Transfer: https: //blog.csdn.net/u014380165/article/details/88072737
Paper: Deformable ConvNets v2: More Deformable, Better Results
thesis links: https://arxiv.org/abs/1811.11168
This blog covers a very favorite target detection article: DCN v2, which is an upgraded version of Deformable ConvNets paper, to enhance the effect is obvious, idea is very simple. The main improvements include:
1, feature extraction more layers of network structure is introduced deformable convolution, the following experiments from the point of view, this operation is simple, but the effect is very obvious, but in data set using PASCAL VOC paper v1 , it is difficult to observe that the lifting part.
2, improved deformable structure, we know whether it is deformable convolution or deformable RoI pooling, mainly through the introduction of offset, so that the feature extraction process can be more focused on effective information area, and this paper introduces a modulation on the basis v1, modulation and simple Yan is the weight extracted by assigning different weights to the area after the offset correction, to achieve a more accurate features.
3, the second point is a good idea, but from the point of view of experiment (Table1 or Table2 last 2 lines of), simply by lifting the first 2:00 to bring the still relatively limited, mainly due to the existing difficult loss function supervision model for the region irrelevant to set a smaller weight, so the introduction of RCNN feature mimicking the model training phase, which in part by paper Revisiting rcnn: on awakening the classification power of inspired faster rcnn, but the implementation is not the same, this article by providing joint training RCNN effective supervision information network, to play a role in weight modulation, so that the extracted feature more focused on the effective area, and therefore point 2 is closely integrated.
First look at three visual indicators used in this article, see Figure1, Figure1 is on conventional convolution, DCNv1 and comparison chart of DCNv2, used to illustrate the effect of Deformable convolution .
1, effective sampling locations, which is valid to calculate the area, in this DCNv1 see more on the paper, in a nutshell is piled several convolution plus point forward deduced from participating in the output of a point calculated feature point area, is forward projected in Figure1 in FIG. 3 obtained layer, the points up to 9 ^ 3 = 729, because the conventional convolution overlap, seen only 49 (a first row) , because it involves a convolution variable bounds, the actual size is less than 729, typically around 200 (in the first row b).
2, effective receptive fields, i.e. effective receptive fields, can be calculated by the gradient, different from the receptive field theory.
3, error-bounded saliency region, when expressed in a complete calculation, and when the input image is calculated in only a partial region of the input image, the minimum region of the output obtained is the same model, in short, a partial region (saliency region ) affect a larger area of the model output.
Several conclusions can be obtained from the Figure1 :
1, based on the depth of the network layer is a conventional convolution target strain for a certain learning ability, such as (a) in the last row, can substantially cover the target area or a non-target area corresponding to this is mainly due to the ability to fit the depth of the network, the ability to fit a little forced fitting means, so only DCN this design.
2, DCNv1 conventional convolution strong learning ability for deformation than the target, to get more useful information. For example (b) in the last line, when the output position (FIG. 2 front), the target area affected when compared to larger conventional convolution terms.
3, DCNv2 deformation goals for learning than DCNv1 stronger, not only for more effective information, and obtain more accurate information, such as © last line, the target area is more accurate. So simple terms, DCNv1 recall in terms of effective access to information than conventional convolution, and DCNv2 not only a higher recall, and there is a high precision, in order to achieve accurate extraction of information.

Figure2 is of conventional convolution, DCNv1 and comparison of FIG DCNv2, for explaining the effect of Deformable RoI pooling .
Similar effective sampling location and meaning of the effective bin location Figure1 involved in the consistent results and the experimental results on the whole Figure1 (a) to (c) in the. (D) and (e) are introduced RCNN feature mimicking the effect of the model training phase, by comparing (c) can be clearly seen, and (d), when the last line of FIG RoI is on the target, (d) the effective regional more precise, when the RoI is not the goal, it is not very different, which later also proved (Table3). So what (e) contrast and (d) can explain? Because (e) is added to the network RCNN feature mimicking conventional convolution joint training, but the effective area (e) is not accurate, that there is no reason to introduce modulation and offset, equivalent to only supervise the information, but there is no effective point of execution, which is the more interesting local paper.

