
Both Alibaba Cloud and Tencent Cloud have experienced situations where all availability zones were paralyzed at the same time due to a component failure. This article will explore how to reduce the fault domain from the perspective of architectural design and minimize business losses when faults occur, and take Sealos' stability practice as an example to share experiences and lessons.
Abandon master-slave and embrace peer-to-peer architecture
It can be seen from the Tencent Cloud fault report that the failure of multiple availability zones at the same time is basically caused by some centralized components, such as unified API, unified authentication and other system failures.
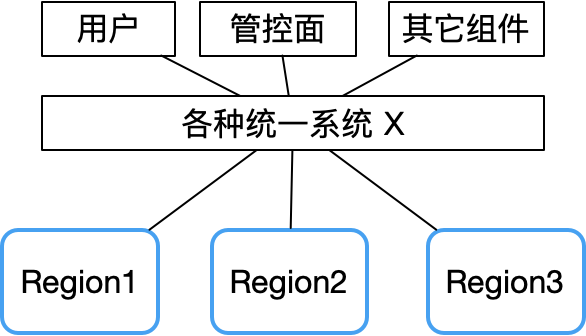
Therefore, once the X system fails, the fault domain will be very large.
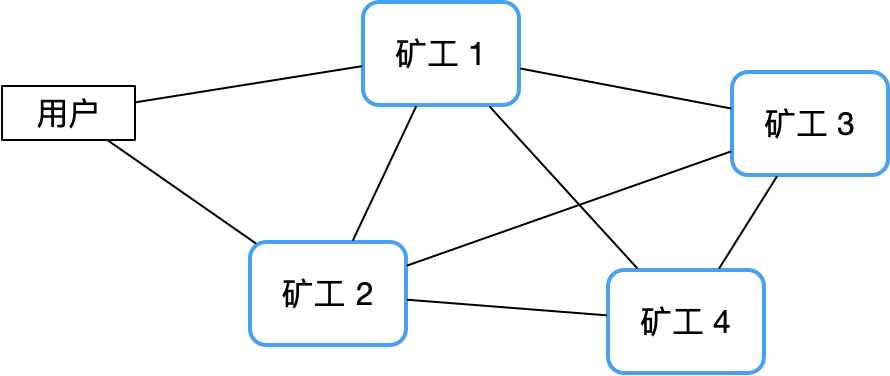
In contrast, a decentralized peer-to-peer architecture can avoid this risk well. Take the Bitcoin network as an example. Since there is no central node, its stability is much higher than that of a traditional master-slave cluster, and it is almost difficult to hang up.
Therefore, Sealos fully absorbed the lessons of Alibaba Cloud and Tencent Cloud when designing multi-availability zones, and adopted an ownerless architecture. All availability zones are autonomous. The main problem is how data such as user accounts are stored in multiple availability zones. Synchronization problem. It became a structure like this:
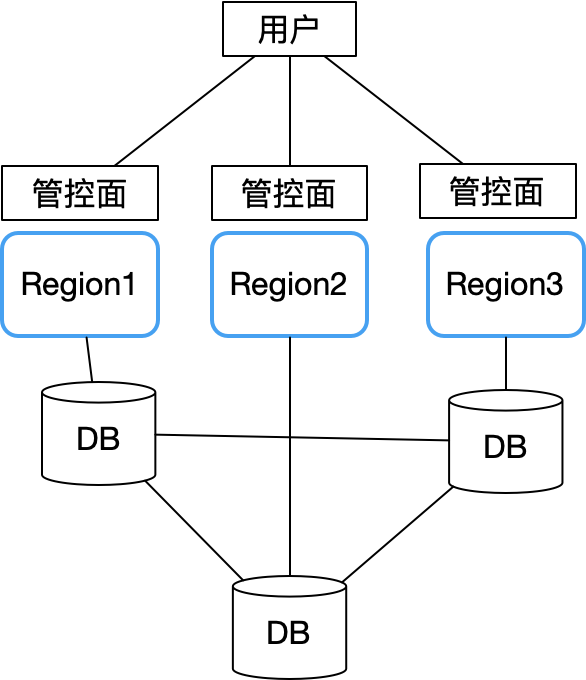
Each availability zone is completely autonomous and only synchronizes key shared data (such as user account information) through a cross-region distributed database (we use CockroachDB). Each availability zone is connected to the local node of the distributed database CockroachDB.
