The only choice or general index
Business needs
Suppose you maintain a public system, each person has a unique ID number, and the service code has been written to ensure that the two will not repeat the ID number. If people need to follow the system ID number to check the name, it will execute the SQL statement like this:
select name from CUser where id_card = 'xxxxxxxyyyyyyzzzzz';In the case of identity card is not considered a good-sized field, the need for indexing to id_card, is to choose the general index is the only index it?
Query process
- 比如 select id from T where k=5
- At the beginning of the B + tree root, leaf node found by the search layer, first find the data page, in the dichotomy, locate record in the data page.
- For the general index, after finding the first record satisfying the condition (5,500), you need to find the next record, until it hits the first recording does not satisfy k = 5 condition.
- For a unique index, because the index definition uniqueness, after finding the first record that meets the conditions, it will discontinue retrieval.
- Engine is read by page, for the general index, the operation just do a search and determine the next record, if the record happens to be the last one it will be more complicated, but a data page can hold nearly a thousand key this probability is very low, so we can say that the gap is very small.
Update process
- change buffer concept
- When you need to update a data page, if the data page directly updated in memory, and if the data page has not been the case, without affecting the consistency of data in memory under the premise, InooDB these updates in change buffer cache operations , so that you do not need to read into the data page from disk. . The next time a query needs to access the data pages, the data page is read into memory and then execute change buffer in operations related to this page. In this way we can guarantee the correctness of the data logic.
- It should be noted that, although the name is called change buffer, in fact it is persistent data. In other words, change buffer has a copy in memory will be written to disk.
- The operation change buffer is applied to the original data page, get the latest result of the process is called merge. In addition to access the data page will trigger merge, the system has a background thread periodically merge. In the database normally closed (the shutdown) of the process, there will merge operation performed.
- Obviously, if we can update the first record in change buffer, reducing disk read speed of execution of the sentence will be significantly improved. Moreover, the data is read into memory need to occupy buffer pool, so in this way also can avoid occupying memory, improve memory utilization.
- Conditions of use change buffer
- For a unique index, all the update operations must first determine whether the operation violates a unique constraint. For example, to insert (4,400) this record, we must first determine whether the current record k = 4 already exist in the table, and this must want to read data pages into memory to judgment. If you have already read into memory, and that memory will be faster update directly, no need to use the change buffer.
- Therefore, the update can not use a unique index change buffer, in fact, only the general index can be used.
- When you want to update the target record page is no longer in memory, if it is a regular index update will be recorded on the buffer, the end of the statement is executed, reducing the disk io read into memory access performance.
- change buffer usage scenarios
- For the Write Once Read Many small businesses use change buffer results were better, such as billing, logging class system.
- For reading and writing less so, because the right to access the data page, you need to update the data in the buffer to the data pages, triggers merge process, so that will not reduce the number of io, increased maintenance costs of change buffer, but from the side effects.
- change buffer concept
Difference and change buffer the redo log
- Examples: mysql> insert into t (id, k) values (id1, k1), (id2, k2);
- Here, we assume that the current state of k index tree, after finding the location, where k1 data page in memory (InnoDB bufferpool), the data page is not in memory where k2
The only choice or general index
Business needs
Suppose you maintain a public system, each person has a unique ID number, and the service code has been written to ensure that the two will not repeat the ID number. If people need to follow the system ID number to check the name, it will execute the SQL statement like this:
select name from CUser where id_card = 'xxxxxxxyyyyyyzzzzz';In the case of identity card is not considered a good-sized field, the need for indexing to id_card, is to choose the general index is the only index it?
Query process
- 比如 select id from T where k=5
- At the beginning of the B + tree root, leaf node found by the search layer, first find the data page, in the dichotomy, locate record in the data page.
- For the general index, after finding the first record satisfying the condition (5,500), you need to find the next record, until it hits the first recording does not satisfy k = 5 condition.
- For a unique index, because the index definition uniqueness, after finding the first record that meets the conditions, it will discontinue retrieval.
- Engine is read by page, for the general index, the operation just do a search and determine the next record, if the record happens to be the last one it will be more complicated, but a data page can hold nearly a thousand key this probability is very low, so we can say that the gap is very small.
