
Everyone is welcome to Star us on GitHub:
Distributed full-link causal learning system OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Large model-driven knowledge graph OpenSPG: https://github.com/OpenSPG/openspg
Large-scale graph learning system OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
Paper title: PEACE: Prototype lEarning Augmented transferable framework for Cross-domain rEcommendation
Organizational unit: Ant Group
Admission Conference: WSDM 2024
Paper link: https://arxiv.org/abs/2312.0191 6
The author of this article: Gan Chunjing. The main research directions are graph algorithms, recommendation algorithms, large language models and the application of knowledge graphs. The research results are included in mainstream machine learning related conferences (WSDM/SIGIR/AAAI). The main work in the team in the past year has been pre-trained recommendation models based on knowledge graphs, large language models based on knowledge enhancement and their applications, including the graph neural network framework based on multi-granularity decoupling in the financial management scenario published in SIGIR'23 MGDL, the prototype learning-based entity graph pre-training cross-domain recommendation framework PEACE published at WSDM'24.
background
With the development of Alipay's mini program ecosystem, more and more merchants have begun to operate mini programs on Alipay. At the same time, Alipay also hopes to achieve a decentralized strategy through mini program ecology + merchant self-operation.
In the process of self-operation by merchants, more and more small and medium-sized merchants have the need for digital and intelligent operations, such as improving the marketing efficiency of their mini program private domain positions through personalized recommendation capabilities, but for small and medium-sized merchant companies , the technical cost and labor cost of building self-built AI personalized recommendation capabilities are very high.
In this context, we hope to provide merchants with visible but inaccessible personalized recommendation and search capabilities based on Ant's massive user behavior data to help merchants create intelligent mini programs to increase merchants' revenue on the Alipay platform and provide users with better The personalized experience can enhance user retention in Alipay, and it can also accumulate common technical solutions to further optimize the merchant/user experience.
There have been many successful application cases in the industry that use data from behaviorally rich scenarios to improve the recommendation effect in mid- and long-tail scenarios. For example, Taobao uses the behavioral data of first guess to improve the recommendation effect in other small scenarios. Fliggy uses the app and Alipay small scenarios to improve the recommendation effect. The terminal jointly models to improve the overall recommendation effect.
However, this type of method usually faces multiple recommendation scenarios with similar mentalities, and uses scenario data with rich behaviors to improve the recommendation effect of similar scenarios with sparse behaviors, such as Taobao, Fliggy, etc. However, super APPs such as Alipay usually include various mini programs such as travel, government affairs, leasing, travel, catering, daily necessities, etc. The mental differences between users in various mini programs are very large, which gives us a model Brings great challenges:
- Alipay's mini programs are scattered in vertical industries with widely different business types such as government affairs, food, leasing, retail, and financial management. Generally speaking, information is not shared between these mini programs, and similar items may not have similar attributes. When directly transferring multiple behaviors across the entire domain to a specific vertical class scenario without aligning such cross-domain differences, it is difficult for the model to learn useful knowledge for the vertical class from the mixed behaviors of multiple vertical classes, and may even be Will bring about negative migration;
- Although point-to-point user behavior migration, for example, the food industry only uses users’ catering-related behaviors on Alipay, can alleviate the above problems to a certain extent, but each time a new industry is added, manual intervention is required, which is costly and cannot realize the entire chain. In addition to road automation, some merchants also hope that the Alipay platform can provide plug-and-play personalized recommendation solutions when connecting for the first time, even when there is no user behavior data. Such a model is not feasible in this setting.
Based on the above challenges, we proposed PEACE, a graph pre-training multi-scenario transfer learning framework based on prototype learning, based on the problem of large differences between vertical industry domains.
We introduced the entity graph and hoped to use the entity graph as a bridge to connect the differences between different domains to mitigate its negative impact on modeling. However, the entity graph in the production environment is usually huge, although it contains a large number of entities. However, it will also introduce a lot of noise. Indiscriminate aggregation of structural information in the entity map will usually reduce the robustness of the model. Therefore, we introduced prototype learning to improve the entity representation and user in the modeling process. representation to constrain.
Overall, the PEACE framework is the migration design idea of ONE FOR ALL. We use users’ multi-source public domain behavior in Alipay as the input of the pre-training model, and learn the user’s interests and preferences from multiple industries into one through the idea of decoupled representation. In the model, combined with the prototype network that captures industry signals, it only needs to pre-train a unified model to adaptively migrate users' multiple interests to different downstream vertical industries for personalized recommendations (normal recommendation + zero- shot recommended).