接下来大概介绍一下modulated deformable convolution,公式如下所示,△mk就是modulation要学习的参数,这个参数的取值范围是[0,1],假如去掉这个参数,那么就是DCNv1中的deformable convolution。
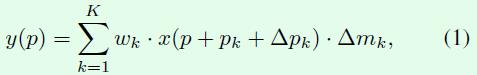
从论文来看,△pk,△mk都是通过一个卷积层进行学习,因此卷积层的通道数是3K,其中2K表示△pk,这和DCNv1的内容是一样的,剩下K个通道的输出通过sigmoid层映射成[0,1]范围的值,就得到△mk。
modulated deformable RoI pooling结构的设计也是同理,公式如下所示,假如去掉△mk参数,那么就是DCNv1中的deformable RoI pooling。
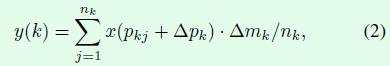
总结一下,DCN v1中引入的offset是要寻找有效信息的区域位置,DCN v2中引入modulation是要给找到的这个位置赋予权重,这两方面保证了有效信息的准确提取。
接下来看看训练阶段增加RCNN feature mimicking是如何实现的,示意图如Figure3所示,姑且称左边的网络为主网络(Faster RCNN),右边的网络为子网络(RCNN)。实现上大致是用主网络训练过程中得到的RoI去裁剪原图,然后将裁剪到的图resize到224×224大小作为子网络的输入,子网络通过RCNN算法提取特征,最终提取到14×14大小的特征图,此时再结合IoU(此时的IoU就是一整个输入图区域,也就是224×224)作为modulated deformable RoI pooling层的输入得到IoU特征,最后通过2个fc层得到1024维特征,这部分特征和主网络输出的1024维特征作为feature mimicking loss的输入,用来约束这2个特征的差异,同时子网络通过一个分类损失进行监督学习,因为并不需要回归坐标,所以没有回归损失。在inference阶段仅有主网络部分,因此这个操作不会在inference阶段增加计算成本。
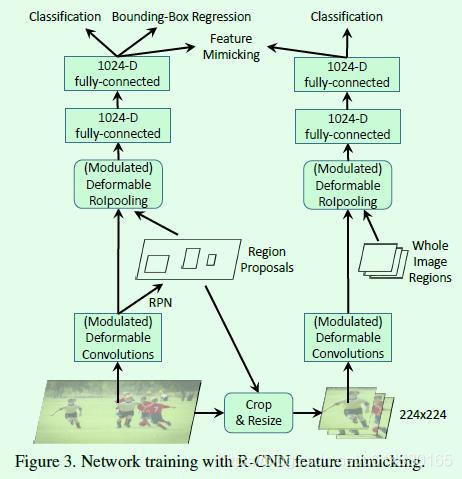
那么为什么RCNN feature mimicking方法有效?因为RCNN这个子网络的输入就是RoI在原输入图像上裁剪出来的图像,因此不存在RoI以外区域信息的干扰,这就使得RCNN这个网络训练得到的分类结果更加可靠,以此通过一个损失函数监督主网络Faster RCNN的分类支路训练就能够迫使网络提取到更多RoI内部特征,而这个迫使的过程主要就是通过添加的modulation机制和原有的offset实现。
feature mimicking loss采用cosine函数度量2个输入之间的差异,这是利用了cosine函数能够度量两个向量之间的角度的特性,其中fRCNN(b)表示子网络输出的1024维特征,fFRCNN(b)表示主网络输出的1024维特征,通过对多个RoI的损失进行求和就得到Lmimic。
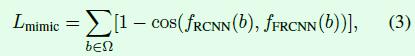
实验结果部分的内容十分丰富,依次来看看:
Table1和Table2都是在COCO 2017 val数据集上的实验结果,差别仅在于输入图像的短边处理不同,Table1是短边缩放到1000的实验结果,Table2是短边缩放到800的实验结果。以Table1为例,从dconv@c5和dconv@c4-c5这两行的对比可以直接看出即便只是简单将DCNv1中的可变卷积层扩展到c4的网络层,就能有非常明显的效果提升。正如作者所说,当初DCNv1的实验主要是在PASCAL VOC数据集上做的,因此看不到明显提升,切换到COCO数据集就不一样了,因此多关注数据集能够避免一些好的想法夭折。再看看DCNv2的第二个创新点,关于引入modulate,实验对比是dconv@c3~c5+dpool和mdconv@c3-c5+mdpool,提升有,但是不算很明显,这部分可以结合Table3中关于RCNN feature mimicking的实验一起看,在增加这个监督信息进行训练后,效果提升还是比较明显的。
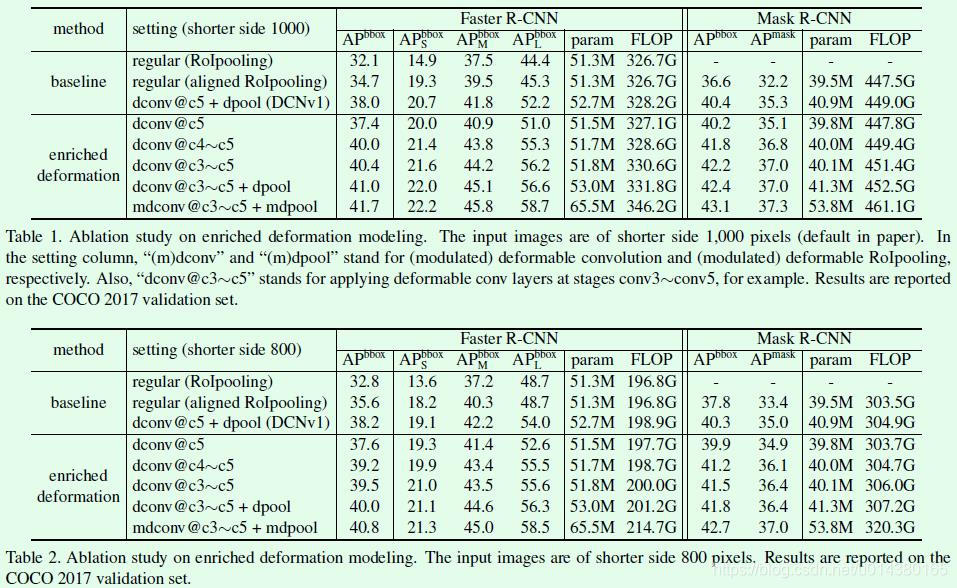
Table3是在COCO 2017 val数据集上关于RCNN feature mimicking是否有效的对比实验,可以看到在DCNv2的基础上增加foreground的IoU进行联合训练提升非常明显,而在常规卷积网络中(regular)的提升非常少,这也说明了仅有监督信息还是不够的,还需要modulation和offset扮演执行者角色进行实际操作。

Table4 test results on COCO 2017 test-dev dataset, this experiment is to verify whether the extracted valid DCNv2 thought different network characteristics, this part of the experiment on DCNv2 also introduced RCNN feature mimic loss. As it can be seen from the features of the network upgrade ResNet-50 to ResNet-101 and ResNeXt-101 extraction, detection and segmentation indicator has improved, the described design DCNv2 really effective.
