A, ORM common fields and parameters
1.0 Common Fields
# Auto Field:
int auto increment, must fill in the parameters primary_key = True. When the model, if there is no auto-increment, then automatically creates a column called id columns.
# IntegerField:
An integral type, in the range -2147483648 to 2147483647. (Generally do it to save the phone number (the number of bits is not enough), direct deposit with string,)
# CharField:
Character type, you must provide max_length parameters, characters indicating max_length
# DateField:
Date field, the date format YYYY-MM-DD, corresponding to the Python datetime.date () Example
# DateTimeField:
Time field, the format YYYY-MM-DD HH: MM [: ss [.uuuuuu]] [TZ], corresponding to the Python A datetime.datetime () instance.
1.1 Fields Collection (for memory)


AutoField(Field)
- int auto increment, must fill in the parameters primary_key = True
BigAutoField (Auto Field)
- bigint auto-increment, must fill in the parameters primary_key = True
Note: If no auto-increment model, automatically creates a column called id column
from django.db import models
class UserInfo (models.Model):
# automatically create a column called id and the column is an integer from growing
username = models.CharField(max_length=32)
class Group (models.Model):
# additional Customization
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
SmallIntegerField(IntegerField):
- small integers from -32768 to 32767
PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- positive small integer 0 to 32767
IntegerField(Field)
- an integer column (signed) - -2147483648 2147483647
PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- a positive integer from 0 to 2147483647
BigIntegerField(IntegerField):
- long integer (signed) -9223372036854775808 - 9223372036854775807
BooleanField(Field)
- Boolean type
NullBooleanField(Field):
- can be null Boolean
CharField(Field)
- character types
- must provide max_length parameters, max_length represent characters in length
TextField(Field)
- Text Types
EmailField(CharField):
- string type, Django Admin and authentication mechanisms provided ModelForm
IPAddressField(Field)
- string type, Django Admin IPV4 and authentication mechanisms provided ModelForm
GenericIPAddressField(Field)
- string type, Django Admin provides authentication and ModelForm Ipv4 and Ipv6
- Parameters:
protocol, specifies Ipv4 or Ipv6, 'both', " IPv4 ", " IPv6 "
unpack_ipv4, if you specify True, the input :: ffff: 192.0.2.1 when resolves to 192.0.2.1, turn on this feature, you need to = Protocol " both- "
URLField(CharField)
- string type, Django Admin provides authentication and URL ModelForm
SlugField(CharField)
- string type, Django Admin ModelForm provide authentication and support letters, numbers, underscore, hyphen (minus)
CommaSeparatedIntegerField(CharField)
- string type digital format must be a comma-separated
UUIDField(Field)
- string type, Django Admin ModelForm and provides verification of the UUID format
FilePathField(Field)
- string, Django Admin ModelForm and provides functionality to read the file folder
- Parameters:
path , the folder path to
match = None, matching canonical
recursive = False, the following folders recursively
allow_files = True, allow file
allow_folders = False, allows folder
FileField(Field)
- string path stored in the database, upload files to a specified directory
- Parameters:
upload_to = "Save Path "upload file
storage = None storage component, the default django.core.files.storage.FileSystemStorage
ImageField(FileField)
- string path stored in the database, upload files to a specified directory
- Parameters:
upload_to = "Save Path "upload file
storage = None storage component, the default django.core.files.storage.FileSystemStorage
width_field = None, database field names stored in highly upload pictures (string)
height_field = None upload pictures stored in the database field name width (string)
DateTimeField(DateField)
- date + time format YYYY-MM-DD HH: MM [: ss [.uuuuuu]] [TZ]
DateField(DateTimeCheckMixin, Field)
- Date format YYYY-MM-DD
TimeField(DateTimeCheckMixin, Field)
- Time Format HH: MM [: ss [.uuuuuu]]
DurationField(Field)
- long integer interval stored in the database in accordance with bigint, is acquired in the ORM type datetime.timedelta
FloatField(Field)
- Float
DecimalField(Field)
--10 binary decimal
- Parameters:
max_digits, fractional total length
decimal_places, fractional bit length
BinaryField(Field)
- binary type
Fields Collection
Map:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
ORM field and field correspondence between MySQL
1.2 parameter field
# null
Is used to represent a field can be empty
# unique
If you set unique = Ture
# db_index
If db_index = True represents the index field is set for this purpose.
# default
Set the default value for the field.
1.3 DateField 和 DateTimeField
# auto_now_add
Configuring auto_now_add = True, create a data record when the current time will be added to the database.
# auto_now
Configuration auto_now = True, each time when updating the data record will update the field.