PEACE - Entity graph pre-training cross-domain recommendation framework based on prototype learning
Preliminary knowledge-cross-domain alignment based on entity graph
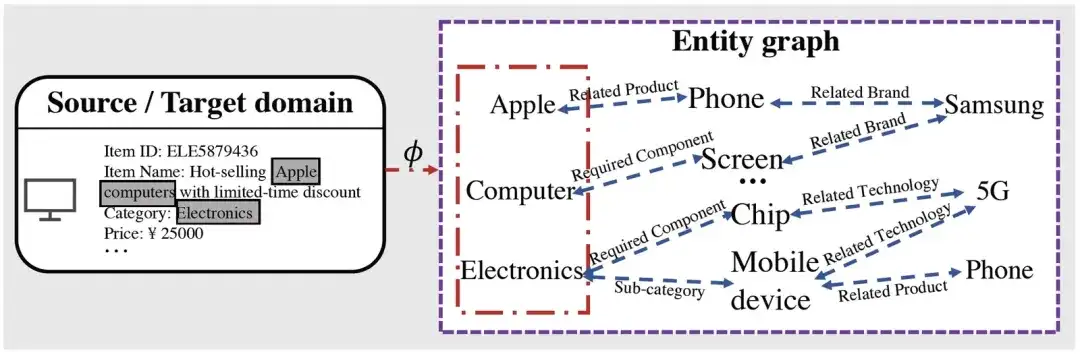

It can be seen that after obtaining the entity related to the corresponding item through mapping, based on the graph reasoning process, we can obtain a lot of high-level information related to the mapped entity. For example, Apple has mobile phone products, and companies related to mobile phone products There are Samsung, etc., which can potentially shorten the relationship with other related entities (such as mobile phones produced by Samsung, etc.).
model framework
In this section, we will introduce the graph pre-training cross-domain recommendation framework PEACE proposed in this article. The following figure shows the overall architecture of PEACE. Overall, in order to better achieve cross-domain alignment and better utilize the structural information in the entity graph, our overall framework is built on the entity-oriented pre-training module ; in order to further improve the relationship between users and entities in the pre-training module Representation to make it more versatile and transferable, we propose an entity representation enhancement module based on prototype contrast learning and a user representation enhancement module based on prototype enhancement attention mechanism to enhance its representation; on this basis, we define Optimization goals and lightweight online deployment process in the pre-training phase and fine-tuning phase . Next, we will introduce each module one by one.
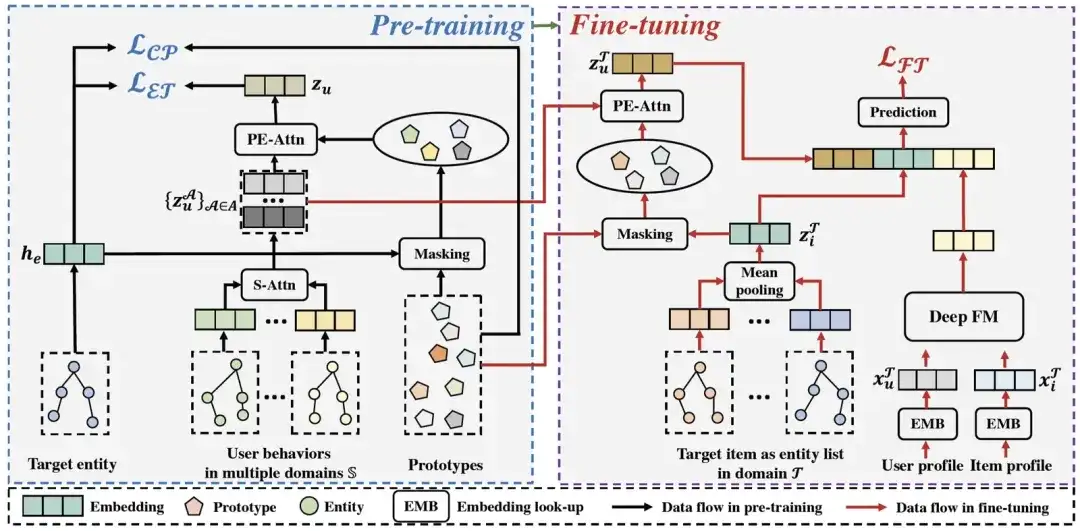
PEACE overall architecture
01. Entity-oriented pre-training module
Online service platforms such as Alipay gather a variety of small programs/scenarios provided by different service providers. Generally speaking, the information between these scenarios is not interoperable and there is no shared data system. Therefore, even if they are of the same brand and category, The attributes of the current products cannot be completely aligned (for example, iPhone 14 sold in different mini programs have different product IDs and category names. For example, the category is electronic products in one mini program, and the category is electronics in another mini program) . In order to reduce the differences caused by these potential problems and their impact on modeling performance, and at the same time make better use of this interactive information, we perform pre-training based on the entity map, hoping to introduce entity-granular information in this way. Achieve pre-training with stronger generalization.


