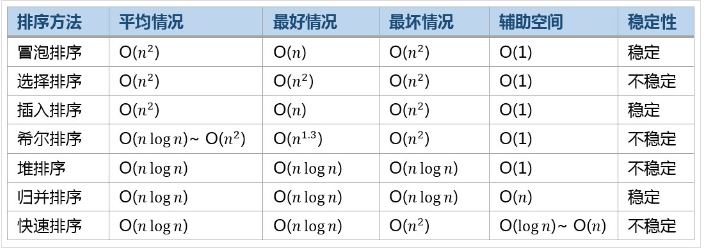
Common algorithm efficiency comparison:
A. Bubble sort
Bubble sort is a simple sorting algorithm. It repeatedly traverse the number of columns to be sorted, a comparison of two elements, if they put them in the wrong order switching over. Traversing the series of work is repeated until no longer need to swap, that is to say the number of columns already sorted completed. The origin of the name of the algorithm is because the smaller elements will slowly through the exchange of "float" to the top of the columns
1. bubble sort algorithm operates as follows:
(1) comparing adjacent elements. If the first than the second large (in ascending order), the two of them exchanged
(2) for each pair of adjacent elements for the same job from the beginning to the end of a first of the last pair. Once this is done, the last element is the largest number of
(3) repeating the above steps for all elements, except the last one
2. bubble sort of analysis:
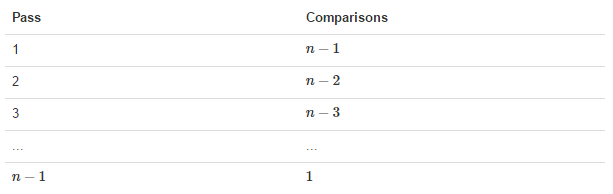
Exchange process shown (first)

So we need to n-1 times bubbling process, the number of comparisons corresponding to each as shown below
code show as below:
def bubble_sort(alist): # j为每次遍历需要比较的次数,是逐渐减小的 for j in range(len(alist)-1,0,-1): for i in range(j): if alist[i] > alist[i+1]: alist[i], alist[i+1] = alist[i+1],alist[i] li = [1,3, 4, 5, 2, 11, 6, 9, 15] bubble_sort(li) print(li)
3. 时间复杂度
算法的时间复杂度是指算法执行的过程中所需要的基本运算次数
(1)最优时间复杂度:O(n)(表示遍历一次发现没有任何可以交换的元素,排序结束)
