In the segmentation algorithm On (1) the basic points of Words of us discussed based word dictionary-based word into two categories word in segmentation algorithm (2) On the segmentation method dictionary-based paper, we use the n-gram realized Segmenting Dictionary. In (1), we have also discussed this approach some flaws, is the problem of OOV that, for unknown words will expire, and briefly describes how to word based on the word, under article focuses on how to use elaborate HMM Based word segmentation method.
table of Contents
On the segmentation algorithm (1) basic points of Words in
Discussion segmentation algorithm (2) Segmenting dictionary based
Discussion segmentation algorithm (3) Segmenting character (HMM) based
Discussion segmentation algorithm (4) based on sub-word word methods (CRF)
on the segmentation algorithm (5) based on the word segmentation method (LSTM)
Hidden Markov Models (Hidden Markov Model, HMM)
First, we will briefly introduce the HMM. HMM comprising the pentad:
- State value set Q = {q1, q2, ..., qN}, where N is the number of possible states;
- Observations set V = {v1, v2, ..., vM}, where M is the number of possible observation;
- Transition probability matrix A = [aij], where aij represents the transition from state i to state j probability;
- Emission probability matrix (also called the observation probability matrix) B = [bj (k)], where bj (k) represents the probability of generating the observed vk conditions in state j;
- Initial state distribution π.
Generally, the HMM model is represented as λ = (A, B, π), state sequence is I, corresponding to the measured observation sequence is O. For the three basic parameters, HMM there are three basic questions:
- Probability calculation, the probability of the observation sequence O model appears at [lambda];
- Learning problems, the known observation sequence O, estimate model parameters [lambda], so that in this model the observation sequence P (O | λ) maximum;
- Decoding (Decoding) problem with the known models λ observation sequence O, solving the conditional probability P (I | O) of the maximum state sequence I.
HMM word
In (1) we have discussed based word segmentation, how the word is converted into a sequence tag question, here we briefly discusses the concepts under the HMM for word. The collective state values of Q is set {B, E, M, S }, each word indicating the start, end, middle (begin, end, middle), and independent characters into words (SINGLE); Chinese sentence is the sequence of observations. For example, "a nice day" to get state sequence "BEBEBE" by solving the HMM, the word is "today / Weather / good."
By way of example above, we found that Chinese word decoding task corresponding to the question: for string C = {c1, ..., cn }, the maximum conditional probability solve 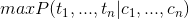
wherein, ti ci representing the character corresponding state.
Two assumptions
In seeking conditional probability
we can use Bayes' formula was 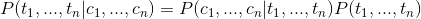
similar to the case of n-gram, we need to make two assumptions to reduce the sparsity:
- Limited historic assumptions: ti determined only by ti-1
- Independent Output assumed: ci received signal at time i is determined only by the transmission signal ti
I.e. as follows: 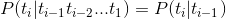
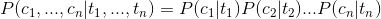
In this way we can be converted to the above formula: 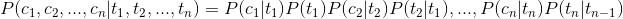
In our word segmentation status only four T i.e. {B, E, M, S }, where P (T) may be used as the prior probability by counting get, while the conditional probability P (C | T) that is the probability of Chinese in a word that appears under the conditions of a state, can be obtained by counting the frequency of training corpus.
Viterbi algorithm
With these stuff, how can we solve the optimal state sequence it? The solution is the Viterbi algorithm; in fact, Viterbi algorithm is essentially a dynamic programming algorithm, using the optimal path to meet such a state sequence characteristics: sub-optimal path path must be the best. State at time t is defined as the probability that the maximum value of i is δt (i), there is recursion formulas: 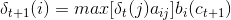
wherein, ot + 1 is the character ct + 1.
