-
-
Local simple dynamic strings
-
redis not directly use conventional string C language representation (null-terminated character array), but had built a simple dynamic string abstract type (simple dynamic string sds) is named, and as the redis sds The default string representation.
In redis, c is only as a string literal strings used in some places without having to modify the string value . For example, the print log:
redisLog(REDIS_WRNING,"redis is now ready to exit,bye bye");
If redis need is a string that can be modified, it will use sds to represent the values of the string , for example, if the command is executed on the client, msg hello word, and all will be represented by sds.
redis> set msg "hello word"
OK
In addition to the database used to store string values outside, sds also serve as a buffer: AOF AOF buffer module.
1.sds defined
Each sds.h / sdshdr structure represents a value sds:
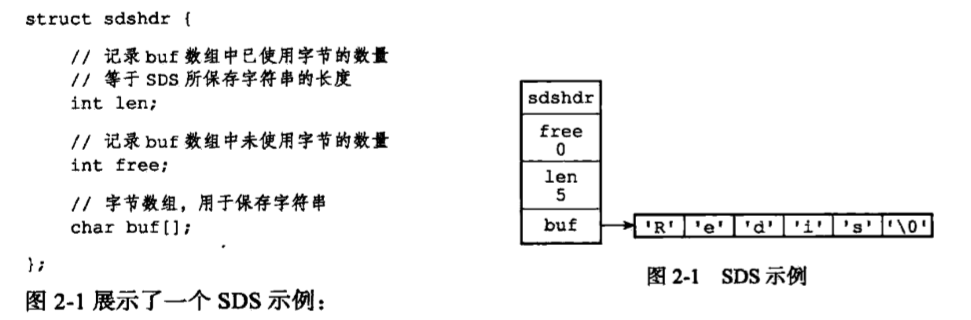
