General i.e. using dot notation: after the variable name followed by a decimal point bonding function ()
1. Digital type int ()
int transfected only pure digital strings, not the decimal point
Base conversion:
# convert the radix decimal
print (int ( '1100', 2)) # int the second parameter to the first parameter represents hexadecimal,
i.e. converting binary decimal, 1100 this binary number is converted to decimal
print (int ('14 ', 8 )) # 8 hex conversion decimal
print (int (' c ', 16)) # 16 hexadecimal decimal conversion
# 10 other binary decimal conversion, memory three methods
# 10 hexadecimal convert binary
print (bin (12)) # 0b1100 0b indicates that the following number is a binary number, Binary
# 10 decimal octal transfer
print (oct (12) ) # 0o14 0o indicates that the following number is verified octal: 14. 1 >>> * (**. 1. 8). 4 + * (** 0. 8)) octal
# 10 hex 16 hex transfer
print (hex (12) ) # 0xc 0x indicates that the following number is a hexadecimal number Hexadecima
ORDER AND DISORDER
Ordered: indexable data list
disorder: Dictionary
# variable types and immutable
variable type: value in the case of a change, id unchanged, indicating that you change the original value is
immutable : when the value is changed, id must change
Float float containing the number of decimal places
2. String str ()
converts any data type can be str (), a string type
Index
# 1, index-value (Forward + Reverse take take): only take
# S = 'Hello Big Baby ~'
# Print (S [0])
# 2, a slice (care regardless of the end, step) : new small section taken from a larger string string
# head is fixed to the left, to the right of the fixed bit is not said number of points by craniocaudal
# print (s [0: 5 ]) # hello care regardless tail is 0--4 said actual position to just take
# print (s [0: 10 : 1]) # hello step is not written, by default. 1
# Print (S [0: 10: 2]) represented by step # 2, represents every few steps take a
negative index: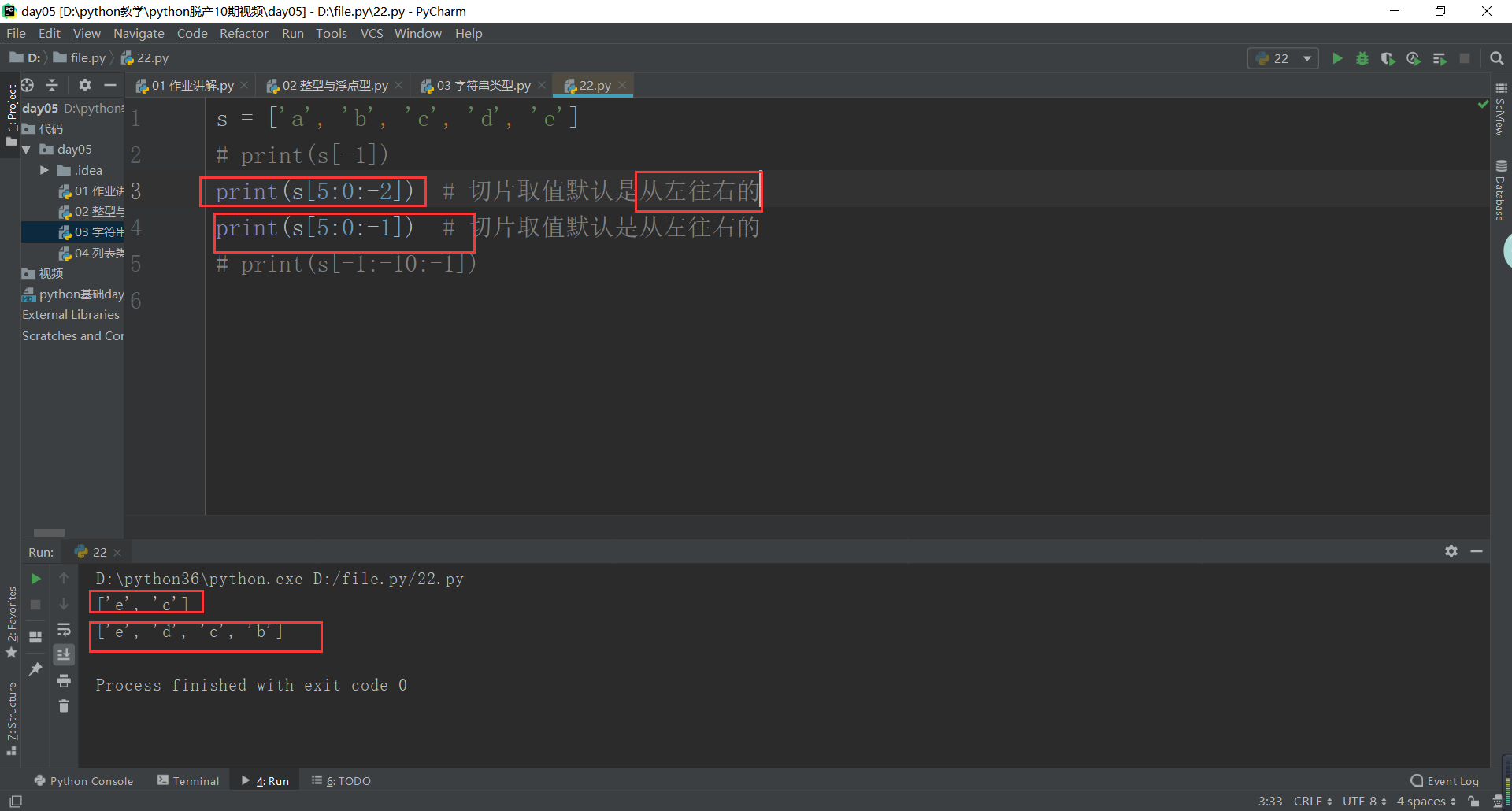
