About optimal adjustment function
Remove the package: https://ptorch.com/docs/1/optim
class torch.optim.Optimizer (params, defaults)
base class for all optimization.
parameter:
params (iterable) - Iteration of Variable or can dict. Specify which variables should be optimized.
defaults- (dict): dict defaults include optimization options (set a parameter is not specified parameters option will use the default value).
load_state_dict (state_dict)
loading state optimizer
parameter:
state_dict (dict) - the state optimizer. It should be state_dict () object calls returned.
state_dict ()
state optimizer returns a dict.
It contains two elements:
state - dict hold the current state of optimization. It contains the differences between the optimized class.
param_groups - a dict contains all the parameters set.
step (closure)
to perform a single optimization step (parameter update).
Different optimization Operators
Reference: Mo annoying video Great God, do not give direct Baidu search portal like;
Firstly, four basic operators replacement optimized code:
SGD is stochastic gradient descent
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
momentum accelerated momentum, momentum can specify the value of the function in SGD
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
RMSprop specify the parameters alpha
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
Adam parameters betas = (0.9, 0.99)
= torch.optim.Adam opt_Adam (net_Adam.parameters (), LR = LR, betas = (0.9, 0.99))
# look at the official document
class torch.optim.Adam (params, lr = 0.001 , betas = (0.9, 0.999), eps = 1e-08 , weight_decay = 0) [source]
to achieve Adam algorithm.
It Adam: presented in A Method for Stochastic Optimization.
#parameter:
params (iterable) – 用于优化的可以迭代参数或定义参数组
lr (float, 可选) – 学习率(默认:1e-3)
betas (Tuple[float, float], 可选) – 用于计算梯度运行平均值及其平方的系数(默认:0.9, 0.999)
eps (float, 可选) – 增加分母的数值以提高数值稳定性(默认:1e-8)
weight_decay (float, 可选) – 权重衰减(L2范数)(默认: 0)
step(closure) #执行单个优化步骤。
#parameter:
closure (callable,可选) – 重新评估模型并返回损失的闭包。
Note: momentum gradient descent method is a common acceleration. For the SGD general, the expression is, decrease in the negative gradient direction. SGD and painting with momentum term is of the form:
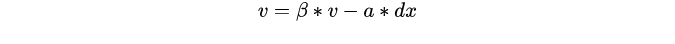
That is where the momentum factor, the popular understanding of the above formula is, if the last momentum (that is) and this time the negative gradient direction is the same, that the magnitude of the decline will increase, so this can be achieved accelerating convergence the process of.
About learning rate adjustment
first in the beginning of time we can give our neural network attach a "experiential" learning rate:
lr=1e-3 #SGD
lr = 1e-3 #Adam generally require relatively small learning rate
Next, assume that for different layers want to give different rates of learning how to do it?
Reference: https://www.cnblogs.com/hellcat/p/8496727.html
# Direct the development of different modules for different network learning rate classifiter learning rate is set to 1e-2, all of the momentum = 0.9
optimizer = optim.SGD([{‘params’: net.features.parameters()}, # 默认lr是1e-5
{‘params’: net.classifiter.parameters(), ‘lr’: 1e-2}], lr=1e-5,momentum=0.9)
## ======================= layer units to specify different rates for different layers of learning
Extract the specified object layer ## classifiter module 0th and 3rd
special_layers = t.nn.ModuleList([net.classifiter[0], net.classifiter[3]])
Gets the id layer parameters ##
special_layers_params = list(map(id, special_layers.parameters()))
print(special_layers_params)
## id acquisition parameters unspecified layer
filter = base_params (the lambda P: Not in special_layers_params id§, net.parameters ())
Optimizer t.optim.SGD = ([{ 'the params': base_params},
{ 'the params': special_layers.parameters (), 'LR' : 0.01}], lr = 0.001 )
when you discover your loss in the training process actually has risen, so generally speaking, are you at this time of the learning rate is set too big. This time we need to adjust our dynamic learning rate:
def adjust_learning_rate(optimizer, epoch, t=10):
“”“Sets the learning rate to the initial LR decayed by 10 every t epochs,default=10"”"
new_lr = lr * (0.1 ** (epoch // t))
for param_group in optimizer.param_groups:
param_group[‘lr’] = new_lr
官方文档中还给出用
torch.optim.lr_scheduler provides a number of methods based on the number of cycles to adjust the learning rate.
torch.optim.lr_scheduler.ReduceLROnPlateau based on the authentication result of the measurement to set different learning rate.
Reference: https://ptorch.com/docs/1/optim
Other parameter adjustment strategy
1.L2- regularization prevent over-fitting
weight decay (decay weight), the ultimate purpose is to prevent over-fitting. In machine learning or pattern recognition, there will be overfitting, and when the network gradually overfitting network weights gradually become larger, and therefore, in order to avoid overfitting, the error function will add a penalty term commonly used term is heavy punishment ownership square multiplied by a decay constant sum. It used to punish large weights. In the loss function, weight decay is on the regularization term (regularization) a coefficient foregoing, regularization term complexity generally indicate the model, so the weight decay of the role is to regulate the influence complexity of the model of the loss function, if the weight large decay , the value of the loss of function of complex models also large.
This is defined by the optimizer when parameter [weight_decay, 0.0005] to set general recommendations:
= torch.optim.Adam opt_Adam (net_Adam.parameters (), LR = LR, betas = (0.9, 0.99), eps = 1E-06, weight_decay = 0.0005)
2, BATCH Normalization. BATCH normalization refers to the front of the activation function in the neural network, will be in accordance with the normalization features, benefits of doing so are threefold:
Increase gradient in the network flow. Normalization can be made wherein all scaled to [0,1], so retrograde propagation time is about 1, to avoid the phenomenon of the disappearance of the gradient.
Enhance the learning rate. Data normalized to quickly reach convergence.
Reduce dependence on training model initialization.
Parameter selection dependent reduction of
some of the usual explanation: https://blog.csdn.net/hjimce/article/details/50866313
3, dropout layer was added: typically set to 0.5 dropout
4, integrated approach
Finally, in the training process on loss of some notes:
Reference: https://blog.csdn.net/LIYUAN123ZHOUHUI/article/details/74453980
1 Train Loss declining, test loss declining, indicating that the network is learning
2 train loss declining, test loss tends to be unchanged, indicating that the network had fitting
3 train loss tends to be constant, test loss tends to be unchanged, indicating learning encounter a problem, you need to reduce the learning rate or batch size
4 train loss tends to be constant, test loss declining, indicating that the data set 100% there is a problem
5 train loss rising, test loss rising (eventually becomes NaN), the network structure may be poorly designed, causing the train over improper parameter setting, such as a program bug problem
Author: angnuan123
Source: CSDN
Original: https://blog.csdn.net/angnuan123/article/details/81604727
Copyright: This article is a blogger original article, reproduced, please attach Bowen link!