Code
We implemented a simple HMM based word, a part where I mainly extracted from the HMM segmentation jieba in [3], the specific logic is as follows:
prob_start.py defining the initial state distribution π:
P={'B': -0.26268660809250016,
'E': -3.14e+100,
'M': -3.14e+100, 'S': -1.4652633398537678}prob_trans.py transition probability matrix A:
P={'B': {'E': -0.510825623765990, 'M': -0.916290731874155}, 'E': {'B': -0.5897149736854513, 'S': -0.8085250474669937}, 'M': {'E': -0.33344856811948514, 'M': -1.2603623820268226}, 'S': {'B': -0.7211965654669841, 'S': -0.6658631448798212}}prob_emit.py defines the emission probability matrix B, for example, P ( "and" | M) represents the probability of state "and" occurrence of a case where the word M (Note: unicode characters are represented in the actual coding code) ;
P={'B': {'一': -3.6544978750449433,
'丁': -8.125041941842026, '七': -7.817392401429855, ...} 'S': {':': -15.828865681131282, '一': -4.92368982120877, ...} ...}About the Training of the model is given for an explanation: "There are two main sources, one is the Internet can be downloaded to the 1998 People's Daily corpus segmentation and a segmentation msr corpus and the other is my own collection of some of the txt fiction. with ictclas their segmentation (may have some errors) followed by a python script statistical word frequency to be counted three main probability tables: 1) the position of the transition probabilities, i.e., B (begin), M (middle), E (end ), S (separate into words) four-state transition probability; 2) position to the emission probability of the word, such as P ( "and" | M) represents the probability "and" the word appears in the middle of a word; 3) words probability in some states at the beginning, in fact, only two, either B, either S. "
In the viterbi seg_hmm.py function is as follows:
PrevStatus = {
'B': 'ES',
'M': 'MB',
'S': 'SE', 'E': 'BM' } def viterbi(obs, states, start_p, trans_p, emit_p): V = [{}] # tabular path = {} for y in states: # init V[0][y] = start_p[y] + emit_p[y].get(obs[0], MIN_FLOAT) path[y] = [y] for t in range(1, len(obs)): V.append({}) newpath = {} for y in states: em_p = emit_p[y].get(obs[t], MIN_FLOAT) (prob, state) = max( [(V[t - 1][y0] + trans_p[y0].get(y, MIN_FLOAT) + em_p, y0) for y0 in PrevStatus[y]]) V[t][y] = prob newpath[y] = path[state] + [y] path = newpath (prob, state) = max((V[len(obs) - 1][y], y) for y in 'ES') return (prob, path[state]) To adapt to the Chinese word task, Jieba of the Viterbi algorithm made the following changes:
- PrevStatus state transition should satisfy the condition, i.e., the previous state is the only state B E or S, ...
- Finally, a state can only be E or S, it represents the end of a word.
At the same time, here in the realization pushed formula, its demand for the number, multiplying transformed into adding: 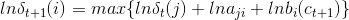
This is the probability matrix appeared negative, because it is seeking a logarithm.
Achieve results
We write a simple self-test function:
if __name__ == "__main__":
ifile = ''
ofile = ''
try:
opts, args = getopt.getopt(sys.argv[1:], "hi:o:", ["ifile=", "ofile="]) except getopt.GetoptError: print('seg_hmm.py -i <inputfile> -o <outputfile>') sys.exit(2) for opt, arg in opts: if opt == '-h': print('seg_hmm.py -i <inputfile> -o <outputfile>') sys.exit() elif opt in ("-i", "--ifile"): ifile = arg elif opt in ("-o", "--ofile"): ofile = arg with open(ifile, 'rb') as inf: for line in inf: rs = cut(line) print(' '.join(rs)) with open(ofile, 'a') as outf: outf.write(' '.join(rs) + "\n")Run as follows:
The complete code
I will complete code placed on github, similar to the above article, where the code is basically drawn from stuttering over, to facilitate access to learning, I also direct model to take over, and did not re-find corpus train, we can Chouchou:
HTTPS : //github.com/xlturing/machine-learning-journey/tree/master/seg_hmm
references
- "Statistical learning methods" Lee Hang
- [Chinese] word hidden Markov model HMM
- github jieba
- How the data model is generated stuttering
- Application A Hidden Markov Models: Chinese word
In the segmentation algorithm On (1) the basic points of Words of us discussed based word dictionary-based word into two categories word in segmentation algorithm (2) On the segmentation method dictionary-based paper, we use the n-gram realized Segmenting Dictionary. In (1), we have also discussed this approach some flaws, is the problem of OOV that, for unknown words will expire, and briefly describes how to word based on the word, under article focuses on how to use elaborate HMM Based word segmentation method.
