

Article Source | ByteDance Intelligent Creation Team
We are excited to share with you our latest Vincentian graph model, SDXL-Lightning, which achieves unprecedented speed and quality and is now available to the community.
Model: https://huggingface.co/ByteDance/SDXL-Lightning
Paper: https://arxiv.org/abs/2402.13929

Lightning-fast image generation
Generative AI is gaining global attention for its ability to create stunning images and even videos based on text prompts. However, current state-of-the-art generative models rely on diffusion, an iterative process that gradually transforms noise into image samples. This process requires huge computing resources and is slow. In the process of generating high-quality image samples, the processing time of a single image is about 5 seconds, which usually requires multiple calls (20 to 40 times) to a huge neural network. . This speed limits application scenarios that require fast, real-time generation. How to speed up the generation while improving the quality is a hot area of current research and the core goal of our work.
SDXL-Lightning breaks through this barrier through an innovative technology - Progressive Adversarial Distillation - to achieve unprecedented generation speeds. The model is able to generate extremely high quality and resolution images in just 2 or 4 steps, reducing computational cost and time by a factor of ten. Our method can even generate images in 1 step for timeout-sensitive applications, although some quality may be sacrificed slightly.
除了速度优势,SDXL-Lightning 在图像质量上也有显著表现,并在评估中超越了以往的加速技术。在实现更高分辨率和更佳细节的同时保持良好的多样性和图文匹配度。
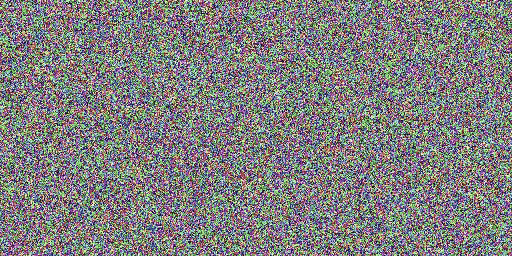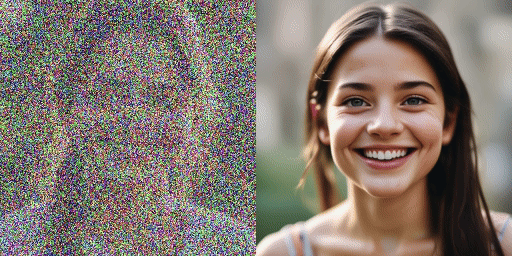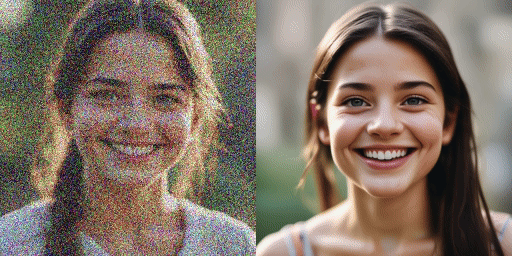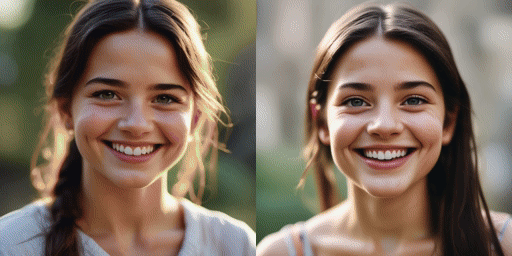 speed comparison
speed comparison
Original model (20 steps), our model (2 steps)
Model effect
Our model can generate images in 1-step, 2-step, 4-step and 8-step. The more inference steps there are, the better the image quality.
Here are the results of our 4-step process:
Here are the results of our 2-step build:
与以前的方法(Turbo 和 LCM)相比,我们的方法生成的图像在细节上有显著改进,并且更忠实于原始生成模型的风格和布局。

Give back to the community, open model
The wave of open source has become a key force in promoting the rapid development of artificial intelligence, and ByteDance is proud to be part of this wave. Our model is based on SDXL, currently the most popular open model for text generation images, which already has a thriving ecosystem. Now, we have decided to open SDXL-Lightning to developers, researchers, and creative practitioners around the world so that they can access and apply this model to further promote innovation and collaboration throughout the industry.
When designing SDXL-Lightning, we considered compatibility with the open model community. Many artists and developers in the community have created a variety of stylized image generation models, such as cartoon and anime styles. In order to support these models, we provide SDXL-Lightning as a speed-up plug-in, which can be seamlessly integrated into these various styles of SDXL models to speed up image generation for various models.
 Our model can also be combined with the currently very popular control plug-in ControlNet to achieve extremely fast and controllable image generation.
Our model can also be combined with the currently very popular control plug-in ControlNet to achieve extremely fast and controllable image generation.