(2)最坏时间复杂度:O(n2)
(3)稳定性:稳定
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的;否则称为不稳定的

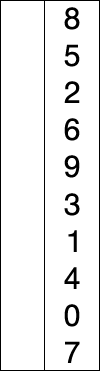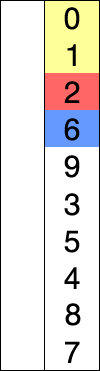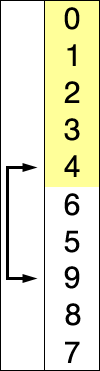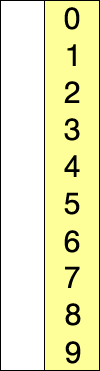 红色表示当前最小值,黄色表示已排序列,蓝色表示当前位置
红色表示当前最小值,黄色表示已排序列,蓝色表示当前位置
具体代码:
def selection_sort(alist): for i in range(len(alist)-1): min_index = i for j in range(i+1,n): if alist[j] < alist[min_index]:
# 交换下标,数据不进行交换 min_index = j if min_index != i: alist[min_index], alist[j] = alist[j], alist[min_index]
2. 时间复杂度
(1)最优时间复杂度:O(n2)
(2)最坏时间复杂度:O(n2)
(3)稳定性:不稳定(升序的时候不稳定,相等两个数的相对位置一定会发生变化)
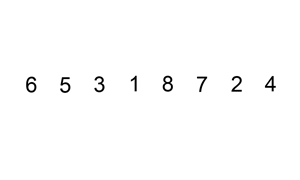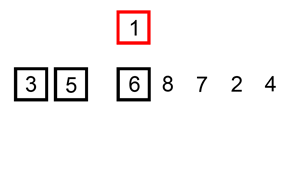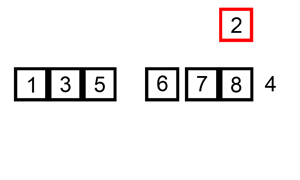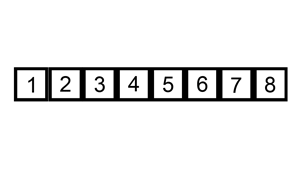
代码实现:
def insert_sort(alist): # 从第二个元素开始向前插入 for i in range(1, len(alist)): for j in range(i, 0, -1): if alist[j] < alist[j-1]: alist[j], alist[j-1] = alist[j-1], alist[j]
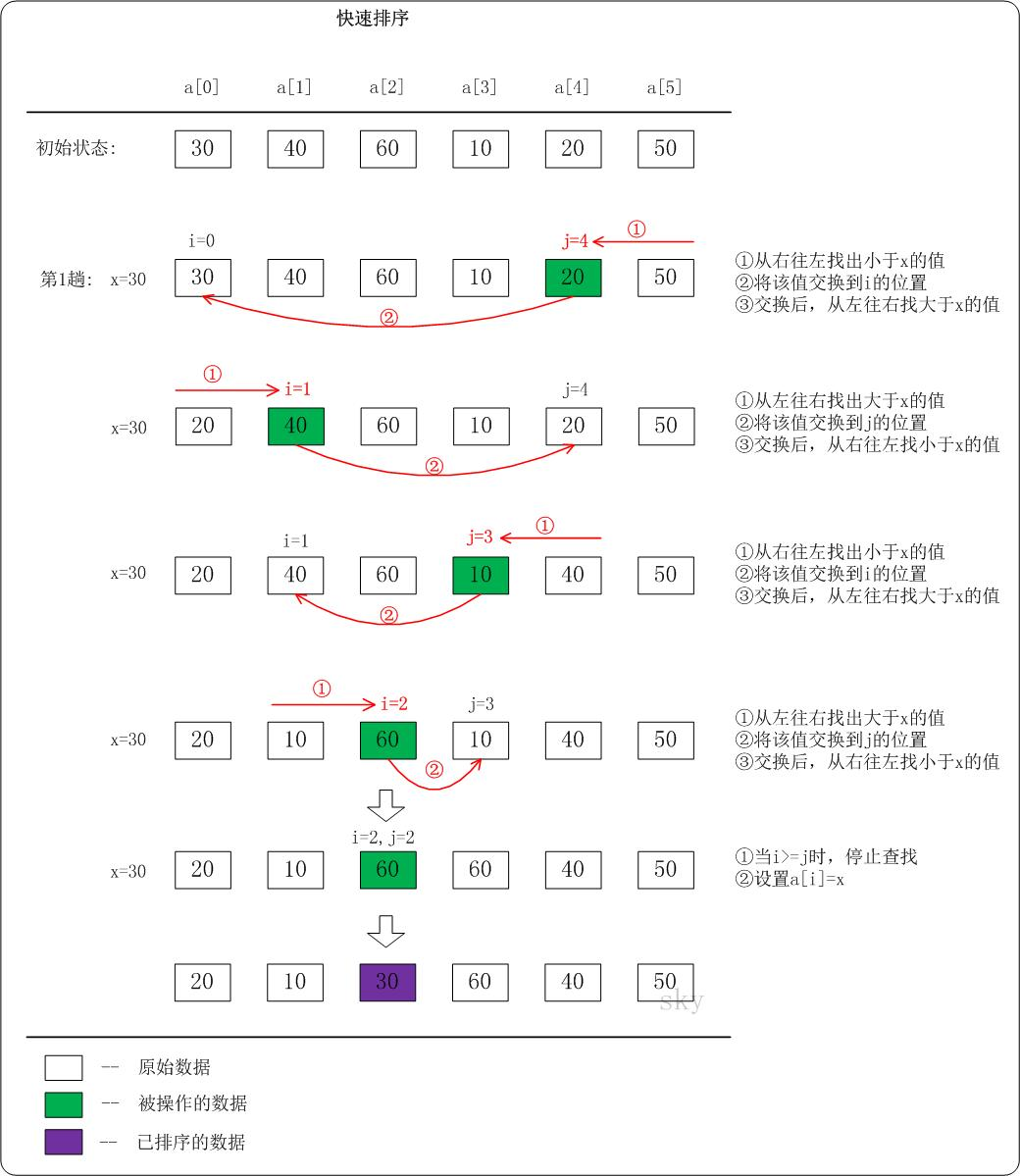
代码如下:
def quick_sort(alist, start, end): """快速排序""" # 递归的退出条件 if start >= end: return # 设定起始元素为要寻找位置的基准元素 mid = alist[start] # low为序列左边的由左向右移动的游标 low = start # high为序列右边的由右向左移动的游标 high = end while low < high: # 如果low与high未重合,high指向的元素不比基准元素小,则high向左移动 while low < high and alist[high] >= mid: high -= 1 # 将high指向的元素放到low的位置上 alist[low] = alist[high] # 如果low与high未重合,low指向的元素比基准元素小,则low向右移动 while low < high and alist[low] < mid: low += 1 # 将low指向的元素放到high的位置上 alist[high] = alist[low] # 退出循环后,low与high重合,此时所指位置为基准元素的正确位置 # 将基准元素放到该位置 alist[low] = mid # 对基准元素左边的子序列进行快速排序 quick_sort(alist, start, low-1) # 对基准元素右边的子序列进行快速排序 quick_sort(alist, low+1, end)