table of Contents
On the segmentation algorithm (1) basic points of Words in
Discussion segmentation algorithm (2) Segmenting dictionary based
Discussion segmentation algorithm (3) Segmenting character (HMM) based
Discussion segmentation algorithm (4) based on sub-word word methods (CRF)
on the segmentation algorithm (5) based on the word segmentation method (LSTM)
Hidden Markov Models (Hidden Markov Model, HMM)
First, we will briefly introduce the HMM. HMM comprising the pentad:
- State value set Q = {q1, q2, ..., qN}, where N is the number of possible states;
- Observations set V = {v1, v2, ..., vM}, where M is the number of possible observation;
- Transition probability matrix A = [aij], where aij represents the transition from state i to state j probability;
- Emission probability matrix (also called the observation probability matrix) B = [bj (k)], where bj (k) represents the probability of generating the observed vk conditions in state j;
- Initial state distribution π.
Generally, the HMM model is represented as λ = (A, B, π), state sequence is I, corresponding to the measured observation sequence is O. For the three basic parameters, HMM there are three basic questions:
- Probability calculation, the probability of the observation sequence O model appears at [lambda];
- Learning problems, the known observation sequence O, estimate model parameters [lambda], so that in this model the observation sequence P (O | λ) maximum;
- Decoding (Decoding) problem with the known models λ observation sequence O, solving the conditional probability P (I | O) of the maximum state sequence I.
HMM word
In (1) we have discussed based word segmentation, how the word is converted into a sequence tag question, here we briefly discusses the concepts under the HMM for word. The collective state values of Q is set {B, E, M, S }, each word indicating the start, end, middle (begin, end, middle), and independent characters into words (SINGLE); Chinese sentence is the sequence of observations. For example, "a nice day" to get state sequence "BEBEBE" by solving the HMM, the word is "today / Weather / good."
By way of example above, we found that Chinese word decoding task corresponding to the question: for string C = {c1, ..., cn }, the maximum conditional probability solve
wherein, ti ci representing the character corresponding state.
Two assumptions
In seeking conditional probability
we can use Bayes' formula was
similar to the case of n-gram, we need to make two assumptions to reduce the sparsity:
- Limited historic assumptions: ti determined only by ti-1
- Independent Output assumed: ci received signal at time i is determined only by the transmission signal ti
I.e. as follows:
In this way we can be converted to the above formula:
In our word segmentation status only four T i.e. {B, E, M, S }, where P (T) may be used as the prior probability by counting get, while the conditional probability P (C | T) that is the probability of Chinese in a word that appears under the conditions of a state, can be obtained by counting the frequency of training corpus.
Viterbi algorithm
With these stuff, how can we solve the optimal state sequence it? The solution is the Viterbi algorithm; in fact, Viterbi algorithm is essentially a dynamic programming algorithm, using the optimal path to meet such a state sequence characteristics: sub-optimal path path must be the best. State at time t is defined as the probability that the maximum value of i is δt (i), there is recursion formulas:
wherein, ot + 1 is the character ct + 1.