3. The length len () count the number of characters in the string
S1 = ''
Print (len (S1)) # said spaces in a character string, the result is a
Members in operation and not in: determining whether there is a sub-string in a large string:
# Print ( 'Egon' in 'Egon Egon IS and IS DSB SB')
# Print ( 'G' in 'IS DSB Egon Egon iS SB and ')
# Print (' Jason 'not in' Egon Egon iS and iS DSB SB ')
to a Boolean value
4. removing both sides of whitespace Strip ()
# NAME1 = 'Jason'
# = NAME2 'Jason' .strip ()
# Print (== NAME1 NAME2)
= NAME3 'ON $$$$ $$$$$ EG $'
Print (name3.strip ( '$')) EG # $ $ ON remove both sides
= NAME4 'Jason & *% ¥ #'
Print (name4.strip ( '*% ¥ #')) # & Jason selected character is removed on both sides
PS:
# rstrip () lstrip ()
# name5 = 'Jason $$$$ $$$$'
# Print (name5.lstrip ( '$')) # left left left delete selected character
# print (name5.rstrip ( '$')) # delete the right right right of the selected characters
The segmentation split () some of the original string delimiter and split () is divided into a list of values
= Data 'n-JASO | 123 | Handsome'
Print (data.split ( '|')) # [ 'n-JASO', '123', 'Handsome']
the original character string '|' as delimiters , divided into lists, lists, lists (something important to say three times)
list will no longer have the original character delimiter '|'
'
Data =' n-JASO | 123 | Handsome '
# Print (data.split (' O ')) # [' JAS ',' n-| 123 | Hands', 'Me'] actually cut the order from left to right
# print (data.split ( 'o' , 1)) # [ 'jas', 'n | 123 | handsome'] actually cut the order from left to right cut only a
# print (data.rsplit ( 'o' , 1)) # [ 'jaso n | 123 | hands', 'me'] series cut actually cut from right to left only a
# so if you do not specify then split and rsplit effect is the same
6. # 3, startswith, endswith Boolean value
# S1 = 'Egon DSB IS'
# Print (s1.startswith ( 'E')) # what determines whether a string begins with
# print (s1.endswith ( 'n' ) if) # determine what string to the end
7.format three kinds of games are played