This way, a failure in a single Availability Zone will not affect business continuity in other regions. Only when an overall problem occurs in the distributed database cluster will the control plane of all availability zones become unavailable. Fortunately, CockroachDB itself has excellent performance in fault tolerance, disaster recovery, and response to network partitions, which greatly reduces the probability of this situation happening. In this way, the overall architecture is simple. Just focus on improving the stability of the database, monitoring and destructive testing.
Another benefit of this is that it provides convenience for grayscale release and differentiated operations. For example, new functions can be verified with small traffic in some areas first, and then fully launched after stabilization; different areas can also provide customized services based on the characteristics of customer groups without having to be completely consistent.
There is no absolutely stable system
Everyone complains a lot about the stability of the cloud, but all cloud vendors without exception have experienced failures. We have also experienced many failures. The most important thing here is how to converge. It is not only a technical issue, but also an organizational issue. Management issues are also a cost issue. I will share this with you based on specific examples we encountered during the entrepreneurial process.
Sealos lessons learned from failures
Laf major failure on March 17, 2023
This was the first major failure we encountered when starting a business. We were given a slap in the face just two days after the product was launched. The reason why we remember the time so clearly is that it happened to be the company's first anniversary celebration, and we didn't even have time to cut the cake. It lasted until about three o'clock in the night.
The final cause of the failure was very strange. We used lightweight servers for cheap . Network virtualization of containers on lightweight servers would lead to packet loss. In the end, we migrated the entire cluster to a normal VPC server, so many times the problem was stable. Sex and cost are inseparable.
Therefore, many people think that public cloud is expensive. In many cases, it does cost many times to solve the remaining 10% of problems.
Laf subsequently encountered a series of database-related stability issues, because it used a model in which multiple tenants share a MongoDB library . The final conclusion was that this road was not going to work, and it was difficult for us to solve the database isolation problem, so now All adopted the independent database method, and the problem was finally solved.
There is also the stability problem on the gateway. We initially chose an unreliable Ingress controller , which caused frequent problems. I won’t name the specific controller. Finally, we replaced it with Higress, which completely solved the problem. Currently, not only It takes up less resources and is more stable. I am also very grateful to the Alibaba Higress team for their personal support. The problems we exposed have also better helped Higress become more mature, a win-win situation.
In June 2023, our Sealos public cloud was officially launched. One of the biggest problems we encountered was being attacked. CC attacks with large traffic. Adding protection can solve it, but it also means a surge in costs, so the trade-off between the two is It’s very confusing. If you don’t prevent stability, it’s difficult to solve it. If you prevent it, you won’t be able to recover the cost by selling it. Later, after we replaced the gateway, we found that Envoy was really powerful and could actually resist the attack traffic. Before that, we used Nginx, which was one-stop. Moreover, the great thing about K8s is its strong self-healing ability. Even if the gateway is down, it can self-heal within 5 minutes. As long as it is not down at the same time, the business will not be affected.
Best Practices for Stability Convergence
Troubleshooting process
In order to continuously improve system stability, Sealos has established a strict fault management process internally:
Every time a failure occurs, it must be recorded in detail and followed up continuously. Many companies end the failure review process, but in fact review is not the purpose. The key is to formulate practical corrective measures and implement them to completely prevent similar failures from happening again. After the fault handling is completed, you still need to continue to observe it for a period of time until it is confirmed that the problem no longer occurs.
In terms of management goals, we initially defined the goal of stability and convergence in the 2024 Q1 OKR as follows:

Later, I discovered that this general slogan-style OKR was unreliable, and the convergence of stability needed to be more specific. The result of this KR was that we failed to achieve it, and it had almost no effect. In the process of convergence, you don’t need to fully blossom. Focus on a few core points every quarter and continue to iterate for a few quarters and the convergence will be very good.
So in Q2 we set more specific goals:

The setting of stability cannot just be limited to setting an indicator, nor can it be too general. It requires concrete and visible measures and specific measurement methods.
For example, if 99.9% is set, how to achieve it? So what is the current availability? What are the core issues at hand? How to measure? What needs to be done? Who will do it? The settings are not limited to the available time, but should be listed in detail, such as fault level, number of faults, fault duration, failure observation of major customers, etc.
