Exploratory analysis
3W public comment data is eight popular dessert shop reviews, contains fields: customer id, time comments, ratings, reviews, content, taste, environment, service, store ID
#引入库
import pandas as pd
from matplotlib import pyplot as plt
import pymysql
import seaborn as sns
from wordcloud import WordCloud, STOPWORDS
%matplotlib inline
Database read data
We use pymysql database connection mysql database, pd.read_sql function directly read the database connection data
#连接数据库,读入数据
db = pymysql.connect("localhost",'root','root','dianping') #服务器:localhost,用户名:root,密码:(空),数据库:TESTDB
sql = "select * from dzdp;"
data = pd.read_sql(sql,db)
db.close()
Data Summary
View the data size and basic information
data.shape
(32483, 14)
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32483 entries, 0 to 32482
Data columns (total 14 columns):
cus_id 32483 non-null object
comment_time 32483 non-null object
comment_star 32483 non-null object
cus_comment 32474 non-null object
kouwei 32483 non-null object
huanjing 32483 non-null object
fuwu 32483 non-null object
shopID 32483 non-null object
stars 26847 non-null object
year 32483 non-null object
month 32483 non-null object
weekday 32483 non-null object
hour 32483 non-null object
comment_len 32483 non-null object
dtypes: object(14)
memory usage: 3.5+ MB
data.head()
| cus_id | comment_time | comment_star | cus_comment | kouwei | huanjing | fuwu | shopID | stars | year | month | weekday | hour | comment_len | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Teddy confused | 2018-09-20 06:48:00 | Coll-str40 | South Guangzhou letter be famous dessert bar several time periods are passing on the full house watching Menus ... | very good | it is good | it is good | 518986 | 4.0 | 2018 | 9 | 3 | 6 | 184 |
| 1 | Kindergarten dominate | 2018-09-22 21:49:00 | Coll-str40 | Noon after the so-called tea bag rest will go back down to eat afternoon tea service ... | well | well | well | 518986 | 4.0 | 2018 | 9 | 5 | 21 | 266 |
| 2 | Favorite Mei Mei Xia | 2018-09-22 22:16:00 | Coll-str40 | Team sprint king to eat around Chengdu clan privileged May and friends graduation trip to Guangzhou ... | well | well | well | 518986 | 4.0 | 2018 | 9 | 5 | 22 | 341 |
| 3 | Ginger Ginger will be gained over | 2018-09-19 06:36:00 | Coll-str40 | Guangzhou to say that eating sugar will sign a letter to the South ginger milk cow red beans Pinai Samsung wonton noodles on the first floor ... | very good | well | well | 518986 | 4.0 | 2018 | 9 | 2 | 6 | 197 |
| 4 | forevercage | 2018-08-24 17:58:00 | Coll-str50 | It also has been looking forward to the most favorite dessert is very rich dessert Guangzhou before the sample had been to a lot of ... | very good | well | well | 518986 | 5.0 | 2018 | 8 | 4 | 17 | 261 |
See column where the label 'comment_star' and the tag data is processed
#查看情况
data['comment_star'].value_counts()
sml-str40 10849
sml-str50 9067
NAN 5636
sml-str30 5152
sml-str20 982
sml-str10 797
Name: comment_star, dtype: int64
#数据清洗
data.loc[data['comment_star'] == 'sml-str1','comment_star'] = 'sml-str10'
data['stars'] = data['comment_star'].str.findall(r'\d+').str.get(0)
data['stars'] = data['stars'].astype(float)/10
sns.countplot(data=data,x='stars')
<matplotlib.axes._subplots.AxesSubplot at 0x12be0396978>
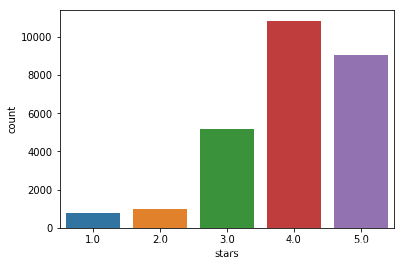
Good and Poor As can be seen in the uneven distribution, accounting for much higher than the negative feedback received, wherein the highest points Evaluation 4
sns.boxplot(data=data,x='shopID',y='stars')
<matplotlib.axes._subplots.AxesSubplot at 0x12bdf8e8400>
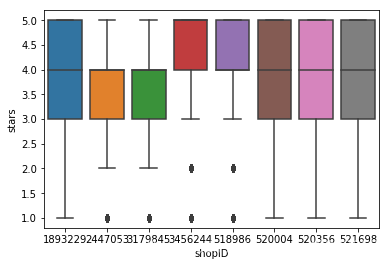
It can be seen evaluate the distribution of the stores are not the same, but have a feature scores are concentrated in the praise and the assessment
Data preprocessing
Time feature extraction
We may from time to extract a common feature of the year, month, date, day, hour, etc.
data.comment_time = pd.to_datetime(data.comment_time.str.findall(r'\d{4}-\d{2}-\d{2} .+').str.get(0))
data['year'] = data.comment_time.dt.year
data['month'] = data.comment_time.dt.month
data['weekday'] = data.comment_time.dt.weekday
data['hour'] = data.comment_time.dt.hour
#各星期的小时评论数分布图
fig1, ax1=plt.subplots(figsize=(14,4))
df=data.groupby(['hour', 'weekday']).count()['cus_id'].unstack()
df.plot(ax=ax1, style='-.')