二、ForeignKey
Foreign key is used to indicate the type of the foreign key relationship in the ORM, generally one of the fields provided ForeignKey 'many' in 'multiple' of.
ForeignKey can make tables and other relationships at the same time and can also make their own relationships.
2.1 parameter field
# to
Set the table to be associated
# to_field
To set the table associated fields
# on_delete
When you delete data associated table, the current table row behavior associated with it.
# models.CASCADE
Delete the associated data associated with it also deleted
# db_constraint
Whether to create a foreign key constraint in the database, the default is True.
models.DO_NOTHING Delete the associated data, causing errors IntegrityError models.PROTECT Delete the associated data, causing errors ProtectedError models.SET_NULL Delete the associated data, the value associated therewith is null (the precondition FK field should be set to be empty) models.SET_DEFAULT Delete the associated data value associated with them set to the default value (FK premise fields need to set the default value) models.SET Delete the associated data, . A set value associated with the specified value, provided: models.SET (value) . B value associated with the return value for the executable object is provided: models.SET (executable object)
def func(): return 10 class MyModel(models.Model): user = models.ForeignKey( to="User", to_field="id", on_delete=models.SET(func) )
2.2 General Operation
# Django calls in Python scripts
<img src="https://i.loli.net/2019/06/12/5d00dc63dfab377869.png"/>
Test configuration file

So that you can run your test.py file to run the test
1. Create a data method
Create Create based on # # = models.User.objects.create USER_OBJ (name = 'Tank', Age = 73 is, register_time = '2019-2-14') # Print (user_obj.register_time) # Create an object based on a binding method models.User USER_OBJ = # (name = 'Kevin', Age = 30, register_time = '2019-1-1') # user_obj.save ()
2. Modify Data
Modify data # # based on the object # USER_OBJ = models.User.objects.filter (name = 'Jason'). First () # =. 17 user_obj.age # user_obj.save () # based QuerySet # models.User.objects.filter (name = 'kevin'). update (age = 66)
3. Delete Data
Delete data # # based QuerySet # models.User.objects.filter (name = 'Egon'). Delete () # based on the object # USER_OBJ = models.User.objects.filter (name = 'Owen'). First () # user_obj.delete ()
4. query data
Single-table queries
# <1> all (): Query all results
# <2> filter (** kwargs ): it contains the given object matched filters
# res = models.User.objects.filter (name = ' jason', age = 17)
the # filter can be put more a constraint but note that the relationship between yes and multiple conditions# <3> get (** kwargs ): returns the object with the given filter criteria matches one and only one result is returned, if they meet the filter criteria or no more than one subject will throw an error. (Source ~ went to hug one interpretation of why only one object)
# does not recommend the use of
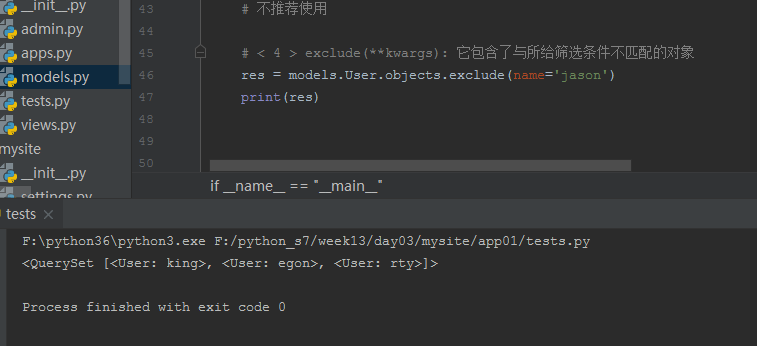
# <4> exclude (** kwargs ): it contains objects with the given filter criteria do not match
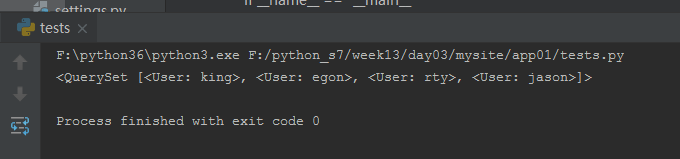
res = models.User.objects.exclude(name='jason') print(res)
# <5> order_by (* field ): order query results ( '-id') / ( '. Price')
# models.User.objects.order_by RES = ( 'Age') is ascending # default
# res = models. User.objects.order_by ( '- age') # may be a minus sign in front of the field is sorted in descending order
# models.User.objects.order_by RES = ( 'name')
# models.User.objects.order_by RES = ( '-name')
# Print (RES)