Taking Figure 1 as an example, if it is item→entity→entity, starting from this product, for Apple, we can only know that its related products are Phone, but through pre-training from entity→entity→entity, we can know that Apple is not only With related products like Phone, we can also know that it is related to the company Samsung, thereby further improving the generalization of the representations we learned).
02. Entity representation enhancement module based on prototype contrastive learning

03. User representation enhancement module based on prototype enhanced attention mechanism
In the pre-training stage, the data collected in the source domain contains user behavior in different scenarios. For example, when making travel plans, users will visit travel-related scenarios, and when looking for a job, they will visit online job-related scenarios. , however, the user-general representation learned in the previous step does not take into account the context related to the user and the scene, which makes it impossible to capture the scene-related representation in different scenes. Therefore, we hope to use the attention mechanism to improve the context. Capture to enhance user representation.

04. Model training and prediction
- Source domain pre-training link
By combining the entity-oriented pre-training module and the prototype learning enhancement module, the overall optimization goal can be defined in the following way:
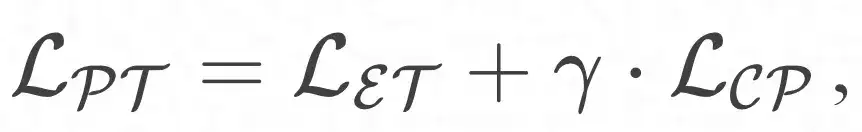

- Target domain fine-tuning link

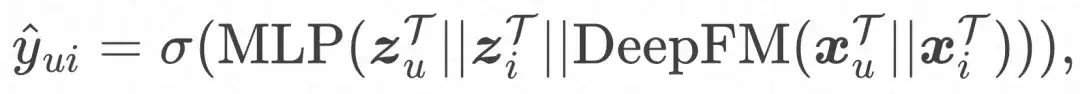
And the final loss function:
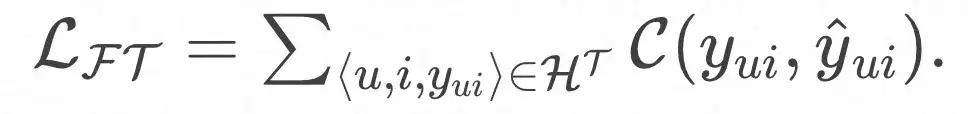

Online deployment
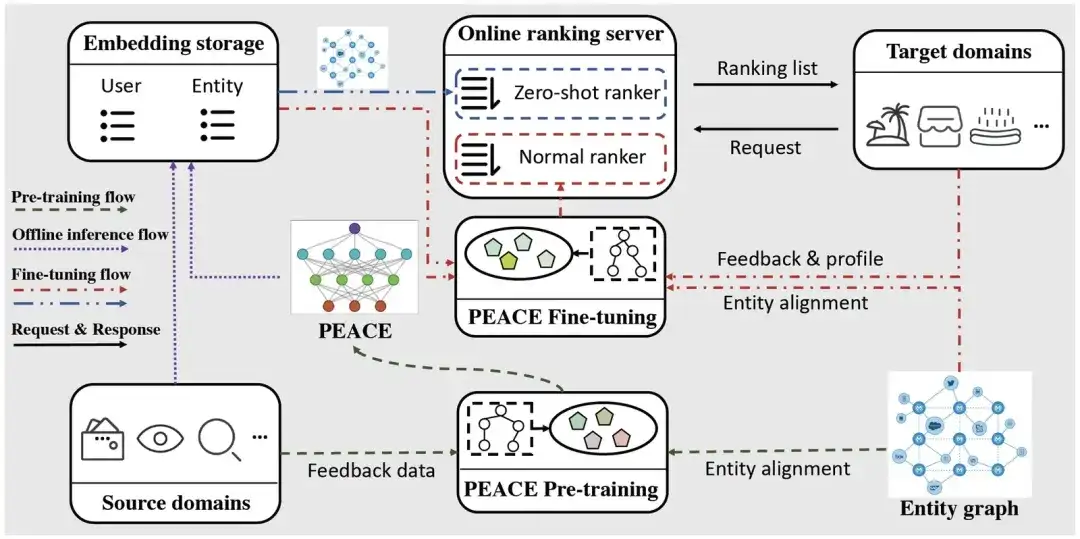
In order to alleviate the pressure on online services, we use a lightweight method to deploy the PEACE model. The deployment flow is mainly divided into three parts:
- Pre-training flow: Based on the collected multi-source behavioral data and entity maps, we update the PEACE model on a daily basis so that the model can learn time-sensitive and universal transferable knowledge. For the pre-trained model, we store it in ModelHub to facilitate lightweight loading of model parameters for downstream use.