 Our model also supports ComfyUI, currently the most popular generation software in the open source community, and the model can be loaded directly for use:
Our model also supports ComfyUI, currently the most popular generation software in the open source community, and the model can be loaded directly for use: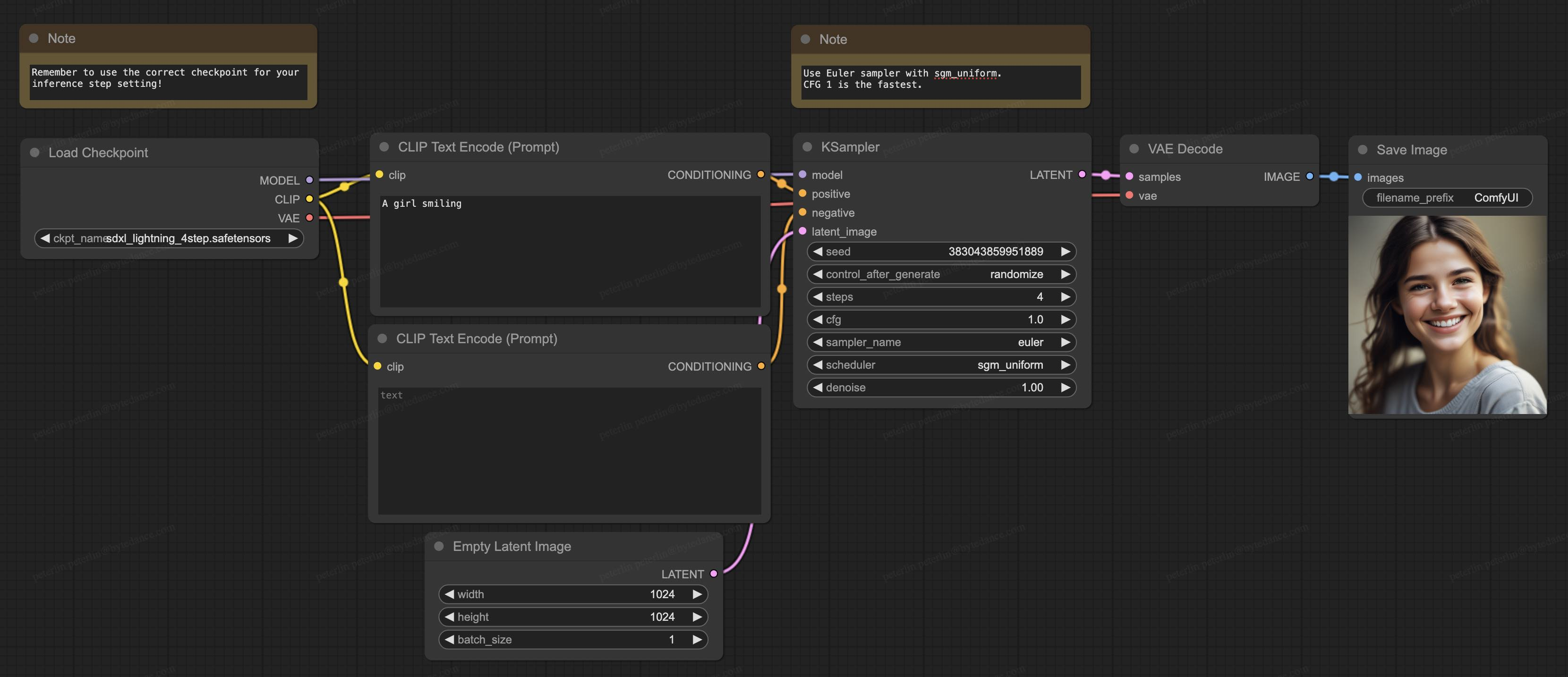
About technical details
Theoretically, image generation is a step-by-step transformation process from noise to clear images. In this process, the neural network learns the gradients at various positions in the transformation flow.
The specific steps to generate an image are as follows: First, we randomly sample a noise sample at the starting point of the stream, and then use a neural network to calculate the gradient. Based on the gradient at the current position, we make small adjustments to the sample and then repeat the process. With each iteration, the samples get closer to the final image distribution until a clear image is obtained.
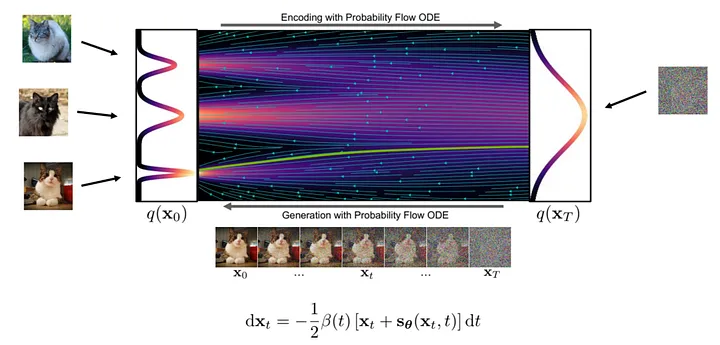 Figure: Generation process ( picture from : https://arxiv.org/abs/2011.13456 )
Figure: Generation process ( picture from : https://arxiv.org/abs/2011.13456 )
Since the generation flow is complex and non-linear, the generation process must only take a small step at a time to reduce the accumulation of gradient errors, so frequent calculations of the neural network are required, which is why the calculation amount is large.