plt.show()
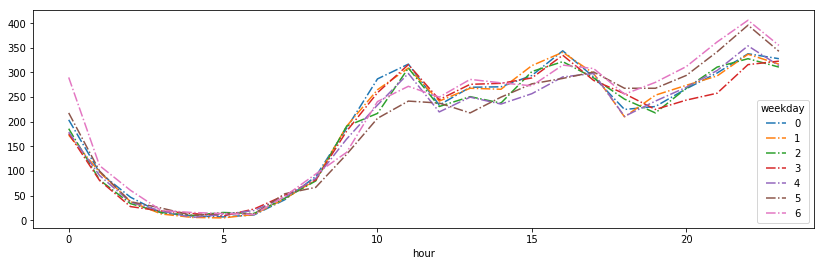
Monday to Sunday hours distribution is more similar comments, the comments appear in the peak, 11:00, 16:00 and 10:00 pm, Saturday night more active users, may be up late the next day's sake, Kazakhstan
#评论的长短可以看出评论者的认真程度
data['comment_len'] = data['cus_comment'].str.len()
fig2, ax2=plt.subplots()
sns.boxplot(x='stars',y='comment_len',data=data, ax=ax2)
ax2.set_ylim(0,600)
(0, 600)
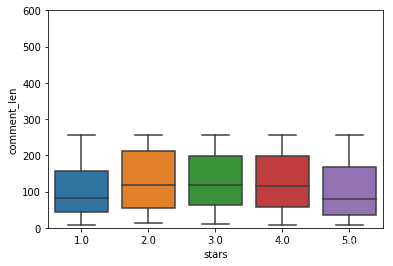
It can be seen 1 minute, 5 minutes shorter length of comments, it seems a little short comments are more efforts
Text data preprocessing
1 ** remove non-text data: ** As can be seen, a lot Reptile acquired data "\ xa0" non-text data is similar, but there are a number of meaningless data interference, such as the end of "hide comments"
data['cus_comment'][5]
'甜品 一直 是 我 的 心头肉 既然 来 了 广州 不吃 甜品 是 不会 罢休 的 可惜 还有 好几家 没有 办法 前往 南信 牛奶 甜品 专家 是 非常 火 的 甜品店 一 万多条 的 评论 就 能 看出 之 火爆 到 店 是 中午 点 左右 基本 是 爆满 还好 三楼 的 时候 刚好 有 一桌 起来 了 不然 还 真要 站 着 等 一会 先点 单 付钱 入座 等待 红豆 双皮奶 元份 等待 时 长 大概 分钟 食客 实在 太多 了 可 选择 冰热 夏天 当然 要 吃 冰 的 吃 的 有点 小 恶心 又'
#除去非文本数据和无意义文本
data['cus_comment'] = data['cus_comment'].str.replace(r'[^\u4e00-\u9fa5]','').str.replace('收起评论','')
2 ** Chinese word: ** Chinese text data processing, how to leave the Chinese word do we use jieba library, simple and easy to use. Here we have a text string as word processing segment of string space
#中文分词
import jieba
import importlib
import sys
importlib.reload(sys)
data['cus_comment'] = data['cus_comment'].astype(str).apply(lambda x:' '.join(jieba.cut(x)))
data['cus_comment'].head()
0 南信 算是 广州 著名 甜品店 吧 好几个 时间段 路过 都 是 座无虚席 看着 餐单 上 ...
1 中午 吃 完 了 所谓 的 早茶 回去 放下 行李 休息 了 会 就 来 吃 下午茶 了 服...
2 冲刺 王者 战队 吃遍 蓉城 战队 有 特权 五月份 和 好 朋友 毕业 旅行 来 了 广州...
3 都 说来 广州 吃 糖水 就要 来南信 招牌 姜撞奶 红豆 双皮奶 牛 三星 云吞面 一楼 ...
4 一直 很 期待 也 最 爱 吃 甜品 广州 的 甜品 很 丰富 很 多样 来 之前 就 一直...
Name: cus_comment, dtype: object
3 ** remove stop words: ** text, there are many valid words, such as "the," "and," there are some punctuation that we do not want to introduce at the time of the analysis of the text, and therefore need to be removed, because wordcloud and TF-IDF supports stop words, and therefore does not deal with the extra
Word cloud show
from wordcloud import WordCloud, STOPWORDS #导入模块worldcloud
from PIL import Image #导入模块PIL(Python Imaging Library)图像处理库
import numpy as np #导入模块numpy,多维数组
import matplotlib.pyplot as plt #导入模块matplotlib,作图
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['KaiTi']#作图的中文
matplotlib.rcParams['font.serif'] = ['KaiTi']#作图的中文
infile = open("stopwords.txt",encoding='utf-8')
stopwords_lst = infile.readlines()
STOPWORDS = [x.strip() for x in stopwords_lst]
stopwords = set(STOPWORDS) #设置停用词
def ciyun(shop_ID='all'):
texts = data['cus_comment']
if shop_ID == 'all':
text = ' '.join(texts)
else:
text = ' '.join(texts[data['shopID']==shop_ID])
wc = WordCloud(font_path="msyh.ttc",background_color = 'white',max_words = 100,stopwords = stopwords,
max_font_size = 80,random_state =42,margin=3) #配置词云参数
wc.generate(text) #生成词云
plt.imshow(wc,interpolation="bilinear")#作图
plt.axis("off") #不显示坐标轴
data['shopID'].unique()
array(['518986', '520004', '1893229', '520356', '3456244', '3179845',
'2447053', '521698'], dtype=object)
ciyun('520004')

#导出数据
data.to_csv('data.csv',index=False)