
01
background
02
Venus log platform introduction
Venus is a log service platform developed by iQiyi. It provides log collection, processing, storage, analysis and other functions. It is mainly used for log troubleshooting, big data analysis, monitoring and alarming within the company. The overall architecture is shown in Figure 1. shown.
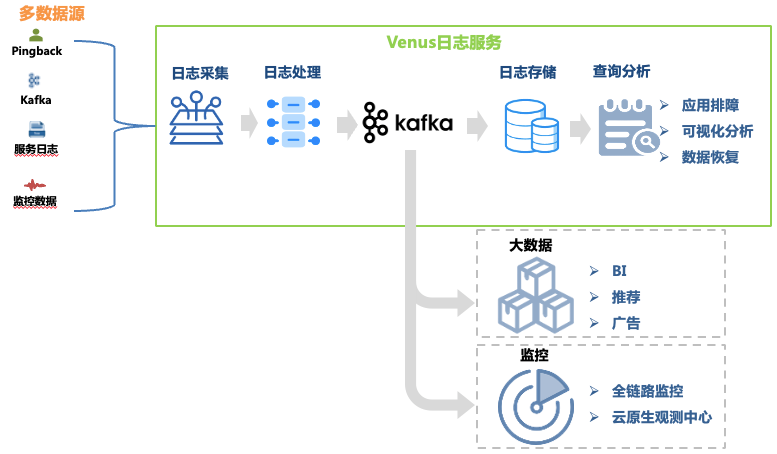 Figure 1 Venus link
Figure 1 Venus link
This article focuses on the architectural evolution of the log troubleshooting link. Its data links include:
Log collection : By deploying collection agents on machines and container hosts, logs from front-end, back-end, monitoring and other sources of each business line are collected, and the business is also supported to self-deliver logs that meet the format requirements. More than 30,000 Agents have been deployed, supporting 10 data sources such as Kafka, MySQL, K8s, and gateways.
Log processing : After log collection, it undergoes standardized processing such as regular extraction and built-in parser extraction, and is uniformly written to Kafka in JSON format, and then written to the storage system by the dump program.
Log storage : Venus stores nearly 10,000 business log streams, with a writing peak of more than 10 million QPS, and daily new logs exceeding 500TB. As the storage scale changes, the selection of storage systems has gone through many changes from ElasticSearch to data lake.
Query analysis : Venus provides visual query analysis, contextual query, log disk, pattern recognition, log download and other functions.
In order to meet the storage and rapid analysis of massive log data, the Venus log platform has undergone three major architecture upgrades, gradually evolving from the classic ELK architecture to a self-developed system based on data lakes. This article will introduce the problems encountered during the transformation of the Venus architecture. and solutions.
03
Venus 1.0: Based on ELK architecture
Venus 1.0 started in 2015 and was built based on the then popular ElasticSearch+Kibana, as shown in Figure 2. ElasticSearch is responsible for the storage and analysis functions of logs, and Kibana provides visual query and analysis capabilities. You only need to consume Kafka and write logs to ElasticSearch to provide log services.
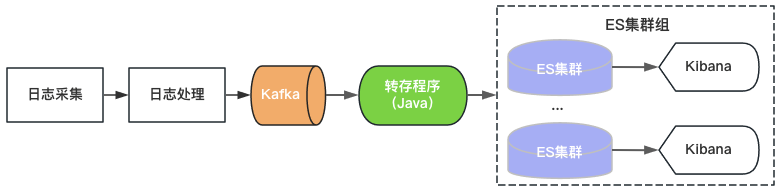 Figure 2 Venus 1.0 architecture
Figure 2 Venus 1.0 architecture
Since there are upper limits on the throughput, storage capacity, and number of index shards of a single ElasticSearch cluster, Venus continues to add new ElasticSearch clusters to cope with the growing log demand. In order to control costs, the load of each ElasticSearch is at a high level, and the index is configured with 0 copies. Problems such as sudden traffic write, large data query, or machine failure leading to cluster unavailability are often encountered. At the same time, due to the large number of indexes on the cluster, the large amount of data, and the long recovery time, the logs are unavailable for a long time, and the Venus usage experience becomes increasingly worse.
04
Venus 2.0: Based on ElasticSearch + Hive
Cluster classification: ElasticSearch clusters are divided into two categories: high-quality and low-quality. Key businesses use high-quality clusters, the load of the cluster is controlled at a low level, and the index is enabled with a 1-copy configuration to tolerate single node failure; non-key businesses use a low-quality cluster, the load is controlled at a high level, and the index still uses a 0-copy configuration.