Update process
- change buffer concept
- When you need to update a data page, if the data page directly updated in memory, and if the data page has not been the case, without affecting the consistency of data in memory under the premise, InooDB these updates in change buffer cache operations , so that you do not need to read into the data page from disk. . The next time a query needs to access the data pages, the data page is read into memory and then execute change buffer in operations related to this page. In this way we can guarantee the correctness of the data logic.
- It should be noted that, although the name is called change buffer, in fact it is persistent data. In other words, change buffer has a copy in memory will be written to disk.
- The operation change buffer is applied to the original data page, get the latest result of the process is called merge. In addition to access the data page will trigger merge, the system has a background thread periodically merge. In the database normally closed (the shutdown) of the process, there will merge operation performed.
- Obviously, if we can update the first record in change buffer, reducing disk read speed of execution of the sentence will be significantly improved. Moreover, the data is read into memory need to occupy buffer pool, so in this way also can avoid occupying memory, improve memory utilization.
- Conditions of use change buffer
- For a unique index, all the update operations must first determine whether the operation violates a unique constraint. For example, to insert (4,400) this record, we must first determine whether the current record k = 4 already exist in the table, and this must want to read data pages into memory to judgment. If you have already read into memory, and that memory will be faster update directly, no need to use the change buffer.
- Therefore, the update can not use a unique index change buffer, in fact, only the general index can be used.
- When you want to update the target record page is no longer in memory, if it is a regular index update will be recorded on the buffer, the end of the statement is executed, reducing the disk io read into memory access performance.
- change buffer usage scenarios
- For the Write Once Read Many small businesses use change buffer results were better, such as billing, logging class system.
- For reading and writing less so, because the right to access the data page, you need to update the data in the buffer to the data pages, triggers merge process, so that will not reduce the number of io, increased maintenance costs of change buffer, but from the side effects.
- change buffer concept
Difference and change buffer the redo log
- Examples: mysql> insert into t (id, k) values (id1, k1), (id2, k2);
- Here, we assume that the current state of k index tree, after finding the location, where k1 data page in memory (InnoDB bufferpool), the data page is not in memory where k2
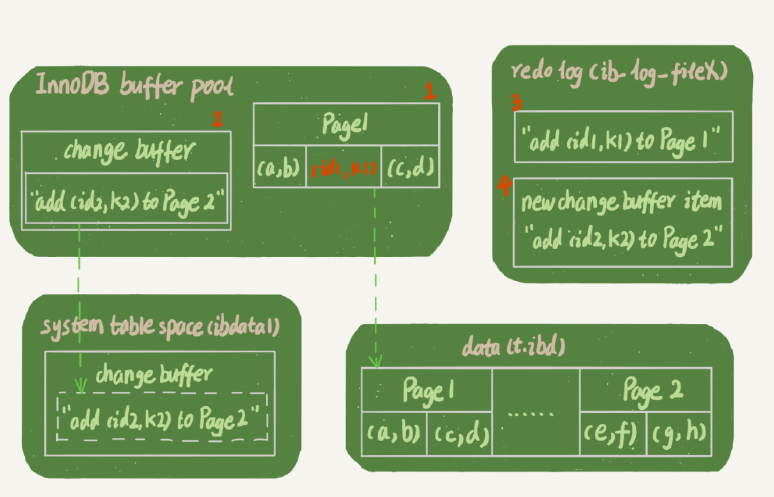
This statement follows
- Page 1 in memory, direct memory update;
- Page 2 is not in memory, just change buffer area of memory, to record "I want to insert a row into the Page 2" this information
-
- The operation of the above-described two credited redo log (Fig. 3 and 4).
- The next read request:
- Page 1 of reading time, returned directly from memory. WAL If after reading the data, do not read the disk, did not have to redo log data updates from the inside before they can return. While still on the disk before the data, but the result is returned directly from memory here, the result is correct.
- Time to read Page 2, Page 2 need to be read from disk into memory, and then apply the change buffer inside the operation log, generate a correct version and returns the result.
- It can be seen until the need to read Page 2 when the data page will be read into memory.
So, if you want to simply compare earnings of these two mechanisms on the lifting update performance, then, redo log major savings random write IO consume disk (converted into sequential write), and change buffer main savings are random read disk the IO consumption.