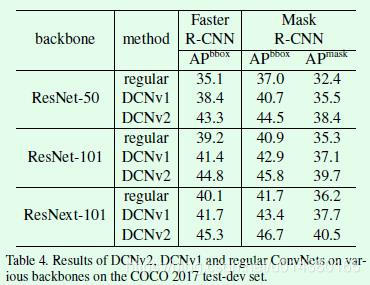
Figure4 is a conventional convolution for the input and compare the effect DCNv2 resize the image to a different size of the short side . As can be seen in the input image convolution conventional short-side dimension becomes large (such as more than 1000), but decreased the effect, especially for large size of the target is more decreased significantly, whereas no such phenomenon DCNv2.
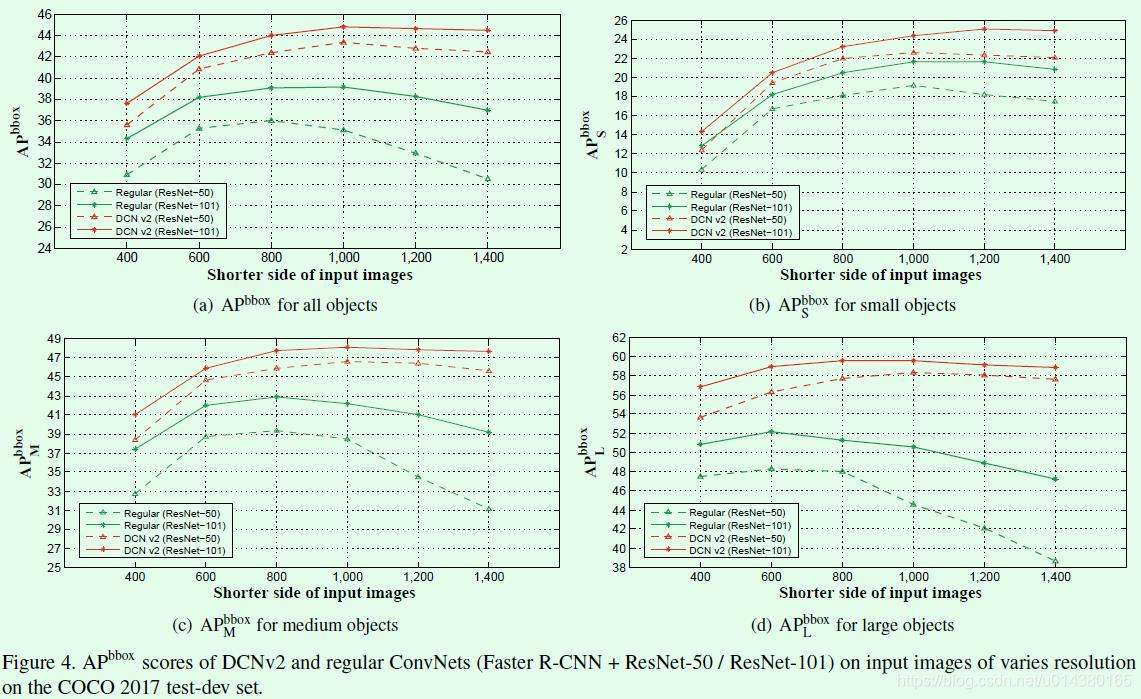
The reason for this phenomenon is that when using a conventional convolution, when the input image resolution becomes larger, the size of the corresponding target also become large, but since the conventional convolution same receptive field, it is possible to obtain characteristic information it is limited, as in FIG. 3 (a) a first row Figure5, a receptive field area in descending order. Because the receptive field by convolution DCNv2 offset and modulation control, so the target can still be obtained when the image resolution becomes large enough information, as shown in FIG. 3 of the first row Figure5 (b), the effect is substantially unaffected .

</div>