Storage classification: Double-write ElasticSearch and Hive for long-storage logs. ElasticSearch saves the logs of the last 7 days, and Hive saves logs for a longer period of time, which reduces the storage pressure of ElasticSearch and also reduces the risk of ElasticSearch being hung up by large data queries. However, since Hive cannot perform interactive queries, the logs in Hive need to be queried through an offline computing platform, resulting in a poor query experience.
Unified query portal: Provides a unified visual query and analysis portal similar to Kibana, shielding the underlying ElasticSearch cluster. When a cluster fails, newly written logs are scheduled to other clusters without affecting the query and analysis of new logs. Transparently schedule traffic between clusters when cluster load is imbalanced.
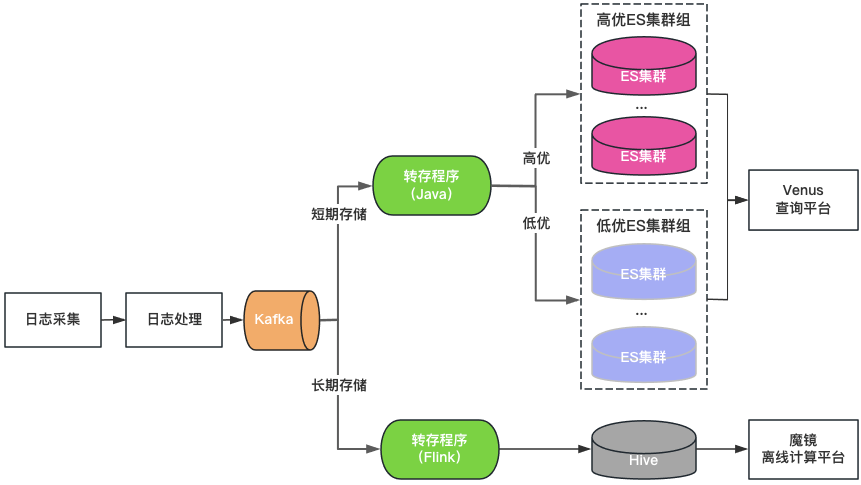
Figure 3 Venus 2.0 architecture
Venus 2.0 is a compromise solution to protect key businesses and reduce the risk and impact of failures. It still has the problems of high cost and poor stability:
ElasticSearch has short storage time: Due to the large amount of logs, ElasticSearch can only store 7 days, which cannot meet daily business needs.
There are many entrances and data fragmentation: more than 20 ElasticSearch clusters + 1 Hive cluster, there are many query entrances, which is very inconvenient for query and management.
High cost: Although ElasticSearch only stores logs for 7 days, it still consumes more than 500 machines.
Integrated reading and writing: The ElasticSearch server is responsible for reading and writing at the same time, affecting each other.
Many faults: ElasticSearch faults account for 80% of Venus’ total faults. After faults, reading and writing are blocked, logs are easily lost, and processing is difficult.
05
Venus 3.0: New architecture based on data lake
Thinking about introducing data lake
After an in-depth analysis of Venus’s log scenario, we summarize its characteristics as follows:
Large amount of data : nearly 10,000 business log streams with a peak writing capacity of 10 million QPS and PB-level data storage.
Write more and check less : Business usually only queries logs when there is a need for troubleshooting. Most logs have no query requirements within a day, and the overall query QPS is also extremely low.
Interactive query : Logs are mainly used for troubleshooting urgent scenarios that require multiple consecutive queries, and require a second-level interactive query experience.
Regarding the problems encountered when using ElasticSearch to store and analyze logs, we believe that it does not quite match the Venus log scenario for the following reasons:
A single cluster has limited writing QPS and storage scale, so multiple clusters need to share traffic. Complex scheduling strategy issues such as cluster size, write traffic, storage space, and number of indexes need to be considered, which increases the difficulty of management. Since business log traffic varies widely and is unpredictable, in order to solve the impact of sudden traffic on cluster stability, it is often necessary to reserve more idle resources, resulting in a huge waste of cluster resources.
Full-text indexing during writing consumes a lot of CPU, leading to data expansion and a significant increase in computing and storage costs. In many scenarios, storing analysis logs requires more resources than background service resources. For scenarios such as logs where there are many writes and few queries, precomputing the full-text index is more luxurious.
