Large language models advance the state-of-the-art in natural language processing. However, they are primarily designed for English or a limited set of languages, which creates a large gap in their effectiveness for low-resource languages. In order to bridge this gap, researchers from the University of Munich, the University of Helsinki and other researchers jointly open sourced MaLA-500, which aims to cover a wide range of 534 languages.
MaLA-500 is built based on LLaMA 2 7B, and then uses the multi-language data set Glot500-c for language expansion training. The researchers' experimental results on SIB-200 show that MaLA-500 has achieved state-of-the-art context learning results.
Glot500-c contains 534 languages, covering 47 different ethnic languages, with a data volume of up to 2 trillion tokens. The researchers said that the reason for choosing the Glot500-c data set is that it can greatly expand the language coverage of existing language models and contains an extremely rich language family, which is of great help to the model in learning the inherent grammar and semantic rules of the language.
In addition, although the proportion of some high-resource languages is relatively low, the overall data volume of Glot500-c is sufficient for training large-scale language models. In the subsequent preprocessing, weighted random sampling was performed on the corpus data set to increase the proportion of low-resource languages in the training data and allow the model to focus more on specific languages.
Based on LLaMA 2-7B, MaLA-500 has made two major technological innovations:
- To enhance the vocabulary, the researchers trained a multilingual word segmenter through the Glot500-c data set, expanding the original English vocabulary of LLaMA 2 to 2.6 million, greatly enhancing the model's ability to adapt to non-English and low-resource languages.

- Model enhancement uses LoRA technology to perform low-rank adaptation based on LLaMA 2. Only training the adaptation matrix and freezing the basic model weights can effectively realize the model's continuous learning ability in new languages while retaining the model's original knowledge.
Training process
In terms of training, the researchers used 24 N-card A100 GPUs for training, and used three mainstream deep learning frameworks including Transformers, PEFT and DeepSpeed.
Among them, DeepSpeed provides support for distributed training and can achieve model parallelism; PEFT implements efficient model fine-tuning; Transformers provides the implementation of model functions, such as text generation, prompt word understanding, etc.
In order to improve the efficiency of training, MaLA-500 also uses various memory and computing optimization algorithms, such as the ZeRO redundant optimizer, which can maximize the use of GPU computing resources; and the bfloat16 number format for mixed precision training to accelerate the training process.
In addition, the researchers also conducted a large number of optimizations on the model parameters, using conventional SGD training with a learning rate of 2e-4, and using an L2 weight attenuation of 0.01 to prevent the model from being too large, overfitting, unstable content output, etc. Condition.
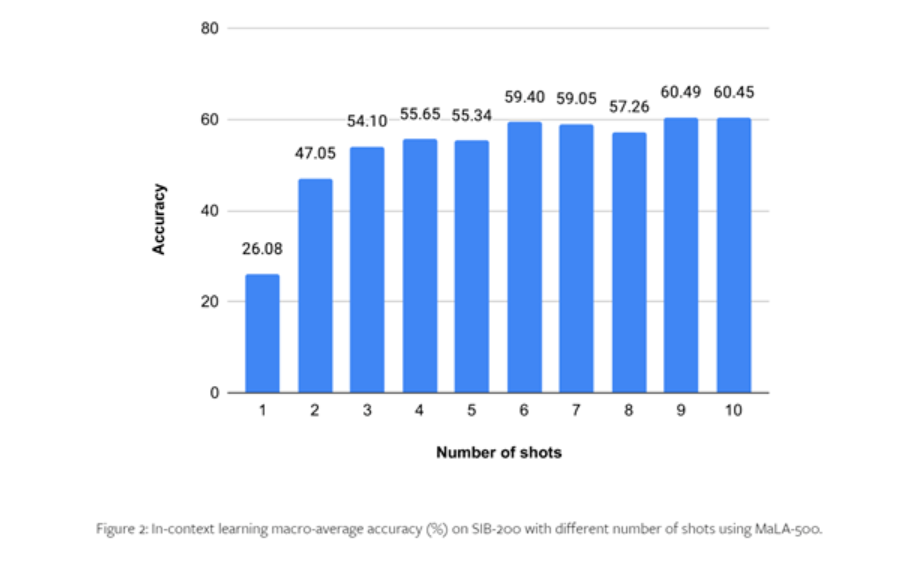
In order to test the performance of MaLA-500, the researchers conducted comprehensive experiments on data sets such as SIB-200.
The results show that compared with the original LLaMA 2 model, the accuracy of MaLA-500 on evaluation tasks such as topic classification is increased by 12.16%, which shows that MaLA-500's multi-language is superior to many existing open source large language models.
More details can be found in the full paper .