sds practice followed c string null character, null character stored byte 1 does not calculate the spatial properties len. Allocating additional byte space is a null string, and add an empty character string to the end of the array is done automatically by the sds function, so an empty string is completely transparent for the user is the sds. C follows the string null character of the benefits of the practice is that you can reuse the function part of the C library string functions .
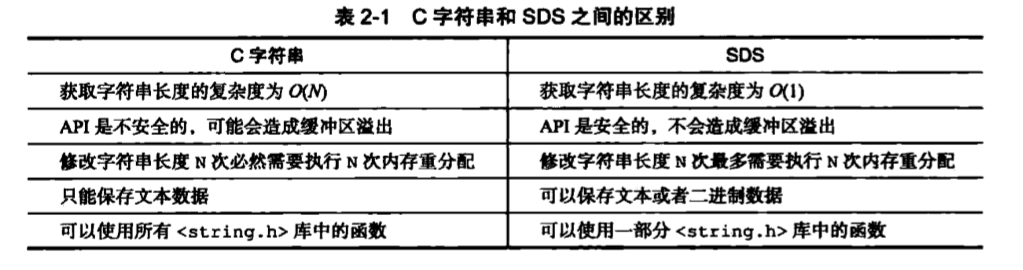
And c string difference 2.sds
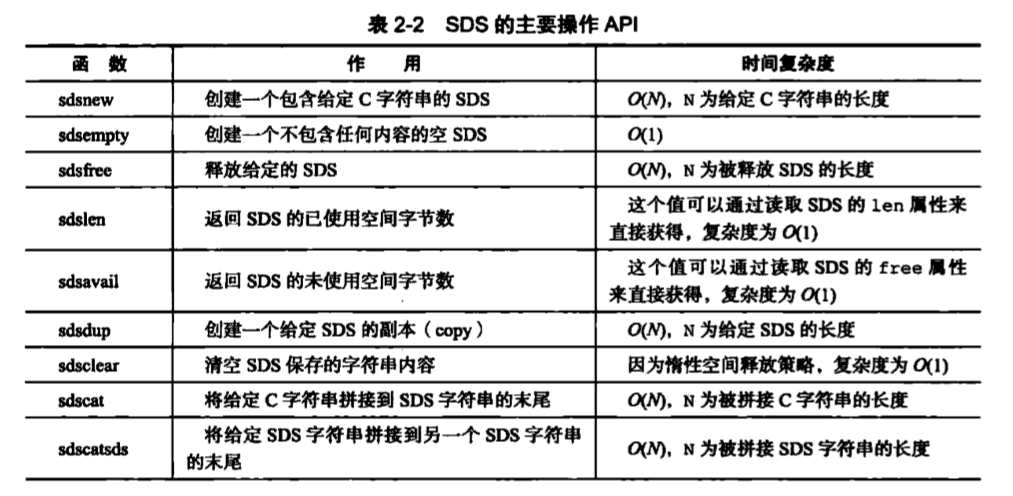
API 3.sds major operation
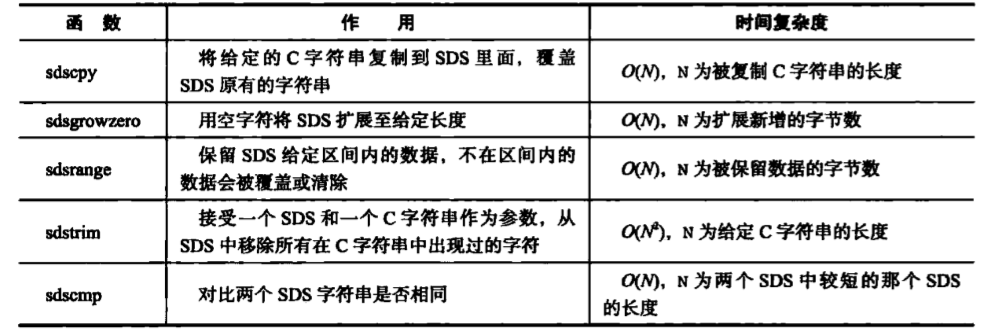
-
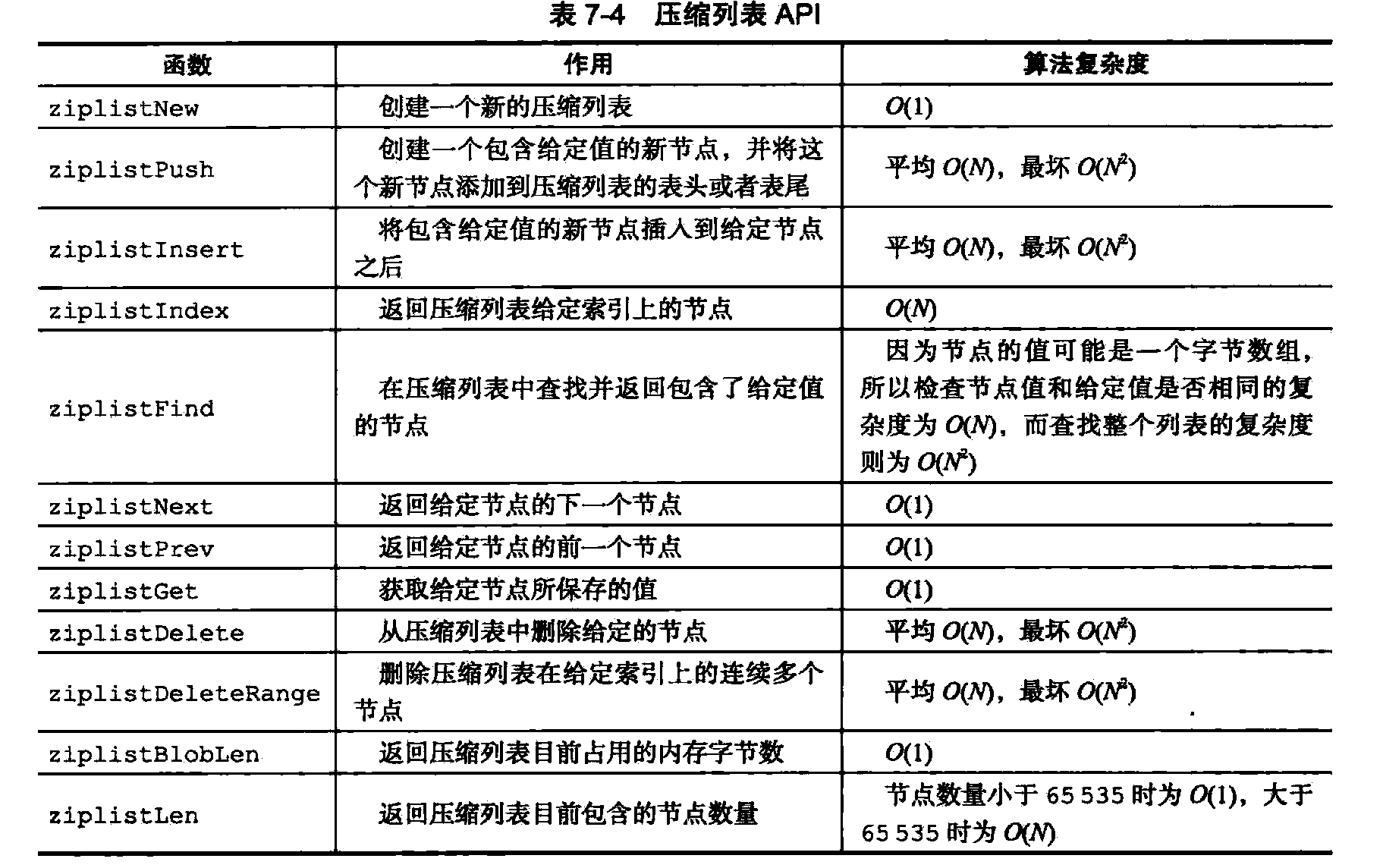
List
List of nodes provides efficient rearrangement capability, and sequential access mode node, and can add or delete nodes flexibly adjust the length of the list.
Built-in high-level language list many years, but the C language is not built such a structure, so redis build their list.
1. The realization of list node and list
Each list node uses adlist.h / listNode structure represented by:

Although only the use of multiple listNode structures can form a linked list, but using adlist / list to hold the list, then it will be very easy to operate:

Providing structure list table pointer list head, tail tail pointer table, and a list length counter, and to dup, free, and match the type of the members are used to implement the particular function desired polymorphic list:
dup function is used to copy the value stored in the node list;
free function list node for releasing the stored value;
match function value for comparison stored in this list node and a further input values are equal.
Redis list of characteristics to achieve summarized as follows:
1 Complexity "prev and next list node having a pointer, acquires front and rear node of a node is node O (1)
2 "next and prev pointer table end node header node point null, access to the list as the end point to null.
3 "Get list header node and end node of the time complexity is O (1)
4 "Get the number of nodes of the time complexity is O (1)
5 "void * list node using a node pointer to store values, and can be dup, free, match node attribute value three type-specific function, the node can store different types of values.
2. list node and list of API


-
Dictionary (the equivalent of java in the map)
Dictionary, also known symbol table, associative arrays, maps. Is an abstract data structure stored key-value pairs.
Each dictionary key is unique, you can find and update the values according to the key. Or according to key to delete the entire key-value pairs.
Redis dictionary application is rather broad, such as is used redis database dictionary as the underlying implementation, additions and deletions to change search the database is built on the operation of the operation of the dictionary.
1. The realization dictionary
redis dictionary implemented as the underlying hash table, a hash table may be a hash table with a plurality of nodes. Each node on the hash table holds a dictionary of key-value pairs.
1.1 Hash Table
Redis hash table is defined by the dictionary used dict.h / dictht structure:

attribute table is an array, each element in the array is a pointer dict.h / dictEntry each dictEntry structure holds a key-value pair. size attribute records the size of hash table, and used property records the hash table there are nodes (key-value pairs) number. Sizemask attribute value is always equal size-1, and the property values determined with a hash key which should be placed on the index. The following figure shows a hash table does not contain any key-value pairs.
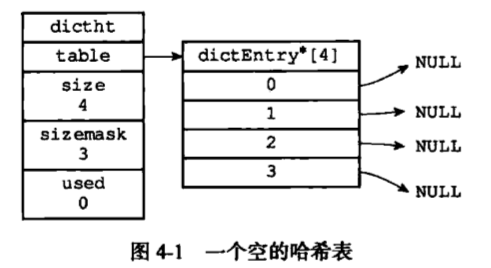
1.2 hash table node
Hash table node uses dictEntry structure, said structures each dictEntry holds a key pair.

holds the key in the key property of the key, val attribute holds the key-value pair, the type of the value may be a pointer, uint64, int64 three types.
next property is a pointer to the next node in the hash table, the pointer can connect multiple nodes together hash table, in order to solve the problem hash conflict.
Dictionary 1.3
The dictionary is represented by redis dict.h / dict structure:

type properties and privdata properties are for different types of key-value pairs, in order to create a multi-state set of dictionaries.
type attribute is a pointer dictType each dictType cluster structure functions for operating on the stored characteristics of the type of key-value pairs, Redis sets of different types for different uses particular function dictionary.
privdata property contains optional parameters to be passed to these specific functions.