Code
We implemented a simple HMM based word, a part where I mainly extracted from the HMM segmentation jieba in [3], the specific logic is as follows:
prob_start.py defining the initial state distribution π:
P={'B': -0.26268660809250016,
'E': -3.14e+100,
'M': -3.14e+100, 'S': -1.4652633398537678}prob_trans.py transition probability matrix A:
P={'B': {'E': -0.510825623765990, 'M': -0.916290731874155}, 'E': {'B': -0.5897149736854513, 'S': -0.8085250474669937}, 'M': {'E': -0.33344856811948514, 'M': -1.2603623820268226}, 'S': {'B': -0.7211965654669841, 'S': -0.6658631448798212}}prob_emit.py defines the emission probability matrix B, for example, P ( "and" | M) represents the probability of state "and" occurrence of a case where the word M (Note: unicode characters are represented in the actual coding code) ;
P={'B': {'一': -3.6544978750449433,
'丁': -8.125041941842026, '七': -7.817392401429855, ...} 'S': {':': -15.828865681131282, '一': -4.92368982120877, ...} ...}About the Training of the model is given for an explanation: "There are two main sources, one is the Internet can be downloaded to the 1998 People's Daily corpus segmentation and a segmentation msr corpus and the other is my own collection of some of the txt fiction. with ictclas their segmentation (may have some errors) followed by a python script statistical word frequency to be counted three main probability tables: 1) the position of the transition probabilities, i.e., B (begin), M (middle), E (end ), S (separate into words) four-state transition probability; 2) position to the emission probability of the word, such as P ( "and" | M) represents the probability "and" the word appears in the middle of a word; 3) words probability in some states at the beginning, in fact, only two, either B, either S. "
In the viterbi seg_hmm.py function is as follows:
PrevStatus = {
'B': 'ES',
'M': 'MB',
'S': 'SE', 'E': 'BM' } def viterbi(obs, states, start_p, trans_p, emit_p): V = [{}] # tabular path = {} for y in states: # init V[0][y] = start_p[y] + emit_p[y].get(obs[0], MIN_FLOAT) path[y] = [y] for t in range(1, len(obs)): V.append({}) newpath = {} for y in states: em_p = emit_p[y].get(obs[t], MIN_FLOAT) (prob, state) = max( [(V[t - 1][y0] + trans_p[y0].get(y, MIN_FLOAT) + em_p, y0) for y0 in PrevStatus[y]]) V[t][y] = prob newpath[y] = path[state] + [y] path = newpath (prob, state) = max((V[len(obs) - 1][y], y) for y in 'ES') return (prob, path[state]) To adapt to the Chinese word task, Jieba of the Viterbi algorithm made the following changes:
- PrevStatus state transition should satisfy the condition, i.e., the previous state is the only state B E or S, ...
- Finally, a state can only be E or S, it represents the end of a word.
At the same time, here in the realization pushed formula, its demand for the number, multiplying transformed into adding:
This is the probability matrix appeared negative, because it is seeking a logarithm.
Achieve results
We write a simple self-test function:
if __name__ == "__main__":
ifile = ''
ofile = ''
try:
opts, args = getopt.getopt(sys.argv[1:], "hi:o:", ["ifile=", "ofile="]) except getopt.GetoptError: print('seg_hmm.py -i <inputfile> -o <outputfile>') sys.exit(2) for opt, arg in opts: if opt == '-h': print('seg_hmm.py -i <inputfile> -o <outputfile>') sys.exit() elif opt in ("-i", "--ifile"): ifile = arg elif opt in ("-o", "--ofile"): ofile = arg with open(ifile, 'rb') as inf: for line in inf: rs = cut(line) print(' '.join(rs)) with open(ofile, 'a') as outf: outf.write(' '.join(rs) + "\n")Run as follows:
The complete code
I will complete code placed on github, similar to the above article, where the code is basically drawn from stuttering over, to facilitate access to learning, I also direct model to take over, and did not re-find corpus train, we can Chouchou:
HTTPS : //github.com/xlturing/machine-learning-journey/tree/master/seg_hmm
references
- "Statistical learning methods" Lee Hang
- [Chinese] word hidden Markov model HMM
- github jieba
- How the data model is generated stuttering
- Application A Hidden Markov Models: Chinese word