EDITORIAL: Before that needs its own Linux environment, understanding of commonly used Linux commands. And has been configured java environment, what configuration is good, that echo $ {JAVA_HOME} command is output jdk path,
Called configured. If only java -version java version can be viewed, you need to source / etc / profile command to make it effective, does not take effect is not enough drops.
First, download unzip
First, download the installation package Hadoop, the official website to download directly from the Windows on the line, which is the mirror sites, can be self-created: http: //mirror.bit.edu.cn/apache/hadoop/common/,
I downloaded version is 2.7.7 
After downloading, downloaded directly on compressed files to Linux, transmission software I use WinSCP, a long way:  As for how to use a Baidu search is very clear.
As for how to use a Baidu search is very clear.
Well, now it is the real time Linux, cd into the directory Hadoop to store compressed packages, with decompression command (tar -zxvf hadoop-2.7.7-tar.gz) to be decompressed,
Second, the configuration file
Next, to begin the configuration, into the CD etc / hadoop under Hadoop path,
1, first java path configuration, vim hadoop-env.sh edit files,
Here the java path must be equipped with their own again, do not use $ {JAVA_HOME}, or in a clustered environment, the start time will not find the java! ! ! !
: Wq to save and exit. Then perform source hadoop-env.sh make it take effect (forget is not required).
Then vim / etc / profile to open the system configuration, the configuration HADOOP environment variables. 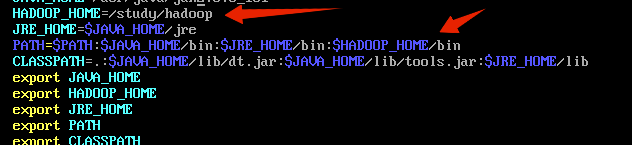 , Source make it take effect.
, Source make it take effect.
2, core-site.xml file, open a blank, add the following
<configuration> <property> <!-- The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.--> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> <!--master是Linux主机名--> </property> <property> <!--Size of read/write buffer used in SequenceFiles. byte --> <name>io.file.buffer.size</name> <value>131072</value> <!-- 大小 --> </property> <property> <!-- A base for other temporary directories. --> <name>hadoop.tmp.dir</name> <value>/study/hadoopWork/hadoop</value> <!-- 路径 -- > </property> </configuration>
3, hdfs-site.xml file
<configuration> <property> <!-- HDFS blocksize of 256MB for large file-systems. default 128MB--> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <!-- More NameNode server threads to handle RPCs from large number of DataNodes. default 10--> <name>dfs.namenode.handler.count</name> <value>100</value> </property> </configuration>
4, mapred-site.xml, this document does not need to be renamed mapred-site.xml.template
<configuration> <!-- Configurations for MapReduce Applications --> <property> <!-- Execution framework set to Hadoop YARN. --> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <!-- The amount of memory to request from the scheduler for each map task. --> <name>mapreduce.map.memory.mb</name> <value>1536</value> </property> <property> <!-- Larger heap-size for child jvms of maps. --> <name>mapreduce.map.java.opts</name> <value>-Xmx1024M</value> </property> <property> <!-- Larger resource limit for reduces. --> <name>mapreduce.reduce.memory.mb</name> <value>3072</value> </property> <property> <!-- Larger heap-size for child jvms of reduces. --> <name>mapreduce.reduce.java.opts</name> <value>-Xmx2560M</value> </property> <property> <!-- The total amount of buffer memory to use while sorting files, in megabytes. By default, gives each merge stream 1MB, which should minimize seeks.--> <name>mapreduce.task.io.sort.mb</name> <value>512</value> </property> <property> <!-- The number of streams to merge at once while sorting files. This determines the number of open file handles.--> <name>mapreduce.task.io.sort.factor</name> <value>100</value> </property> <property> <!--The default number of parallel transfers run by reduce during the copy(shuffle) phase.--> <name>mapreduce.reduce.shuffle.parallelcopies</name> <value>50</value> </property> <!--Configurations for MapReduce JobHistory Server--> <property> <!--MapReduce JobHistory Server IPC host:port--> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <!--MapReduce JobHistory Server Web UI host:port--> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <!--Directory where history files are written by MapReduce jobs.--> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/study/hadoopWork/hadoop</value> </property> <property> <!--Directory where history files are managed by the MR JobHistory Server.--> <name>mapreduce.jobhistory.done-dir</name> <value>/study/hadoopWork/hadoop</value> </property> </configuration>
5、yarn-site.xml
<configuration> <!-- Configurations for ResourceManager and NodeManager --> <property> <!-- Enable ACLs? Defaults to false. --> <name>yarn.acl.enable</name> <value>false</value> </property> <property> <!-- ACL to set admins on the cluster. ACLs are of for comma-separated-usersspacecomma-separated-groups. Defaults to special value of * which means anyone. Special value of just space means no one has access. --> <name>yarn.admin.acl</name> <value>*</value> </property> <property> <!-- Configuration to enable or disable log aggregation --> <name>yarn.log-aggregation-enable</name> <value>false</value> </property> <!-- Configurations for ResourceManager --> <property> <!-- host Single hostname that can be set in place of setting all yarn.resourcemanager*address resources. Results in default ports for ResourceManager components. --> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <!-- CapacityScheduler (recommended), FairScheduler (also recommended), or FifoScheduler --> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> <property> <!--The minimum allocation for every container request at the RM, in MBs. Memory requests lower than this will throw a InvalidResourceRequestException.--> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <property> <!--The maximum allocation for every container request at the RM, in MBs. Memory requests higher than this will throw a InvalidResourceRequestException.--> <name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value> </property> <!--Configurations for NodeManager--> <property> <!-- Defines total available resources on the NodeManager to be made available to running containers --> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> <property> <!--Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio.--> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <property> <!-- Where to store container logs. An application's localized log directory will be found in ${yarn.nodemanager.log-dirs}/application_${appid}. Individual containers' log directories will be below this, in directories named container_{$contid}. Each container directory will contain the files stderr, stdin, and syslog generated by that container.--> <name>yarn.nodemanager.log-dirs</name> <value>/study/hadoopWork/data/hadoop/log</value> </property> <property> <!--HDFS directory where the application logs are moved on application completion. Need to set appropriate permissions. Only applicable if log-aggregation is enabled. --> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/study/hadoopWork/data/hadoop/log</value> </property> </configuration>
Thus, the basic configuration has been completed, the configuration file path and so encountered, needs its own down in the appropriate directory new, you can also be configured to your own path.
6, initialization hadoop
hdfs namenode -format. If the error can not find JAVA paths, etc., went to look at their own java environment variable is not configured correctly, java path hadoop-env.sh file is not correct.
If solutions are found Baidu tried, or not, put the jdk installed uninstall and re-download and install. Be sure to clean uninstall! ! Uninstall self Baidu, when I configured a full three or four times before successfully configured.
7, start the cluster
In sbin path, perform the start-all.sh, java error solutions with 6,  Success!
Success!
Execute jps view the execution status.
Can not be a successful configuration, the configuration process, I also Baidu a lot of the older generation of information, as used herein, are similar, please understand. It is predecessors did not remember the address of the blog,
There are references to pretend it