ht attribute represents an array comprising two terms, each term represents a hash table, under normal circumstances, only the dictionary ht [0], [1] will be [0] resize when in use ht ht .rehashinx recorded a rehash of progress, if there's not rehash, rehashinx value of -1.

refresh: With the increase or decrease key-value pairs, too much can lead to poor performance on key lookup index, the key array much too little space is wasted memory. Therefore, in order to maintain the ratio of key-value pairs, and both the size of the array (indicated by load factor). We need to hash table corresponding expansion and contraction. Done by refresh.
Perform an extended operating conditions:
1 " server is not currently running or bgrewriteaof bgsave command, and the load factor is greater than or equal to 1.
2 " server is performing bgsave bgrwriteaof or command, and the load factor is greater than or equal to 5.
Then think about a problem: The ht [0] in the presence of key-value pairs to rehash ht [1] in a one-time to complete it. The answer is not enough, because if the number of key-value pairs very much, so a large amount of computation will make the server out of service for some time, so the dictionary refresh operation is gradual. Specific steps are as follows

Progressive benefit is that every time the dictionary of additions and deletions to change search operation when the specified index will refresh key pair. But not in time to achieve a one-time extension of the conditions of implementation of all the refresh operation. Like this refresh, the server can handle user requests.
In the process of progressive refresh, the dictionary will use ht [0] and ht [1] two hash table, so CRUD operations are performed on two tables. On a table can not find the specified key and went on to find another table, then perform the appropriate action.
Dictionary operations API:


-
Jump table
Jump table is an ordered data structure that is maintained by a plurality of links to other nodes in a node pointer, so as to achieve fast access
Jump table supports average O (logN), the worst node complexity O (N) lookup, batch processing nodes may also be the batch operation.
In most cases, jumping and balance sheet efficiency can be comparable to a tree, and because simple, so there are many programs in place to balance the tree with a jump table.
Redis skip table used as the underlying implementation of one of the ordered set of keys, if a more ordered set containing the number of elements, members or elements in a relatively long string of ordered set will be used when the jump table as ordered implementation of the underlying collection.
Positioning jump table header and the end of the time table complexity O (1), the length of the table lookup skip time complexity is O (1)
Not the header length (hop table length) and Level (maximum wall jump table) is calculated range.
1. jump table implementation
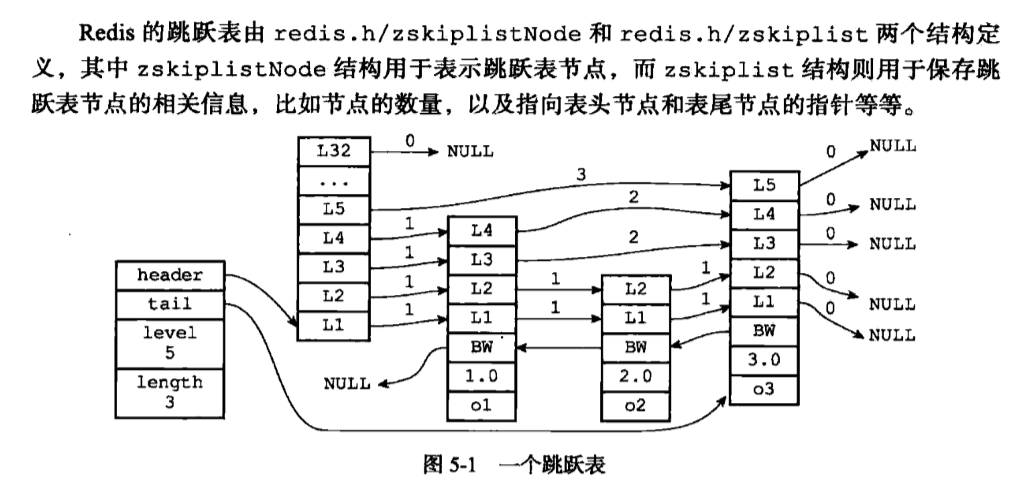