- Offline inference flow: In order to reduce the burden brought by the graph neural network to the online service system, we will infer the representations of user and entity in advance, and then store them in the ODPS table. During downstream fine-tuning, only the final MLP The network is fine-tuned without re-doing the information propagation process in the graph neural network, thereby greatly reducing the latency of online services.
- Fine-tuning flow: Since newly launched mini programs/services do not have interactive data, PEACE provides recommendation services through the following two steps:
- For the cold start scenario, by directly doing the inner product of the user and item representations, we can obtain the user's preference for different items and directly sort them;
- For non-cold start scenarios where a certain amount of data has been accumulated, we fine-tune based on the pre-trained user/item representation and user/item basic information, and then use the fine-tuned model for online services.
Effectiveness analysis
Offline experiment
01. Data introduction
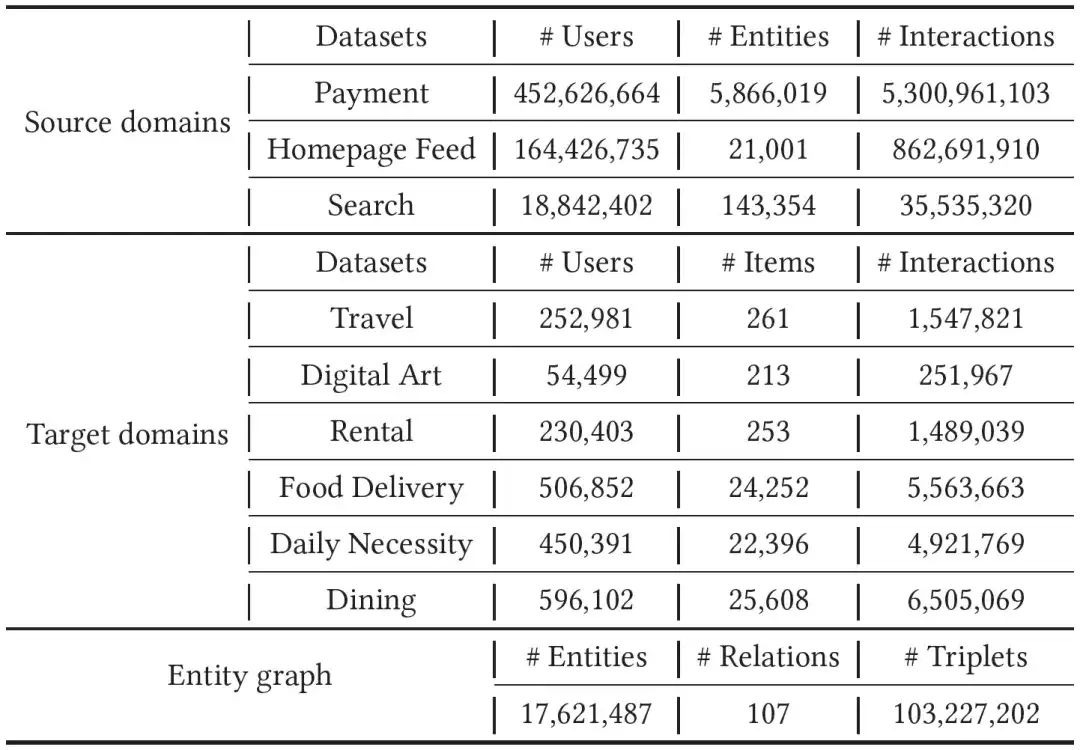
We collected one month's Alipay bills, footprints, and search data as source domain data. For the target domain, we conducted experiments on six types of mini-programs, namely rental, travel, digital collections, daily necessities, gourmet food, and food delivery. Experiment, since the target domain data is more sparse than the source domain, we collected behavioral data in the past two months for model training. In order to bridge the huge differences between different domains, we introduced an entity graph with tens of millions of nodes, hundreds of relationships, and billions of edges. Specific data can be found in the table below.
