
See URL: https: //www.cnblogs.com/Eva-J/articles/10126413.html#_label8
2. pymysql module
2.1 pymysql module
python equivalent client
import pymysql
conn = pymysql.connect(host='127.0.0.1', user='root', password="123",database='day40') # python与mysql连接
cur = conn.cursor() # 创建 数据库操作符:游标
# 增加数据
cur.execute('insert into employee(emp_name,sex,age,hire_date) '
'values ("郭凯丰","male",40,20190808)')
# 删除数据
cur.execute('delete from employee where id = 18')
conn.commit() # 提交
conn.close()
# 查询数据
import pymysql
conn = pymysql.connect(host='127.0.0.1', user='root', password="123",database='day40')
cur = conn.cursor(pymysql.cursors.DictCursor) # 想要输出为字典格式时加上pymysql.cursors.DictCursor
cur.execute('select * from employee where id > 10')
ret = cur.fetchone() # 查询第一条数据
print(ret['emp_name'])
ret = cur.fetchmany(5) # 查询5条数据
ret = cur.fetchall() # 查询所有的数据
print(ret)
conn.close()2.2 Data backup and transaction
1. The logical backup database
Syntax: mysqldump -h -u user name -p password server database name> .sql backup file
#示例:
#单库备份
mysqldump -uroot -p123 db1 > db1.sql
mysqldump -uroot -p123 db1 table1 table2 > db1-table1-table2.sql
#多库备份
mysqldump -uroot -p123 --databases db1 db2 mysql db3 > db1_db2_mysql_db3.sql
#备份所有库
mysqldump -uroot -p123 --all-databases > all.sql2. Data Recovery
#方法一:
[root@egon backup]# mysql -uroot -p123 < /backup/all.sql
#方法二:
mysql> use db1;
mysql> SET SQL_LOG_BIN=0; #关闭二进制日志,只对当前session生效
mysql> source /root/db1.sql3. Transaction
begin; # 开启事务
select * from emp where id = 1 for update; # 查询id值,for update添加行锁;
update emp set salary=10000 where id = 1; # 完成更新
commit; # 提交事务(解锁)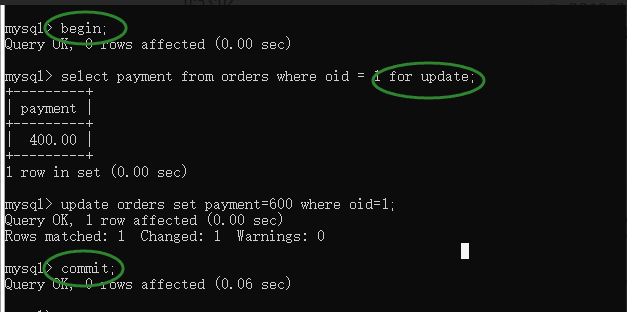
Pay attention to three key points:
- begin
- commit
- for update
2.3 sql injection
create table userinfo(
id int primary key auto_increment,
name char(12) unique not null,
password char(18) not null
)
insert into userinfo(name,password) values('alex','alex3714')
# 用户名和密码到数据库里查询数据
# 如果能查到数据 说明用户名和密码正确
# 如果查不到,说明用户名和密码不对
username = input('user >>>')
password = input('passwd >>>')
sql = "select * from userinfo where name = '%s' and password = '%s'"%(username,password)
print(sql)
-- :表示注释掉--之后的sql语句
select * from userinfo where name = 'alex' ;-- and password = '792164987034';
select * from userinfo where name = 219879 or 1=1 ;-- and password = 792164987034;
select * from userinfo where name = '219879' or 1=1 ;-- and password = '792164987034';The above situation can be input to a query result, so there are security risks, there are security risks of such a situation is called sql injection.
In order to avoid sql injection, when used pymysql, not to themselves splicing sql statement, and let yourself go mysql module splicing.
import pymysql
conn = pymysql.connect(host = '127.0.0.1',user = 'root',
password = '123',database='day41')
cur = conn.cursor()
username = input('user >>>')
password = input('passwd >>>')
sql = "select * from userinfo where name = %s and password = %s"
cur.execute(sql,(username,password)) # 让mysql模块去拼接
print(cur.fetchone())
cur.close()
conn.close()