# <6> reverse (): Reverse sort query results >>> front first have to reverse the sort
# RES = models.User.objects.order_by ( 'Age') Reverse ().
# Print (RES)
# <7> count (): Returns the database that match the query (QuerySet) the number of objects.
RES = models.User.objects.count # ()
# RES = models.User.objects.all (). COUNT ()
# Print (RES)
# < 8 > first(): 返回第一条记录
# res = models.User.objects.all().first()
# res = models.User.objects.all()[0] # 不支持负数的索引取值
# print(res)
# < 9 > last(): 返回最后一条记录
# res = models.User.objects.all().last()
# print(res)
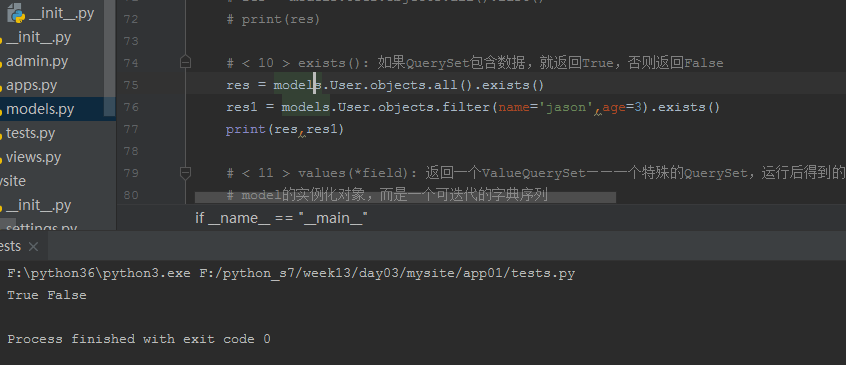
# < 10 > exists(): 如果QuerySet包含数据,就返回True,否则返回False
# res = models.User.objects.all().exists()
# res1 = models.User.objects.filter(name='jason',age=3).exists()
# print(res,res1)


# < 11 > values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
# model的实例化对象,而是一个可迭代的字典序列
# res = models.User.objects.values('name') # 列表套字典
# res = models.User.objects.values('name','age') # 列表套字典
# print(res)
# < 12 > values_list(*field): 它与values()
# 非常相似,它返回的是一个元组序列,values返回的是一个字典序列
# res = models.User.objects.values_list('name','age') # 列表套元祖
# print(res)

# < 13 > distinct(): 从返回结果中剔除重复纪录 去重的对象必须是完全相同的数据才能去重
# res = models.User.objects.values('name','age').distinct()
# print(res)

{kind=link}
神奇的双下划线语法
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") # 获取name字段包含"ven"的 models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 3]) # id范围是1到3的,等价于SQL的bettwen and 类似的还有:startswith,istartswith, endswith, iendswith date字段还可以: models.Class.objects.filter(first_day__year=2017) date字段可以通过在其后加__year,__month,__day等来获取date的特点部分数据 # date # # Entry.objects.filter(pub_date__date=datetime.date(2005, 1, 1)) # Entry.objects.filter(pub_date__date__gt=datetime.date(2005, 1, 1)) # year # # Entry.objects.filter(pub_date__year=2005) # Entry.objects.filter(pub_date__year__gte=2005) # month # # Entry.objects.filter(pub_date__month=12) # Entry.objects.filter(pub_date__month__gte=6) # day # # Entry.objects.filter(pub_date__day=3) # Entry.objects.filter(pub_date__day__gte=3) # week_day # # Entry.objects.filter(pub_date__week_day=2) # Entry.objects.filter(pub_date__week_day__gte=2) 需要注意的是在表示一年的时间的时候,我们通常用52周来表示,因为天数是不确定的,老外就是按周来计算薪资的哦~ 集锦
多表操作
1 创建数据
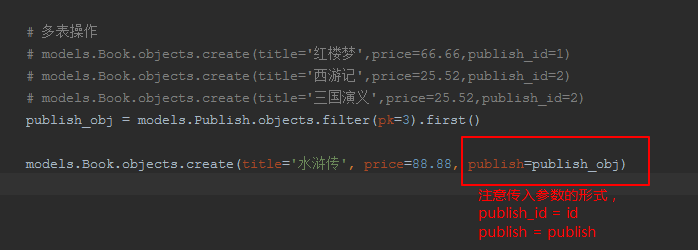
# 创建数据 # models.Book.objects.create(title='红楼梦',price=66.66,publish_id=1) # models.Book.objects.create(title='西游记',price=25.52,publish_id=2) # models.Book.objects.create(title='三国演义',price=25.52,publish_id=2) publish_obj = models.Publish.objects.filter(pk=3).first() models.Book.objects.create(title='水浒传', price=88.88, publish=publish_obj)
2 修改数据
book_obj = models.Book.objects.filter(pk=3).first()
# book_obj.publish_id=3
# book_obj.save()
# 基于对象
publish_obj = models.Publish.objects.filter(pk=2).first()
book_obj.publish = publish_obj
book_obj.save()
3 删除数据
# models.Book.objects.filter(pk=1).delete() # models.Publish.objects.filter(pk=1).delete() # book_obj = models.Book.objects.filter(pk=3).first() # book_obj.delete()
1. 正向查找(跨表)
语法:
对象.关联字段.字段
要点:先拿到外键关联多对一,一中的某个对象,由于外键字段设置在多的一方,所以这里还是借用Django提供的双下划线来查找