one by occupying the position d% s% consistent with old programmers prefer%, but now recommended python with the format
# str1 = 'My name Age IS IS {} {} My'. The format ( 'Jason', 18 is)
# = str1 'My name Age IS IS {} {} My'. the format (18 is, 'Jason',)
# Print (str1)
Secondly by index placeholder
str1 = 'My. 1} {0} {My name IS {0} {0} Age IS'. The format ( 'Egon', 18 is)
Print (str1) # 18 is My name IS Egon Egon My Age is egon
Third placeholder name names (keyword parameter passing)
# = str1 'My name {name} {IS} My Age Age IS {name} {name}'. The format (name = 'Jason', Age = 18 is)
# print (str1)
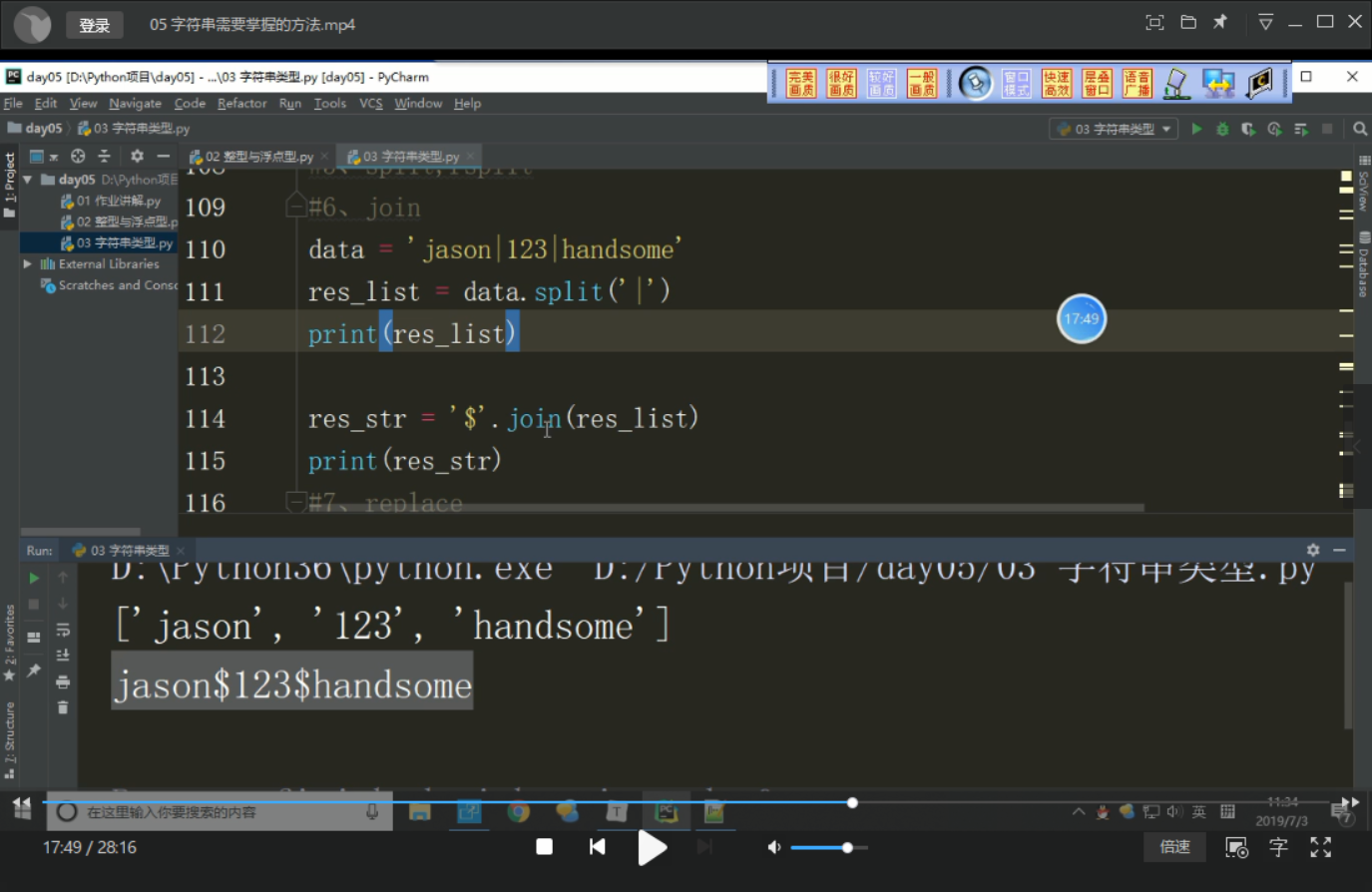
8.join () splice
# Data = 'Jason | 123 | Handsome'
# res_list = data.split ( '|')
# Print (res_list)
# res_str = '$' the Join (res_list) # plurality of container type. elements assembled into a string of characters designated by
# print (res_str)
# l = ['1','a','b'] # 1|a|b 要注意列表中的数据类型必须相同,不能是[1,'a','b']
# res = '|'.join(l)
# print(res)
9.replace()替换
str = 'egon is dsb and egon is sb he has a BENZ'
res = str.replace('egon','kevin',1)
print(res) # 把原字符串中的'egon'替换成'kevin',1表示从左往右只替换一个,
# 没有1则会全部替换
10.indaigit # 判断字符串中包含的是否为纯数字
# while True:
# age = input('>>>:')
# if age.isdigit(): #如果input中的字符串是纯整数则执行该if中的代码块
# age = int(age) #要注意输入<=28的纯整数时,会在此行断掉继续执行while循环
# if age > 28:
# print('阿姨好')
# else: # 如果不是纯整数则执行else代码块
# print('你他妈的能不能好好输')
12.ps:索引系列
# 需要了解的内置方法
# 1、find,rfind,index,rindex,count
s = 'kevin is dsb o and kevin is sb'
# print(s.find('dsb')) # 返回的是d字符所在的索引值
# print(s.find('xxx')) # 找不到的时候不报错返回的是-1
# print(s.find('i',0,3)) # 还可以通过索引来限制查找范围
# print(s.index('o')) # 返回所传字符所在的索引值
# print(s.index('i',0,3)) # 返回所传字符所在的索引值 会报错
# print(s.count('n')) # 统计字符出现的次数
13.center,ljust,rjust,zfill 填充系列
s9 = 'jason'
# print(s9.center(12,'*')) # ***jason**** 总共12个字符jason居中其余依次填充'*'
# print(s9.ljust(10,'$')) # jason$$$$$ 总共10个字符jason在左依次填充’$'
# print(s9.rjust(9,'$')) # $$$$jason 总共9个字符jason在右依次填充’$'
# print(s9.zfill(11)) # 000000jason 总共11个字符jason前方依次填充’0'
14.expandtabs() 扩展