2 layer
Level jump table array may comprise a plurality of elements, each element containing a pointer to other nodes, a program can speed up access to other nodes through the layers, in general, the greater the number of layers, the other access the faster the speed of the node.
Each node to create a new hop table, the program should generate a random number between 1 and 32 interposed level as the size of the array according to a power law (the probability of occurrence of the greater number of smaller), this size is a high number.
3. Forward Pointer
Forward pointers used to access the header to the table from the direction of the end node, the figure shows the program jumps to the header traversal table footer by a dotted line paths for all nodes:

4. span
Recording span a distance between two nodes, points to the forward pointer null span are zero.
Find a node in the process, along the way visited span all layers add up to the span node lookup.
5. Back Pointer
Backward pointers used to access the node from the tail of the first direction to the table, with different advanced pointer can skip a plurality of nodes, each node backward pointer has only one, it can only back to the previous node.
6. scores and members
Node score is a floating point type double, all the hop count in the table are in ascending order according to the size score.
Members of the target node is a pointer to a string object.
In the same hop table stored in each node of the object must be different, and they may be the same value, the same value to the node in the dictionary according to the size of the object member in order to sort the smaller members of the object We will be standing in the front.
Jump table API:
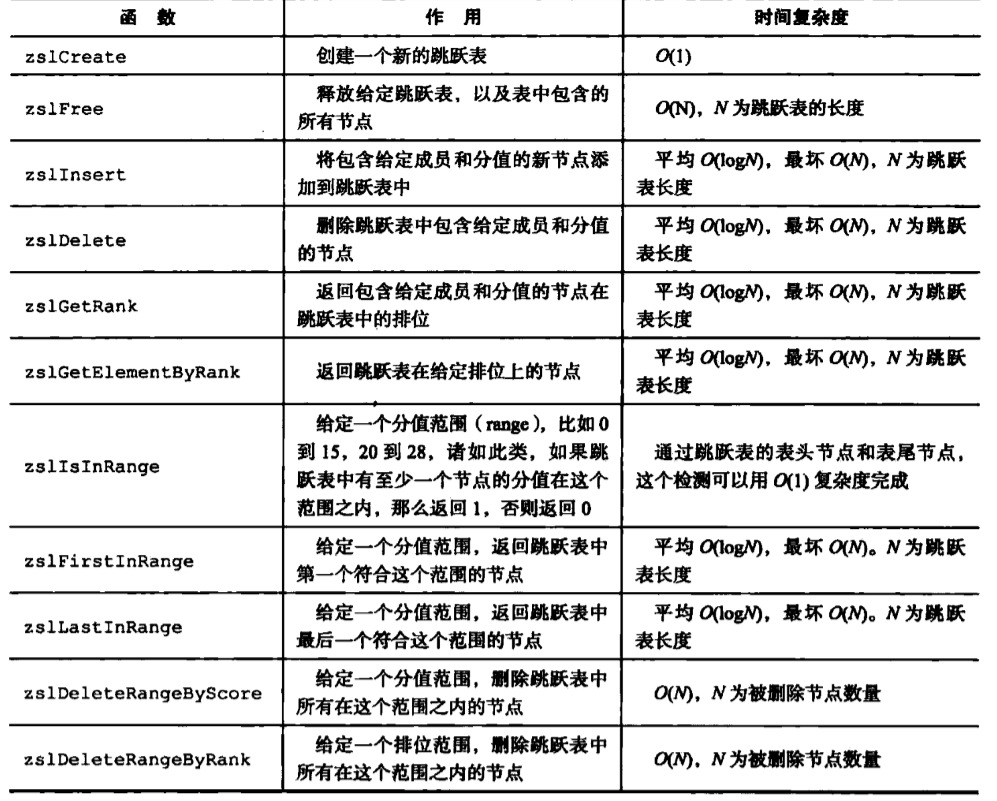
-
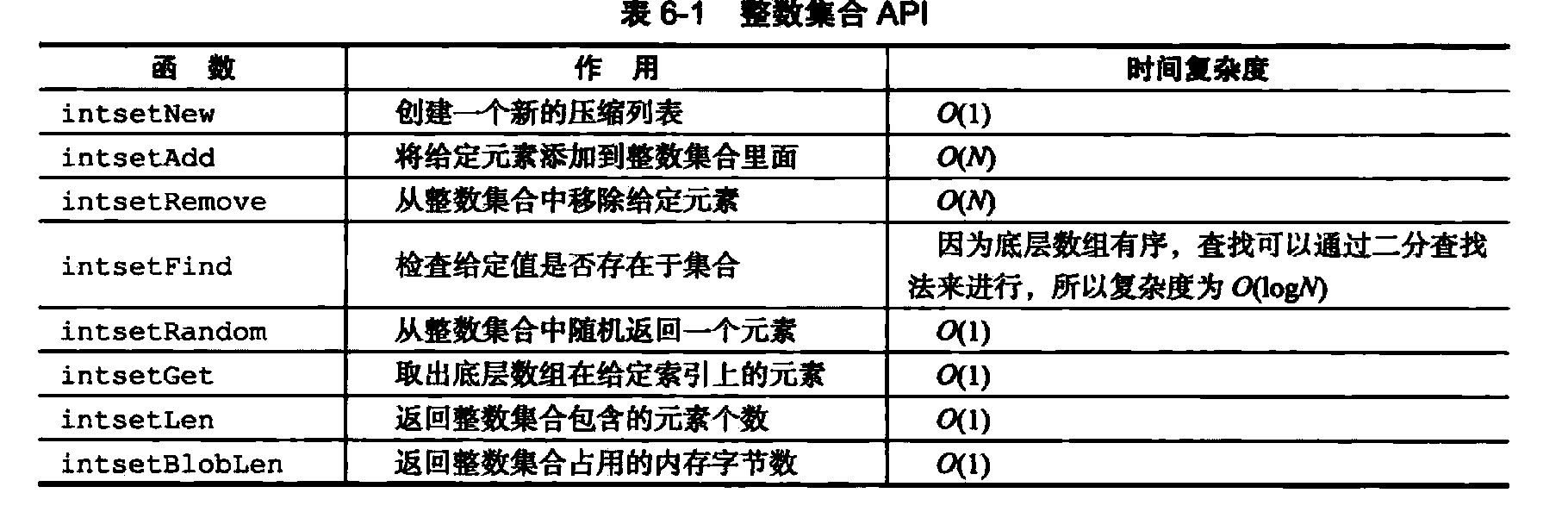
Integers
The underlying implementation is one of integers of the set of keys when a set contains only integer elements, and a small number of elements, integers Redis will be used as the underlying implementation of the key set.
1. The realization of the set of integers