02. Effectiveness experiment
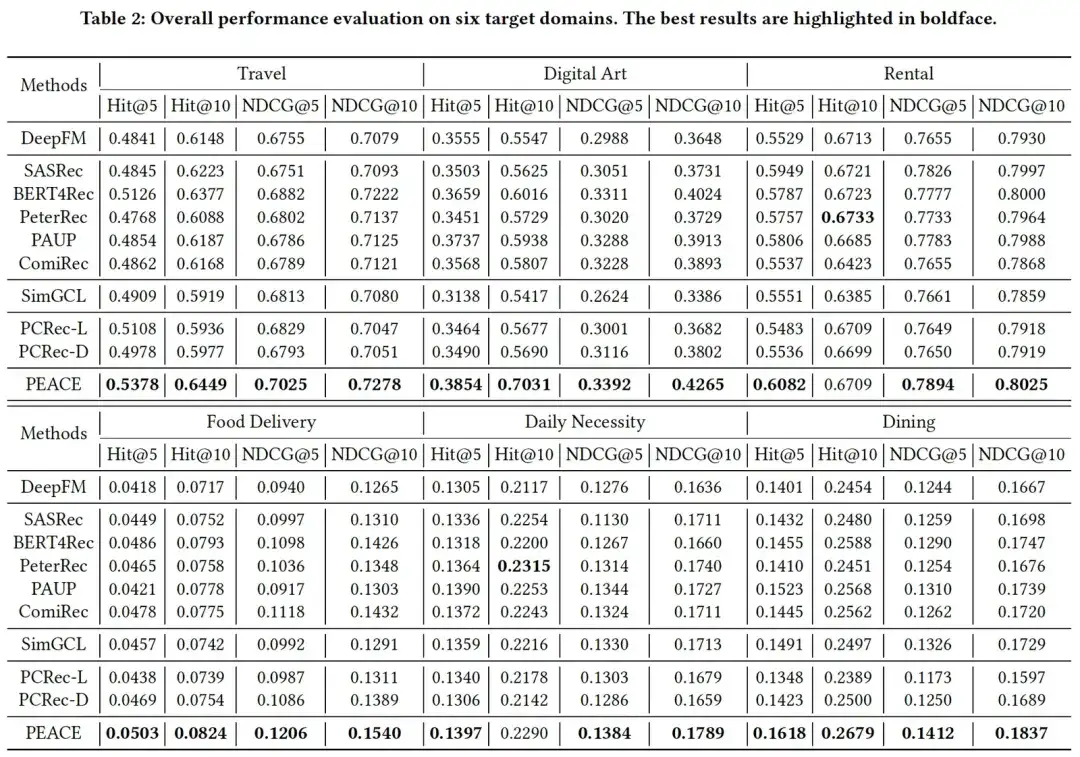
Combining the experimental results in the two tables we can find that, overall, the experimental results show:
- PEACE has achieved significant improvements compared to the baseline in both cold start/non-cold start scenarios, which demonstrates the effectiveness of the combination of entity-granularity-based pre-training and prototype learning-based enhancement mechanisms;
- In most cases, the pre-trained + fine-tuned model has a greater improvement than the baseline DeepFM without pre-training, which illustrates the effectiveness of introducing multi-source data for pre-training. However, in some cases, some The performance of the model is not as good as the baseline DeepFM, and there is a certain degree of negative transfer, which further illustrates the importance of pre-training methods;
- In many cases, cross-domain recommendation models based on gnn have not achieved good experimental results. This is largely due to the huge noise in the entity graph. Since we introduced prototype learning in the PEACE model, through clustering The class method makes similar entities have similar distances in the representation space, while the distance between different entities is stretched farther, thereby alleviating the negative impact of these noises on the model.