publisher_obj = models.Publisher.objects.first() # 找到第一个出版社对象 books = publisher_obj.book_set.all() # 找到第一个出版社出版的所有书 titles = books.values_list("title") # 找到第一个出版社出版的所有书的书名
结论:如果想通过一的那一方去查找多的一方,由于外键字段不在一这一方,所以用__set来查找即可
2.字段查找
语法:
表名__字段
要点:直接利用双下滑线完成夸表操作
titles = models.Publisher.objects.values("book__title")
三、ManyToManyField
"关联管理器"是在一对多或者多对多的关联上下文中使用的管理器。
它存在于下面两种情况:
- 外键关系的反向查询
- 多对多关联关系
简单来说就是在多对多表关系并且这一张多对多的关系表是有Django自动帮你建的情况下,下面的方法才可使用。
创建数据
新增 直接写id models.Book.objects.create(title='红楼梦',price=66.66,publish_id=1) 传数据对象 publish_obj = models.Publish.objects.filter(pk=2).first() models.Book.objects.create(title='三国演义',price=199.99,publish=publish_obj)
修改数据
修改
queryset修改
models.Book.objects.filter(pk=1).update(publish_id=3)
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.filter(pk=1).update(publish=publish_obj)
对象修改
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.publish_id = 3 # 点表中真实存在的字段名
book_obj.save()
publish_obj = models.Publish.objects.filter(pk=2).first()
book_obj.publish = publish_obj # 点orm中字段名 传该字段对应的表的数据对象
book_obj.save()
删除
删除 models.Book.objects.filter(pk=1).delete() models.Publish.objects.filter(pk=1).delete() book_obj = models.Book.objects.filter(pk=3).first() book_obj.delete()
add()
把指定的model对象添加到第三张关联表中。
给书籍绑定与作者之间的关系
添加关系 add:add支持传数字或对象,并且都可以传多个
book_obj = models.Book.objects.filter(pk=3).first()
# book_obj.authors.add(1)
# book_obj.authors.add(2,3)
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=3).first()
# book_obj.authors.add(author_obj)
book_obj.authors.add(author_obj,author_obj1)
set()
更新某个对象在第三张表中的关联对象。不同于上面的add是添加,set相当于重置
修改书籍与作者的关系 set() set传的必须是可迭代对象!!!
book_obj = models.Book.objects.filter(pk=3).first()
可以传数字和对象,并且支持传多个
book_obj.authors.set((1,))
book_obj.authors.set((1,2,3))
author_list = models.Author.objects.all()
book_obj = models.Book.objects.filter(pk=3).first()
book_obj.authors.set(author_list)
remove()
从关联对象集中移除执行的model对象(移除对象在第三张表中与某个关联对象的关系)
# 删除书籍与作者的绑定关系 # book_obj = models.Book.objects.filter(pk=3).first() # # book_obj.authors.remove(1) # # book_obj.authors.remove(2,3) # # author_obj = models.Author.objects.all().first() # author_list = models.Author. # objects.all() # # book_obj.authors.remove(author_obj) # book_obj.authors.remove(*author_list) # 需要将queryset打散
clear()
从关联对象集中移除一切对象。(移除所有与对象相关的关系信息)
book_obj = models.Book.objects.first() book_obj.authors.clear()
四、正向查询反向查询概念
# 正向与方向的概念解释 # 一对一 # 正向:author---关联字段在author表里--->authordetail 按字段 # 反向:authordetail---关联字段在author表里--->author 按表名小写 # 查询jason作者的手机号 正向查询 # 查询地址是 :山东 的作者名字 反向查询 # 一对多 # 正向:book---关联字段在book表里--->publish 按字段 # 反向:publish---关联字段在book表里--->book 按表名小写_set.all() 因为一个出版社对应着多个图书 # 多对多 # 正向:book---关联字段在book表里--->author 按字段 # 反向:author---关联字段在book表里--->book 按表名小写_set.all() 因为一个作者对应着多个图书 # 连续跨表 # 查询图书是三国演义的作者的手机号,先查书,再正向查到作者,在正向查手机号 # 总结:基于对象的查询都是子查询,这里可以用django配置文件自动打印sql语句的配置做演示
# 基于对象的表查询 # 正向 # 查询书籍是三国演义的出版社邮箱 # book_obj = models.Book.objects.filter(title='三国演义').first() # print(book_obj.publish.email) # 查询书籍是的作者的姓名 # book_obj = models.Book.objects.filter(title='').first() # print(book_obj.authors) # app01.Author.None # print(book_obj.authors.all()) # 查询作者为jason电话号码 # user_obj = models.Author.objects.filter(name='jason').first() # print(user_obj.authordetail.phone) # 反向 # 查询出版社是东方出版社出版的书籍 一对多字段的反向查询 # publish_obj = models.Publish.objects.filter(name='东方出版社').first() # print(publish_obj.book_set) # app01.Book.None # print(publish_obj.book_set.all()) # 查询作者jason写过的所有的书 多对多字段的反向查询 # author_obj = models.Author.objects.filter(name='jason').first() # print(author_obj.book_set) # app01.Book.None # print(author_obj.book_set.all()) # 查询作者电话号码是110的作者姓名 一对一字段的反向查询 # authordetail_obj = models.AuthorDetail.objects.filter(phone=110).first() # print(authordetail_obj.author.name) # 基于双下滑线的查询 # 正向 # 查询书籍为三国演义的出版社地址 # res = models.Book.objects.filter(title='三国演义').values('publish__addr','title') # print(res) # 查询书籍为的作者的姓名 # res = models.Book.objects.filter(title='啥蜀道难').values("authors__name",'title') # print(res) # 查询作者为jason的家乡 # res = models.Author.objects.filter(name='jason').values('authordetail__addr') # print(res) # 反向 # 查询南方出版社出版的书名 # res = models.Publish.objects.filter(name='南方出版社').values('book__title') # print(res) # 查询电话号码为120的作者姓名 # res = models.AuthorDetail.objects.filter(phone=120).values('author__name') # print(res) # 查询作者为jason的写的书的名字 # res = models.Author.objects.filter(name='jason').values('book__title') # print(res) # 查询书籍为三国演义的作者的电话号码 # res = models.Book.objects.filter(title='三国演义').values('authors__authordetail__phone') # print(res) # 查询jason作者的手机号 # 正向 # res = models.Author.objects.filter(name='jason').values('authordetail__phone') # print(res) # 反向 # res = models.AuthorDetail.objects.filter(author__name='jason').values('phone') # print(res) # 查询出版社为东方出版社的所有图书的名字和价格 # 正向 # res = models.Publish.objects.filter(name='东方出版社').values('book__title','book__price') # print(res) # 反向 # res = models.Book.objects.filter(publish__name='东方出版社').values('title','price') # print(res) # 查询东方出版社出版的价格大于400的书 # 正向 # res = models.Publish.objects.filter(name="东方出版社",book__price__gt=400).values('book__title','book__price') # print(res) # 反向 # res = models.Book.objects.filter(price__gt=400,publish__name='东方出版社').values('title','price') # print(res)
五、聚合查询和分组查询
1、聚合查询:利用用聚合函数
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。
键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。
导入聚合函数
# 聚合查询 aggregate from django.db.models import Max,Min,Count,Sum,Avg # 先导入 # 查询所有书籍的作者个数 # res = models.Book.objects.filter(pk=3).aggregate(count_num=Count('authors')) # print(res) # 查询所有出版社出版的书的平均价格 # res = models.Publish.objects.aggregate(avg_price=Avg('book__price')) # print(res) # 4498.636 # 统计东方出版社出版的书籍的个数 # res = models.Publish.objects.filter(name='东方出版社').aggregate(count_num=Count('book__id')) # print(res)
2、分组查询
分组查询(group_by) annotate
# 统计每个出版社出版的书的平均价格
# res = models.Publish.objects.annotate(avg_price=Avg('book__price')).values('name','avg_price')
# print(res)
# 统计每一本书的作者个数
# res = models.Book.objects.annotate(count_num=Count('authors')).values('title','count_num')
# print(res)
# 统计出每个出版社卖的最便宜的书的价格
# res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name','min_price')
# print(res)
# 查询每个作者出的书的总价格
# res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price')
# print(res)