Table of contents
Comparison of skiplist with balanced tree and hash table
Redis can store five data structures: String (string), List (list), Set (set), Hash (hash), Zset (ordered set). Commands such as del, type, and rename are common. In addition, note that these structures are stored in a key-data structure. That is as stated:

The Redis object is represented by the redisObject structure:
typedef struct redisObject { unsigned type:4; // The type of the object, including /* Object types */ unsigned encoding:4; // At the bottom, in order to save space, a type of data can be used Different storage methods unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; // reference count void *ptr; } robj;
Note that the above mainly refers to redis3.2, and the latest redis5 version is basically the same, but some files cannot be found, and there may be changes.
1, string type
The maximum size is 512M. The String type is stored as a structure through int and SDS (simple dynamic string). Int is used to store integer data, and sds is used to store byte/string and floating-point data.
In the source code of redis [sds.h], the structure of sds is as follows:
typedef char *sds;
The redis3.2 branch introduces five types of sdshdr. The purpose is to meet the requirements of using different sizes of headers for strings of different lengths, thereby saving memory. When creating an sds each time, judge which type of sdshdr should be selected according to the actual length of the sds. Different types of sdshdr occupy different memory spaces. Subdividing it in this way can save a lot of unnecessary memory overhead. The following is the sdshdr definition of 3.2, which is the same in version 5.0.7:
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr8 8 means the maximum length of the string is 2^8, and the length is 255 { uint8_t len; /* used */ means The length of the current sds (unit is byte) uint8_t alloc; /* excluding the header and null terminator */ Indicates the size of memory space allocated for sds (unit is byte) unsigned char flags; /* 3 lsb of type, 5 unused bits */ Use one byte to represent the current type of sdshdr, because there are five types of sdshdr, so at least 3 bits are required to represent char buf[]; the actual storage location of sds
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
sds icon:
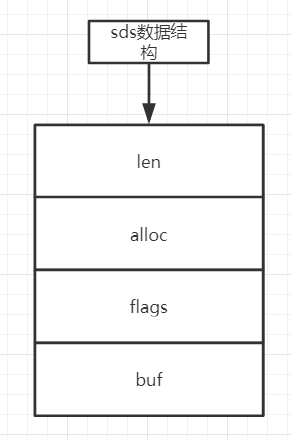
The string type data structure can be used for: user mailboxes, pictures, etc.
Operation summary:
127.0.0.1:6379> set a man
OK
127.0.0.1:6379> get a
"man"
127.0.0.1:6379> from to
(integer) 1
127.0.0.1:6379> get a
(nil)
2, list type
The list is implemented with a doubly linked list, so it is faster to add at both ends, and the time complexity is O(1).
Before redis3.2, the value object of List type was implemented internally by linkedlist or ziplist. When the number of elements in the list and the length of a single element were relatively small, Redis would use ziplist (compressed list) to implement it to reduce memory usage. Otherwise, a linkedlist (doubly linked list) structure will be used. After redis3.2, a data structure called quicklist is used to store the list, and the bottom layer of the list is implemented by quicklist.
These two storage methods have advantages and disadvantages. The two-way linked list performs push and pop operations at both ends of the linked list. The complexity of inserting nodes is relatively low, but the memory overhead is relatively large; ziplist is stored in a continuous memory, so the storage efficiency is very high. High, but both insertion and deletion require frequent application and release of memory ;
Quicklist is still a doubly linked list, but each node of the list is a ziplist , which is actually a combination of linkedlist and ziplist. Each node in quicklist ziplist can store multiple data elements. The file in the source code is [quicklist.c ], explained in the first line of the source code: Adoubly linked list of ziplists means a doubly linked list composed of ziplist;
Basic operations, lpush, rpush, lpop, rpop, lrange; lrange list-key 0 -1 means fetch all.
quicklist:
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
Node of quicklist:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
The overall layout of the ziplist is as follows:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
The storage of the list is shown in the figure below:

Use scene: slightly
Operation section:
127.0.0.1:6379> lpush a 2
(integer) 1
127.0.0.1:6379> lpush a 3
(integer) 2
127.0.0.1:6379> rpush a 1
(integer) 3
127.0.0.1:6379> lrange a 0 -1
1) "3"
2) "2"
3) "1"
127.0.0.1:6379> lindex is 1
"2"
127.0.0.1:6379> lpop a
"3"
127.0.0.1:6379> rpop a
"1"
127.0.0.1:6379> lrange a 0 -1
1) "2"
3. hash type
Conceptually, the hash type is a map. It is realized through hashtable or ziplist. When the amount of data is small, use ziplist, and when the amount of data is large, use hashtable. How small is it to use ziplist? Take a look at the source code:
/* Check the length of a number of objects to see if we need to convert a
* ziplist to a real hash. Note that we only check string encoded objects
* as their string length can be queried in constant time. */
This piece of code Used to judge whether to convert the ziplist into a real hash, pay attention to only check the character encoding object
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) { int i;
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
If the encoding of o is not OBJ_ENCODING_ZIPLIST, it will not be processed
for (i = start; i <= end; i++) {
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
hashTypeConvert(o, OBJ_ENCODING_HT);
break;
}
}
}
转换还有一段代码:
/* Add a new field, overwrite the old with the new value if it already exists.
* Return 0 on insert and 1 on update.
* 新增一个字段,如果存在就覆盖
* By default, the key and value SDS strings are copied if needed, so the
* caller retains ownership of the strings passed. However this behavior
* can be effected by passing appropriate flags (possibly bitwise OR-ed):
*
* HASH_SET_TAKE_FIELD -- The SDS field ownership passes to the function.
* HASH_SET_TAKE_VALUE -- The SDS value ownership passes to the function.
*
* When the flags are used the caller does not need to release the passed
* SDS string(s). It's up to the function to use the string to create a new
* entry or to free the SDS string before returning to the caller.
*
* HASH_SET_COPY corresponds to no flags passed, and means the default
* semantics of copying the values if needed.
*
*/
#define HASH_SET_TAKE_FIELD (1<<0)
#define HASH_SET_TAKE_VALUE (1<<1)
#define HASH_SET_COPY 0
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
/* Grab pointer to the value (fptr points to the field) */
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
update = 1;
/* Delete value */
zl = ziplistDelete(zl, &vptr);
/* Insert new value */
zl = ziplistInsert(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
if (!update) {
/* Push new field/value pair onto the tail of the ziplist */
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* Check if the ziplist needs to be converted to a hash table */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);
if (de) {
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
dictGetVal(de) = value;
value = NULL;
} else {
dictGetVal(de) = sdsdup(value);
}
update = 1;
} else {
sds f,v;
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
dictAdd(o->ptr,f,v);
}
} else {
serverPanic("Unknown hash encoding");
}
/* Free SDS strings we did not referenced elsewhere if the flags
* want this function to be responsible. */
if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);
if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);
return update;
}
Therefore, there are two situations that will be executed, one is to check whether the length of the value string is greater than 64, and the other is to check whether the size of the entries contained is more than 512, that is, compare with the two values of server.hash_max_ziplist_value and server.hash_max_ziplist_entries , these two values can be set in redis.conf:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
As shown above, ziplist has three structures for the implementation of hashTable, in dict.h:
dictEntry
typedef struct dictEntry { void *key; union { //Because there are multiple types of value, value uses union to store void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; next node The address is used to handle collisions, and the elements assigned to the same index form a linked list. Do you remember that there is also an entry in HashMap, the same concept} dictEntry;
dictht
Implementing a hash table will use a bucket to store the address of dictEntry . Generally, the value obtained by hash(key)%len is the index of buckets. This value determines which index of buckets we want to put this dictEntry node into. This Buckets are actually what we call hash tables. The table in the dictt structure of dict.h stores the addresses of buckets
/* This is our hash table structure . Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht { dictEntry **table; buckets address unsigned long size; buckets Size, always kept as 2^n unsigned long sizemask; mask, used to calculate the buckets index corresponding to the hash value unsigned long used; how many dictEntry nodes the current dicttht has } dicttht;
dict
Dictht is the core of hash, but only one dicttht is not enough, such as rehash, traversal hash and other operations, so redis defines a dict to support various operations of the dictionary. When dicttht needs to expand/shrink, it is used to manage dicttht Migration , the source code is as follows:
typedef struct dict { dictType *type; dictType stores a bunch of function pointers of utility functions void *privdata; saves data dictht ht[2] that some functions in type need as parameters ; two dictht, ht[0] Usually used, ht[1] is used for rehash (for example, rehash is required when expanding capacity) long rehashidx; /* rehashing not in progress if rehashidx == -1 */ Which index of the current rehash to buckets, -1 means non-rehash status unsigned long iterators; /* number of iterators currently running */ count of safe iterators. } dict;
For example, if we want to store a piece of data in a hash table, we will first calculate the hashcode corresponding to the key through murmur, and then obtain the location of the bucket according to the modulo of the hashcode, and then insert it into the linked list. map sketch:

Use summary:
127.0.0.1:6379> hset has tfield value
(integer) 1
127.0.0.1:6379> hset has tfield1 value1
(integer) 1
127.0.0.1:6379> hgetall has
1) "tfield"
2) "value"
3) "tfield1"
4) "value1"
127.0.0.1:6379> hget has tfield
"value"
127.0.0.1:6379> hdel has tfield
(integer) 1
127.0.0.1:6379> hgetall has
1) "tfield1"
2) "value1"
4. Collection type
Collection set, unordered and non-repetitive. Common operations of collection types are to add or delete elements to the collection, and to determine whether an element exists. Since the collection type is an empty hash table (hash table) used inside redis, the time complexity of these operations is O(1).
The underlying data structure of Set is stored in intset or hashtable. When the set contains only integer elements, intset is used for storage, otherwise, hashtable is used for storage, but for set, the value of the hashtable is used to be NULL. Store elements by key. The graph is similar to hash, except that the value in the entry uses the field.
Use summary:
127.0.0.1:6379> sadd b b
(integer) 1
127.0.0.1:6379> sadd b c
(integer) 1
127.0.0.1:6379> sadd c c
(integer) 1
127.0.0.1:6379> SMEMBERS b
1) "c"
2) "b"
127.0.0.1:6379> SISMEMBER b c
(integer) 1
127.0.0.1:6379> SREM bc
(integer) 1
127.0.0.1:6379> SMEMBERS b
1) "b"
5. Ordered collection
An ordered set actually associates a score with each element, and the scores can be the same. The encoding of an ordered collection object can be ziplist or skiplist. Use ziplist encoding when the following conditions are met at the same time:
The number of elements is less than 128
The length of all members is less than 64 bytes
The upper limit of the above two conditions can be modified by zset-max-ziplist-entries and zset-max-ziplist-value. The ziplist-encoded ordered collection is stored using compressed list nodes that are next to each other, the first node holds the member, and the second holds the score. The collection elements in the ziplist are sorted by score from small to large, and those with smaller scores are listed at the header.
The bottom layer of the skiplist-encoded ordered set is a structure named zset, and a zset structure contains both a dictionary and a skip list. The jump table saves all collection elements according to score from small to large . The dictionary saves the mapping from member to score, so that the score value corresponding to member can be found with O(1) complexity. Although the two structures are used at the same time, they will share the member and score of the same element through pointers, so no additional memory will be wasted.
So what is a skiplist?
Skip List (skip List) is a randomized data structure based on a parallel linked list, which is simple to implement, and the complexity of insertion, deletion, and search is O(logN). Simply put, the jump list is also a kind of linked list , but it adds a jump function on the basis of the linked list. It is this jump function that enables the jump list to provide O(logN) time complexity when searching for elements.

In such a linked list, if we want to find a certain data, we need to compare one by one from the beginning until we find the node containing the data, or find the first node larger than the given data (not found). That is, the time complexity is O(n). Similarly, when we want to insert new data, we have to go through the same search process to determine the insertion position.
If we add a pointer for every two adjacent nodes , let the pointer point to the next node, as shown in the figure below:

In this way, all newly added pointers are connected into a new linked list, but the number of nodes it contains is only half of the original number (7, 19, 26 in the above figure). Now when we want to find data, we can first search along this new linked list. When encountering a node larger than the data to be checked, return to the original linked list to search. For example, if we want to search for 23, the search path is along the direction pointed by the red pointer in the figure below:
-
- 23 is first compared with 7, then compared with 19, larger than them all, and continues to compare backwards.
- But when 23 is compared with 26, it is smaller than 26, so go back to the linked list below (the original linked list) and compare it with 22.
- 23 is greater than 22, follow the pointer below to compare with 26. 23 is smaller than 26, indicating that the data to be checked 23 does not exist in the original linked list, and its insertion position should be between 22 and 26.
In this search process, due to the newly added pointer, we no longer need to compare with each node in the linked list one by one. The number of nodes that need to be compared is only about half of the original.
Using the same method, we can continue to add a pointer for every two adjacent nodes on the newly generated linked list in the upper layer, thereby generating a third layer linked list. As shown below:

In this new three-layer linked list structure, if we still search for 23, then the first thing to compare along the top linked list is 19, and find that 23 is larger than 19, and then we know that we only need to go to the back of 19 to continue searching. Thus, all the nodes in front of 19 are skipped at once. It is conceivable that when the linked list is long enough, this multi-layer linked list search method allows us to skip many lower-level nodes, greatly speeding up the search.
Skiplist was inspired by the idea of this multi-layer linked list. In fact, according to the method of generating linked lists above, the number of nodes in each layer of the upper layer is half of the number of nodes in the lower layer, so the search process is very similar to a binary search, so that the time complexity of the search can be reduced to O(log n) . However, this method has a big problem when inserting data . After a new node is inserted, the strict 2:1 correspondence between the number of nodes on the upper and lower adjacent linked lists will be disrupted. If you want to maintain this correspondence, you must readjust all the nodes behind the newly inserted node (including the newly inserted node), which will reduce the time complexity to O(n). Deleting data has the same problem.
In order to avoid this problem, skiplist does not require a strict correspondence between the number of nodes between the upper and lower adjacent linked lists, but randomly selects a level for each node . For example, if the number of layers randomly obtained by a node is 3, then it is linked into the three-layer linked list from layer 1 to layer 3. In order to express clearly, the following figure shows how to form a skiplist through a step-by-step insertion operation:

From the creation and insertion process of the skiplist above, it can be seen that the level of each node is randomly selected , and a new insertion of a node will not affect the levels of other nodes. Therefore, the insertion operation only needs to modify the pointers before and after the inserted node, and does not need to adjust many nodes . This reduces the complexity of the insert operation. In fact, this is a very important feature of skiplist, which makes it significantly better than the balanced tree solution in insertion performance . This will be mentioned later.
Skiplist refers to that in addition to the bottom 1 linked list, it will generate several layers of sparse linked lists , and the pointers in these linked lists deliberately skip some nodes (and the higher the linked list, the more nodes are skipped). This allows us to search in the high-level linked list first when searching for data, then lower it layer by layer, and finally drop to the first-level linked list to accurately determine the data location . In this process, we skip some nodes, which also speeds up the search.
The skiplist just created contains a total of 4 layers of linked lists. Now suppose we still search for 23 in it. The following figure shows the search path:

It should be noted that the insertion process of each node demonstrated above actually goes through a similar search process before insertion, and the insertion operation is completed after the insertion position is determined.
Each node of the skiplist in practical applications should contain two parts, key and value . In the previous description, we did not specifically distinguish between key and value, but in fact the list is sorted according to key (score), and the search process is also compared according to key.
The process of calculating random numbers when performing insertion operations is a critical process, which has a significant impact on the statistical properties of skiplist. This is not an ordinary random number subject to uniform distribution , its calculation process is as follows:
- First of all, each node must have a layer 1 pointer (every node is in the layer 1 linked list).
- If a node has a pointer to layer i (i>=1) (that is, the node is already in the linked list from layer 1 to layer i), then the probability that it has a pointer to layer (i+1) is p.
- The maximum number of layers of a node is not allowed to exceed a maximum value, recorded as MaxLevel.
Comparison of skiplist with balanced tree and hash table
The elements of skiplist and various balanced trees (such as AVL, red-black tree, etc.) are arranged in order, while the hash table is not in order. Therefore, only a single key search can be done on the hash table, and it is not suitable for range search. The so-called range search refers to finding all nodes whose size is between two specified values.
Balanced trees are more complex than skiplist operations when doing range lookups. On the balanced tree, after we find a small value in the specified range, we need to continue to search for other nodes that do not exceed the large value in the order of the in-order traversal. The in-order traversal here is not easy to implement without some modifications to the balanced tree. It is very simple to perform a range search on the skiplist. It only needs to traverse the linked list of the first layer for several steps after finding the small value.
The insertion and deletion operations of the balanced tree may cause the adjustment of the subtree, which is complex in logic, while the insertion and deletion of the skiplist only need to modify the pointers of adjacent nodes, which is simple and fast.
In terms of memory usage, skiplist is more flexible than balanced tree. Generally speaking, each node of the balanced tree contains 2 pointers (pointing to the left and right subtrees respectively), and the number of pointers contained in each node of the skiplist is 1/(1-p) on average, depending on the size of the parameter p. If p=1/4 is taken like the implementation in Redis, then each node contains 1.33 pointers on average, which is more advantageous than the balanced tree.
The time complexity of finding a single key, skiplist and balanced tree is O(log n), which is roughly the same; while the hash table maintains a low hash value collision probability, the search time complexity is close to O(1) , with higher performance. Therefore, the various Map or dictionary structures we usually use are mostly implemented based on hash tables.
Compared with the difficulty of algorithm implementation, skiplist is much simpler than balanced tree.
Use summary:
127.0.0.1:6379> zadd zset-key 728 members1
(integer) 1
127.0.0.1:6379> zadd zset-key 733 members2
(integer) 1
127.0.0.1:6379> zadd zset-key 299 members3
(integer) 1
127.0.0.1:6379> ZRANGE zset-key 0 -1
1) "members3"
2) "members1"
3) "members2"
127.0.0.1:6379> ZRANGEBYSCORE zset-key 0 500
1) "members3"
127.0.0.1:6379> ZREM zset-key members3
(integer) 1
Reference: https://www.jianshu.com/p/cc379427ef9d
Reference: https://blog.csdn.net/qq_35433716/article/details/82177585
Reference: "Redis Combat"