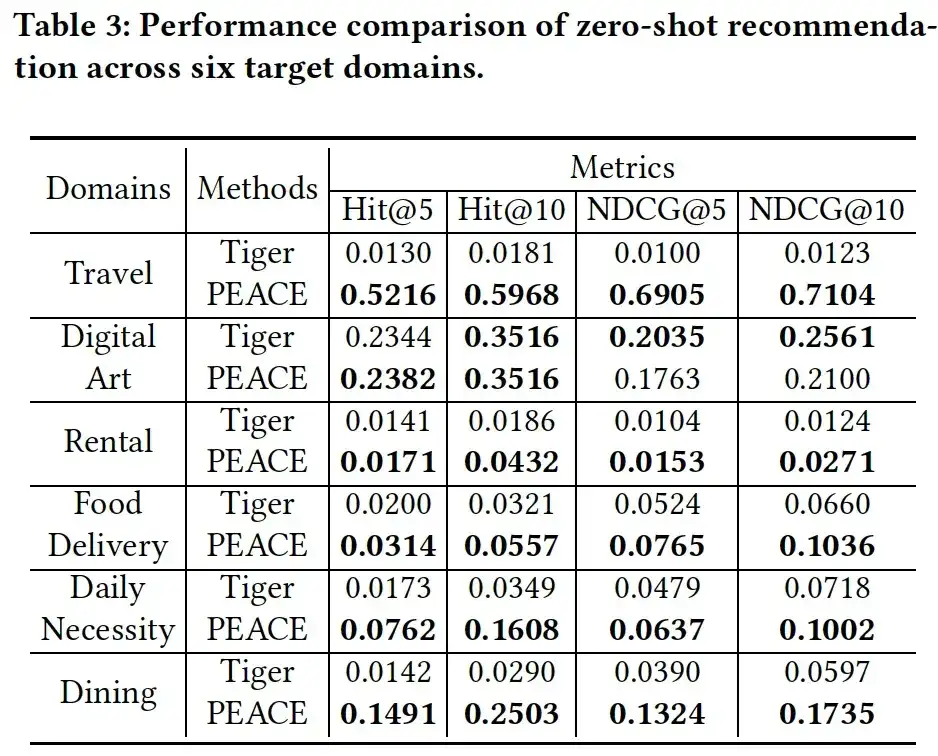
03. Ablation analysis
In order to further verify the role of each module in the PEACE model, we prepared the following three variants to evaluate the effectiveness of each module:
- PEACE w/o GL, the graph learning module when entity representations are removed;
- PEACE w/o CPL, i.e. removal of the comparison-based prototype learning module;
- PEACE w/o PEA, which removes the attention mechanism module based on prototype enhancement. As can be seen from Figure 4, when any module is removed, the model performance drops significantly, which illustrates the indispensability of each module in the model; in addition, it can be seen that the performance of PEACE w/o CPL At worst, this illustrates the importance of prototype learning in capturing general transferable knowledge.
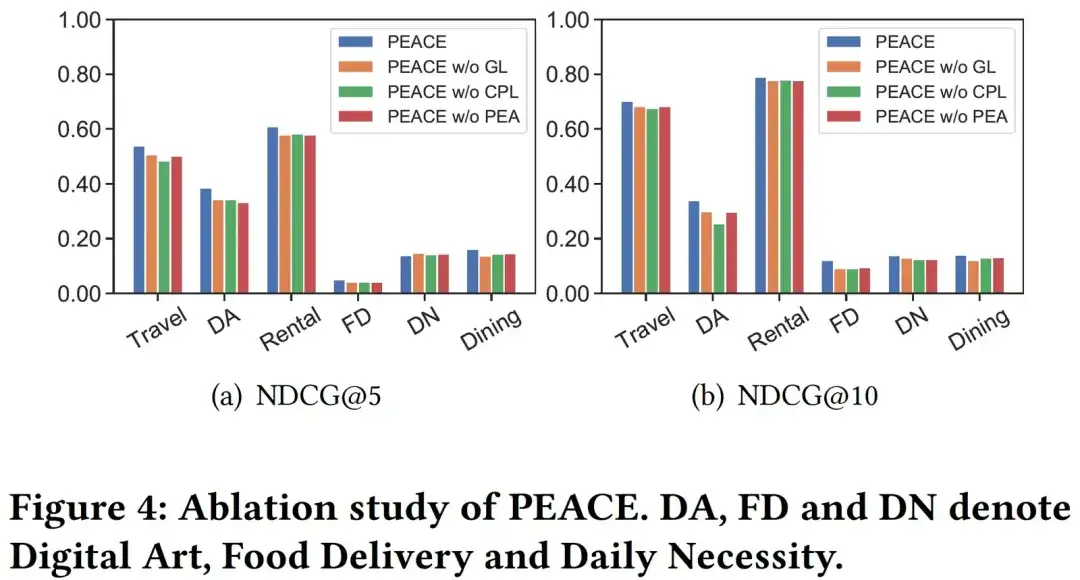
04. Visual analysis
In order to analyze the effect of the CPL module more explicitly, we randomly selected 6000 entities in the entity map and their entity representations learned through PEACE w/o CPL and PEACE models to visualize them. Here are various The colors correspond to different prototypes belonging to different entities. From Figure 5 we can see that compared to the entity representation learned by PEACE w/o CPL, the representation learned by the complete PEACE model has better coherence in the clustering results, which illustrates the CPL module and its The learned prototype can well help the model reduce the distance between similar entities in the representation space, thereby better helping the model learn more robust and universal knowledge.