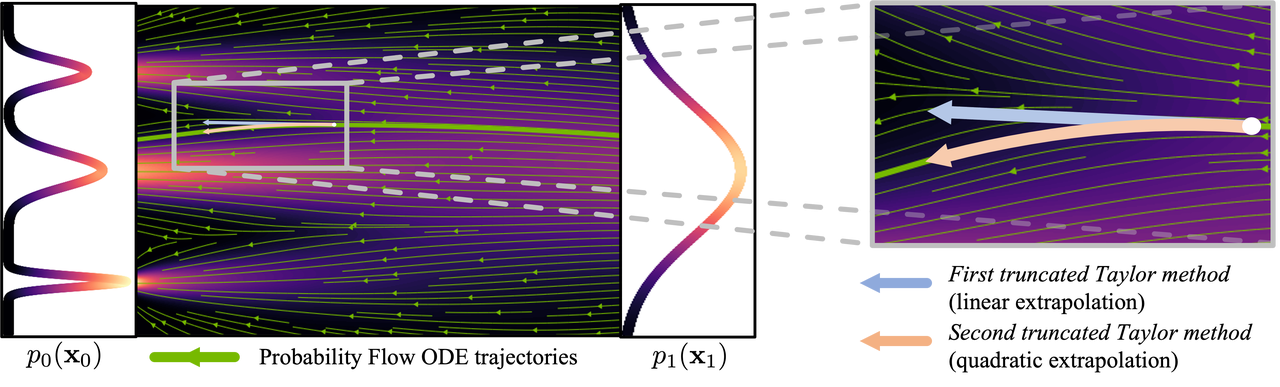 Figure: Curve process ( picture from : https://arxiv.org/abs/2210.05475 )
Figure: Curve process ( picture from : https://arxiv.org/abs/2210.05475 )
In order to reduce the number of steps required to generate images, much research has been devoted to finding solutions. Some studies propose sampling methods that reduce errors, while others attempt to make the generated flow more linear. Despite advances in these methods, they still require more than 10 inference steps to generate images.
Another method is model distillation, which is able to generate high-quality images in less than 10 inference steps. Instead of calculating the gradient at the current flow position, model distillation changes the target of model prediction to directly predict the next farther flow position. Specifically, we train a student network to directly predict the result of the teacher network after completing multi-step reasoning. Such a strategy can significantly reduce the number of inference steps required. By applying this process repeatedly, we can further reduce the number of inference steps. This approach has been called progressive distillation by previous research.
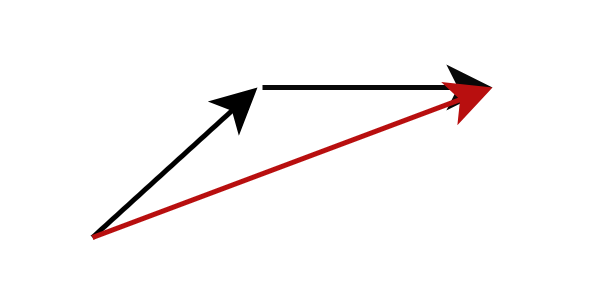 Figure: Progressive distillation , the student network predicts the result of the teacher network after multiple steps
Figure: Progressive distillation , the student network predicts the result of the teacher network after multiple steps
In practice, student networks often have difficulty predicting future flow positions accurately. The error amplifies as each step accumulates, causing the images produced by the model to start to become blurry with less than 8 steps of inference.
To solve this problem, our strategy is not to force the student network to exactly match the predictions of the teacher network, but to make the student network consistent with the teacher network in terms of probability distribution. In other words, the student network is trained to predict a probabilistically possible location, and even if this location is not completely accurate, we do not penalize it. This goal is achieved through adversarial training, which introduces an additional discriminative network to help achieve distribution matching of the student and teacher network outputs.
This is a brief overview of our research methods. In our technical paper ( https://arxiv.org/abs/2402.13929 ), we provide a more in-depth theoretical analysis, training strategy, and specific formulation details of the model.
Beyond SDXL-Lightning
Although this study mainly explores how to use SDXL-Lightning technology for image generation, the application potential of our proposed progressive adversarial distillation method is not limited to static images. This innovative technology can also be used to generate video, audio and other multi-modal content quickly and with high quality. We sincerely invite you to experience SDXL-Lightning on the HuggingFace platform and look forward to your valuable comments and feedback.
Model: https://huggingface.co/ByteDance/SDXL-Lightning
Paper: https://arxiv.org/abs/2402.13929
Fellow chicken "open sourced" deepin-IDE and finally achieved bootstrapping! Good guy, Tencent has really turned Switch into a "thinking learning machine" Tencent Cloud's April 8 failure review and situation explanation RustDesk remote desktop startup reconstruction Web client WeChat's open source terminal database based on SQLite WCDB ushered in a major upgrade TIOBE April list: PHP fell to an all-time low, Fabrice Bellard, the father of FFmpeg, released the audio compression tool TSAC , Google released a large code model, CodeGemma , is it going to kill you? It’s so good that it’s open source - open source picture & poster editor tool