contents is a numerical value, wherein each element in ascending order according to the size of the element, and does not allow duplicate elements.
Representative encodeing element type array contents
length represents the length of the contents of the array
2. Upgrade
When we add value to the set of integers, if the type of value added than the value of the integer type when the length is now longer sets. Integers need to be upgraded (the set of all elements of the type promoted to the newly inserted type and the same type), then insert new elements.
To add is divided into three steps
1 "Extended integers: a new element (the length of the original Type integers in the number of elements * + 1) is the sum of the length of the new type of array.
2 "original set of integers each element into a new suitable index array, first put the largest number of the original array, (type length as the number of newly inserted greater than the original length of the element type, the new insert number or greater than the number of all the original set (as when a positive number), or less than all numbers (as a negative element in the collection )), the newly inserted if the number is positive, then the original array largest number in the new index into the array for the penultimate. If the number of newly inserted is negative, then the index is the last position, then in descending order of the original array elements of the original elements in the array are sequentially moved into an appropriate position.
3 "Finally, a new element into the foremost or rearmost array (positive at the end).
Note: the set of integers does not support downgrading. When the length of the high data types present in the set of integers are deleted, the length of an integer type is not set and therefore reduced.
3. The benefits of upgrading
1 "Because we do not usually meet a number of different types of the same length into a data structure, in order to avoid converting data types of digital storage before, we can set easily use help us to automatically convert the integer type.
2 "set of integers can be carried out when necessary for data type conversion, rather than at the outset to open up large memory space to store low-length data types. Doing so saves memory.
API is a set of integers
-
Packing List
A list of compression is redis developed to save memory, the data structure is a sequential series of contiguous blocks of memory specially encoded thereof. A list of compression may comprise any number of nodes (entry), each node can store a byte array or an integer value.
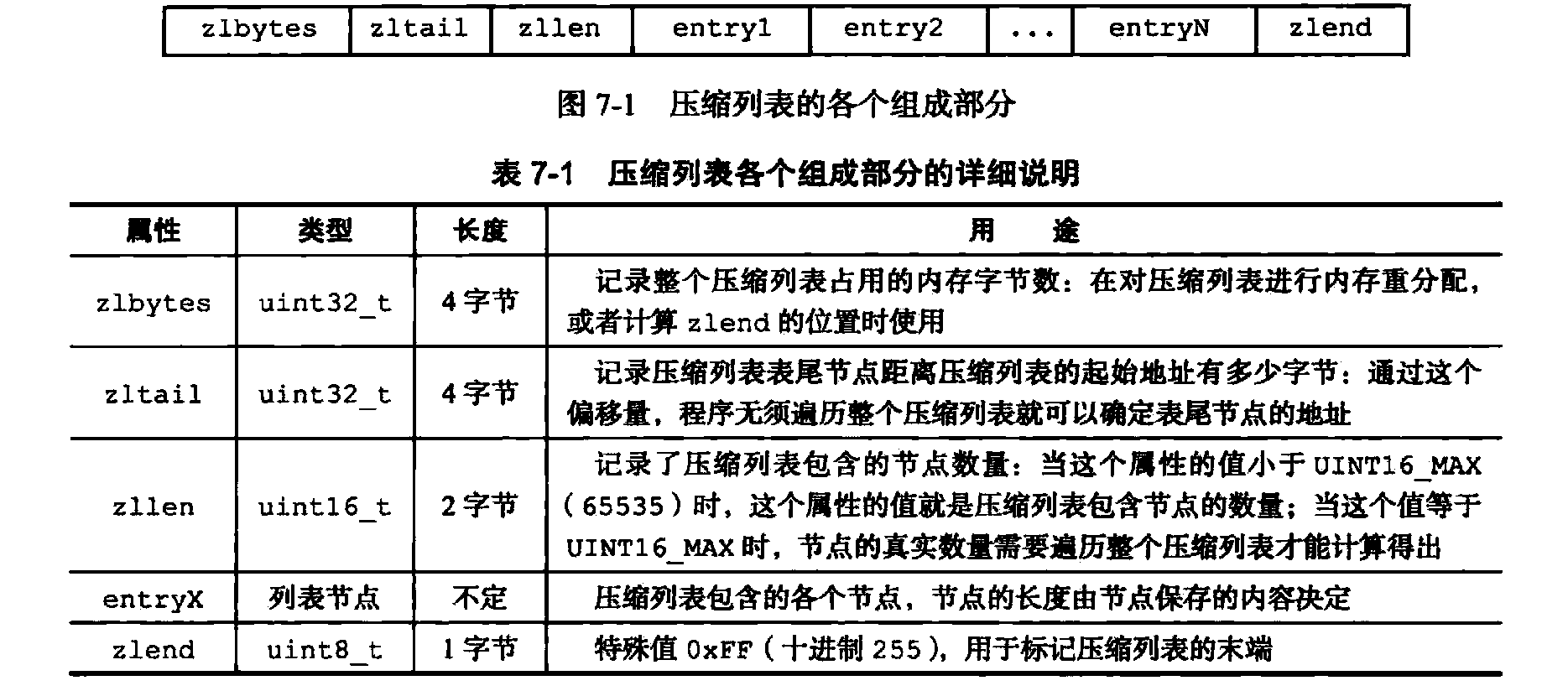