2. 时间复杂度
(1)最优时间复杂度:O(nlogn)
(2)最坏时间复杂度:O(n2)
(3)稳定性:不稳定
五 希尔排序过程
希尔排序是插入排序的一种,也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
1.代码实现:
def shell_sort(alist): n = len(alist) # 初始步长 gap = n / 2 while gap > 0: # 按步长进行插入排序 for i in range(gap, n): j = i # 插入排序 while j>=gap and alist[j-gap] > alist[j]: alist[j-gap], alist[j] = alist[j], alist[j-gap] j -= gap # 得到新的步长 gap = gap / 2
2. 时间复杂度
(1)最优时间复杂度:根据步长序列的不同而不同
(2)最坏时间复杂度:O(n2)
(3)稳定性:不稳定
六. 归并排序
归并排序是采用分治法(把复杂问题分解为相对简单的子问题,分别求解,最后通过组合起子问题的解的方式得到原问题的解)的一个非常典型的应用。归并排序的思想就是先递归分解数组,再合并数组
将数组分解最小之后,然后合并两个有序数组,基本思路是比较两个数组的最前面的数,水小九先取谁,取了后相应的指针就往后移一位。然后比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可
1. 归并排序分析
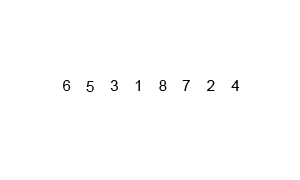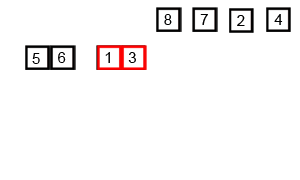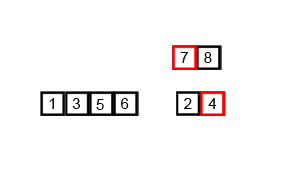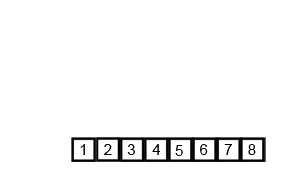
代码实现:
def merge_sort(alist): if len(alist) <= 1: return alist # 二分分解 num = len(alist)/2 left = merge_sort(alist[:num]) right = merge_sort(alist[num:]) # 合并 return merge(left,right) def merge(left, right): '''合并操作,将两个有序数组left[]和right[]合并成一个大的有序数组''' #left与right的下标指针 l, r = 0, 0 result = [] while l<len(left) and r<len(right): if left[l] < right[r]: result.append(left[l]) l += 1 else: result.append(right[r]) r += 1 result += left[l:] result += right[r:] return result
2.时间复杂度
(1)最优时间复杂度:O(nlogn)
(2)最坏时间复杂度:O(nlogn)
(3)稳定性:稳定