It is necessary to separate special categories and list the priorities, such as: database stability, gateway stability, large customer service availability indicators, CPU/memory resource overload failure.
We should also focus on monitoring large customers, such as Auto Chess, FastGPT commercial customers, Chongchunxue Studio, etc. (monthly usage of more than 30 cores, pick 5 typical ones).
There are only so many stability issues. Once these large customers are well served, small customers can basically be covered. Don't pursue too many, focus on solving the current core stability issues, and then be sure to establish a complete tracking process.
Students who cause malfunctions may be punished, have their bonuses deducted, or even be expelled. As a start-up company, we usually do not use punitive measures , because the parties involved do not want to cause malfunctions, and everyone is really working hard to solve the problem. Those who can really fight are those who have been injured. We prefer positive incentives, such as If the quarterly failure frequency decreases, give some incentives appropriately .
Simple architectural design
System architecture is related to stability from the beginning of the design. The more complex the architecture, the easier it is to have problems, so many companies do not pay attention to this. I often participate in company architecture design and review, and usually find that the design is too complex for me to get through. , I feel something is wrong. Sealos multi-availability zone is a very good example. To turn a complex thing into a simple CRUD, then you only need to improve the database stability. The database table structure design is simple and many stability problems are solved. Killed in the cradle.
The same is true for our metering system. We originally designed it to have more than a dozen CRDs, but after struggling for more than half a year, the stability could not be stabilized. Finally, we redesigned and selected the system. It took almost two weeks to develop, and it was stably online in a month.
Therefore: simple design is crucial to stability!
Moderate monitoring, targeted
Surveillance is a double-edged sword, too much is not enough. Many Sealos failures were caused by monitoring. Prometheus occupied too many resources and the API Server was overwhelmed, which in turn caused new stability problems. After learning our lesson, we switched to a more lightweight monitoring solution like VictoriaMetrics, while strictly controlling the number of monitoring indicators. Tools like Uptime Kuma are very useful. They can test each other across regions and find problems in time.
The same is true for on call. There are thousands of alarms every day. What is on call? So here we basically start from 0 and slowly add things up. For example, we first do it from the perspective of "final stability of the big customer's business". For example, if a container failure launches this, if there is an on call, the phone will probably ring non-stop. . Then slowly add things like the host not ready. Theoretically, the host is not ready and should not affect the business. As the system gradually matures, it will eventually be possible to make the host not ready without the need for on call.
Don’t be afraid of embarrassment when reporting faults
Tencent Cloud's review report was very good. It truthfully explained the reasons for the failure, objectively analyzed what was not enough, and promised to actively rectify it. This kind of frank and responsible attitude actually makes it easier to win the trust of users. In contrast, keeping the issue secret for fear of public opinion fermentation is tantamount to drinking poison to quench thirst. Instead, it makes users feel that it is an opaque black box, and they do not know what will happen in the future . Customers who truly love your products and are willing to grow with you can tolerate non-principled mistakes. The key is to show sincerity and actions for real improvement.
Summarize
Sealos public cloud service has been launched for more than a year and has accumulated more than 100,000 registered users. With its excellent functions, experience and cost-effectiveness, many developers favor it, and some large customers have also begun to try to migrate their business to our Sealos cloud. Among them are some large-scale Internet products. For example, the game "Happy Auto Chess" has more than 4 million active users .
Looking to the future, we believe that through systematic fault management, we will continue to converge stability. Through simple and efficient architecture design, a steady and steady monitoring strategy, and supplemented by an open and honest communication attitude, Sealos, a cloud that was nurtured and developed by a small domestic open source company, will definitely It will become a very advanced cloud!
Linus took matters into his own hands to prevent kernel developers from replacing tabs with spaces. His father is one of the few leaders who can write code, his second son is the director of the open source technology department, and his youngest son is a core contributor to open source. Huawei: It took 1 year to convert 5,000 commonly used mobile applications Comprehensive migration to Hongmeng Java is the language most prone to third-party vulnerabilities. Wang Chenglu, the father of Hongmeng: open source Hongmeng is the only architectural innovation in the field of basic software in China. Ma Huateng and Zhou Hongyi shake hands to "remove grudges." Former Microsoft developer: Windows 11 performance is "ridiculously bad " " Although what Laoxiangji is open source is not the code, the reasons behind it are very heartwarming. Meta Llama 3 is officially released. Google announces a large-scale restructuring