1. compressing a list of nodes constituting
Each compressed node list by previous_entry_length, enconding, content of three parts.
1》previous_entry_length
This property in bytes, the byte length of the record of the previous node. Or may be only 1 byte 5 bytes.
If the length is less than the previous node 254 bytes, then the length of the attribute is 1 byte. Before Ruoguo length before a node is greater than or equal to 254 bytes, then the value of this property is the length of 5 bytes, the first byte is set to 0XFE (254), after the four bytes used to store a the length of the node.
Because this property records the length of the previous node, so the program can calculate the starting address of the next node via the start address of the current node.
2》encoding
The value of this attribute is the type of content data is recorded and the length
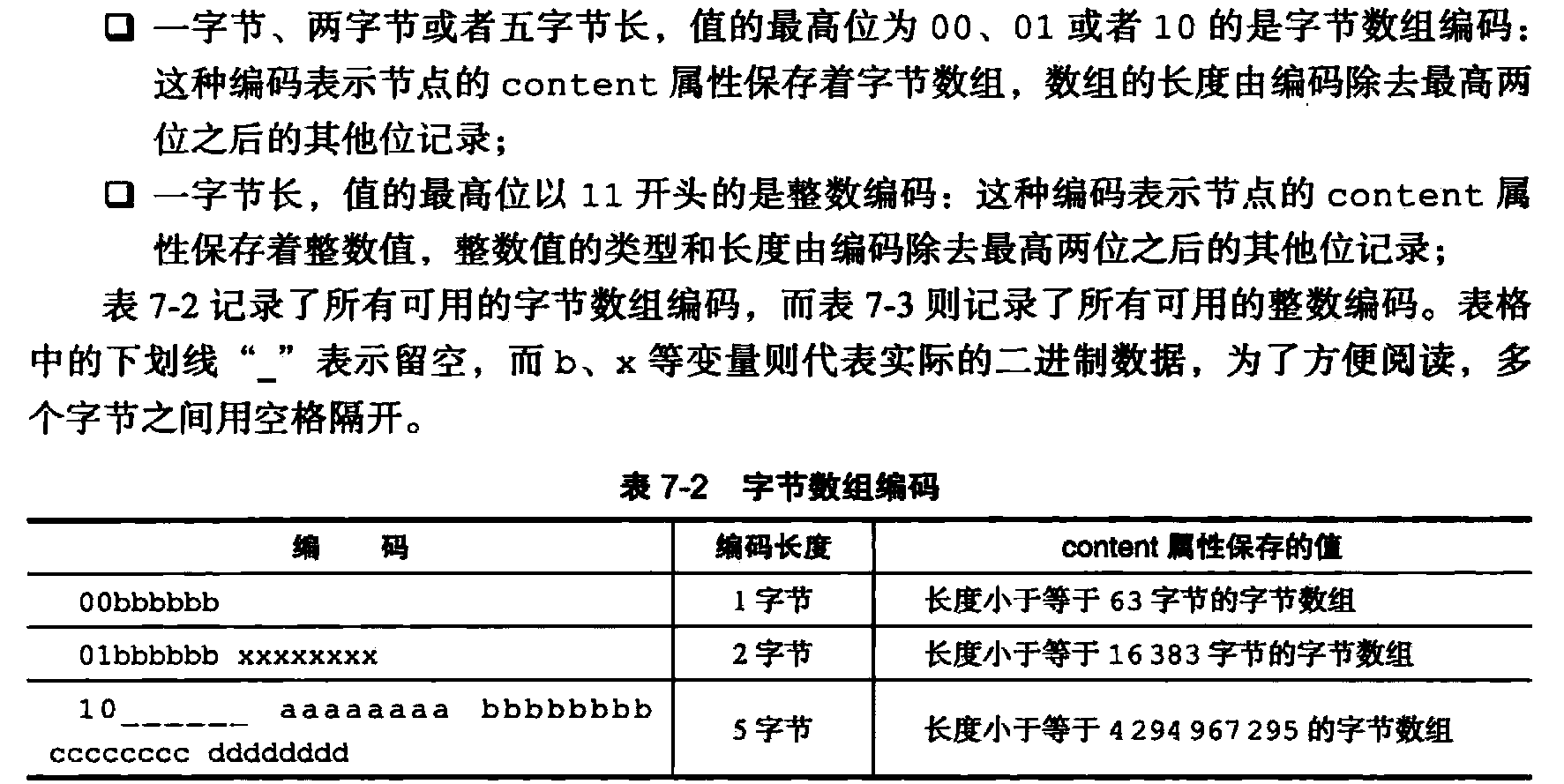

3》content
The value of this property is responsible for storing the value of the node, the node may be a byte array or an integer.

As shown above, encoding is represented by the length of the content is 00001011. 11, encoding content is expressed as an integer 11000000 16_int type.
2. Chain Update
Chain updated occurrence:

Previous_entry_length value of e1, before adding the node is 1 byte. After adding a node, however, since the length of the newly added node is greater than 254 bytes, the length previous_entry_length e1 extended attribute is 5 bytes. However, the total length of node e1 to more than 254 bytes, which leads to property values e2 previous_entry_length node also becomes 5 bytes, e3, e4, en empathy. It led to a chain of update.
Because the need to update the chain in the worst case of performing compression of the space N reallocation operation list, and each space reallocation worst time complexity is O (N), so that the chain update worst time complexity is O ( N)
While the chain update time complexity is high, but the probability is very low. To meet the compressed list exactly plurality of continuous length between 250 to 253 bytes of the condition of the nodes, the update chain can occur. Chain update small number of nodes nor will it affect performance.
Compression API list