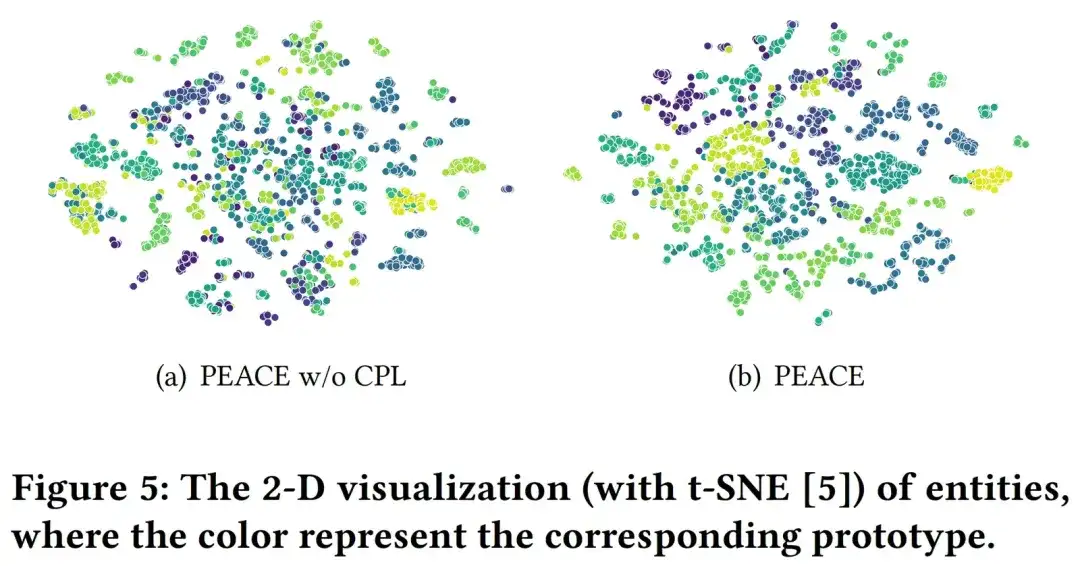
Online experiments and business implementation
In order to better verify the effect of the model in the actual production environment, we have conducted refined online AB experiments at multiple merchants in different vertical categories. In multiple scenarios, the PEACE model has achieved effective results compared to the baseline. promote. Overall, the PEACE-based pre-training + transfer learning recommendation model has been fully applied as a baseline model to 50+ merchants to provide personalized recommendations after being verified by ab effects on key merchants.
Article recommendations
OpenSPG v0.0.3 is released, adding large model unified knowledge extraction & graph visualization open source! Ant Group and Zhejiang University jointly release OneKE, an open source large model knowledge extraction framework
[Speech Review] The evolution of knowledge graphs and reasoning practice based on OpenSPG+TuGraph
Paper Digest | GPT-RE: Context learning for relation extraction based on large language models
Follow us
OpenSPG:
Official website: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
官网:https://openasce.openfinai.org/
GitHub:[https://github.com/Open-All-Scale-Causal-Engine/OpenASCE]