# s10 = 'a\tbc'
# print(s10.expandtabs(100))
captalize,swapcase,title 字母大写系列
# s12 = 'hElLo WoRLD sH10'
# print(s12.capitalize()) # Hello world 首字母大写
# print(s12.swapcase()) # 大小写互换
# print(s12.title()) # 每个单词的首字母大小
15.is开头数字识别系列
num1 = b'4' # bytes
num2 = u'4' # unicode,python3中无需加u就是unicode
num3 = '壹' # 中文数字
num4 = 'Ⅳ' # 罗马数字
# ''.isnumeric(): unicode,中文数字,罗马数字 只要是表示数字都识别
print(num2.isnumeric()) # True
print(num3.isnumeric()) # True
print(num4.isnumeric()) # True
# ''.isdecimal(): unicode 只识别普通的阿拉伯数字
print(num2.isdecimal()) # True
print(num3.isdecimal()) # False
print(num4.isdecimal()) # True
# ''.isdigit() :bytes,unicode 通常情况下使用isdigit就已经满足需求了
print(num1.isdigit()) # True
print(num2.isdigit()) # True
print(num3.isdigit()) # False
print(num4.isdigit()) # False
16.list()构建列表
l1=list({'name':'jason','password':'123'})
print(l1) # ['name', 'password'] list只取字典中的key值构成列表
# list内部原理就是for循环取值 然后一个个塞到列表中去
# l=list('abc') # ['a', 'b', 'c']
17.索引系列
test描述:
# l = ['a', 'b', 'c', 'd']
# print(l[0:4:1]) # ['a', 'b', 'c', 'd'] 实际只取0到3位 步长为1
# print(l[0::]) # ['a', 'b', 'c', 'd'] 未指定步长的情况下,默认为1
# print(l[2::-1]) # ['c', 'b', 'a'] 顾头不顾尾,从第二位开始,步长为-1,往负轴方向索引,直至索引到结束
# print(l[5::-1]) # ['d','c', 'b', 'a'] 因为总共只有0到3位,5已经超出第三位,所以只能从第三位开始负向取值,直至索引结束
# print(id(l))
18.添加系列 append() insert()
1 = [99, 88, 77, 66]
# [11,22,33,44,55,99,88,77,66]
# 1.尾部添加一个66
# l.append(66) # 注意append值能将被添加的数据当作列表的一个元素
# print(l)
# l.insert(2,96) # [99, 88, 96, 77, 66] 通过索引在第二位置添加元素
# print(l) # 注意insert值能将被添加的数据当作列表的一个元素
# l.extend([1,2,3,]) # [99, 88, 77, 66, 1, 2, 3]将列表中的元素依次追加到列表l末尾
# print(l)
19.删除与弹出 del pop()
l = [1, 2, 3, 4, ]
# del l[2] # [1, 2, 4] del适用于所有的删除操作,删除的值不可用
# print(l)
# res1 = l.pop() # 尾部弹出
# res2 = l.pop()
# res3 = l.pop()
# print(res1,res2,res3) # 4 3 2 弹出的值还可用
# res = l.remove(3) # 指定要删除的元素的值
# print(l)
# print(res) # [1, 2, 4]