Storage data and calculation are on the same machine. Large data volume queries or aggregate analysis can easily affect writing, causing writing delays or even cluster failures.
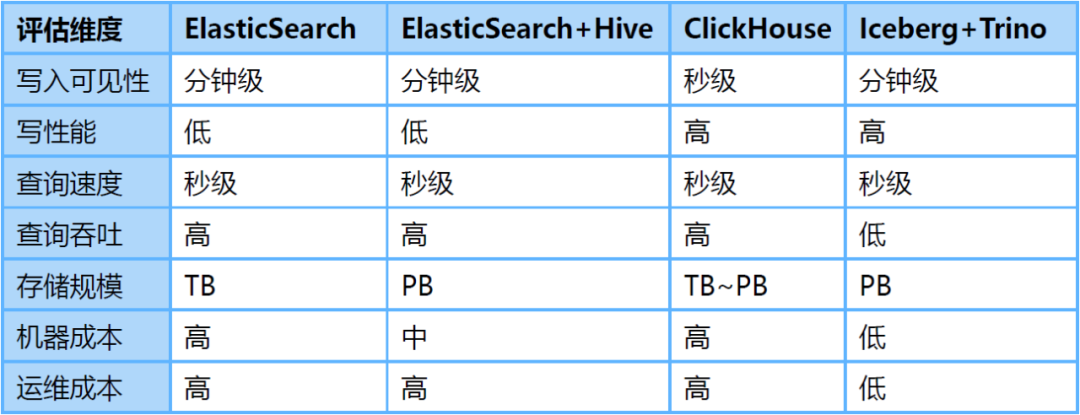
为了解决上述问题,我们调研了ClickHouse、Iceberg数据湖等替代方案。其中,Iceberg是爱奇艺内部选择的数据湖技术,是一种存储在HDFS或对象存储之上的表结构,支持分钟级的写入可见性及海量数据的存储。Iceberg对接Trino查询引擎,可以支持秒级的交互式查询,满足日志的查询分析需求。
针对海量日志场景,我们对ElasticSearch、ElasticSearch+Hive、ClickHouse、Iceberg+Trino等方案做了对比评估:
-
存储空间大:Iceberg底层数据存储在大数据统一的存储底座HDFS上,意味着可以使用大数据的超大存储空间,不需要再通过多个集群分担存储,降低了存储的维护代价。 -
存储成本低:日志写入到Iceberg不做全文索引等预处理,同时开启压缩。HDFS开启三副本相比于ElasticSearch的三副本存储空间降低近90%,相比ElasticSearch的单副本存储空间仍然降低30%。同时,日志存储可以与大数据业务共用HDFS空间,进一步降低存储成本。 -
计算成本低:对于日志这种写多查少的场景,相比于ElasticSearch存储前做全文索引等预处理,按查询触发计算更能有效利用算力。 -
存算隔离:Iceberg存储数据,Trino分析数据的存算分离架构天然的解决了查询分析对写入的影响。
基于数据湖架构的建设
通过上述评估,我们基于Iceberg和Trino构建了Venus 3.0。采集到Kafka中的日志由转存程序写入Iceberg数据湖。Venus查询平台通过Trino引擎查询分析数据湖中的日志。架构如图4所示。
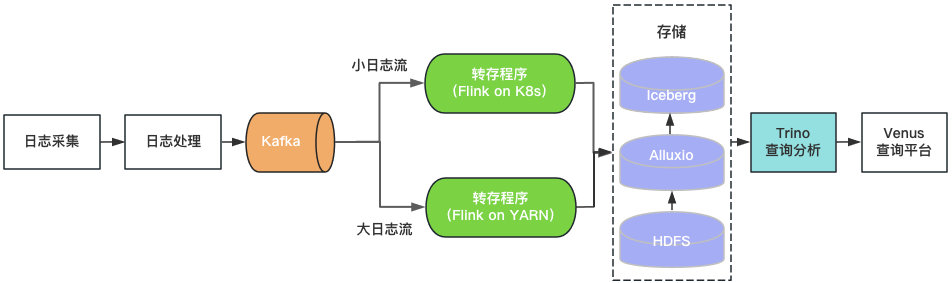 图4 Venus 3.0架构
图4 Venus 3.0架构
-
日志存储
-
查询分析
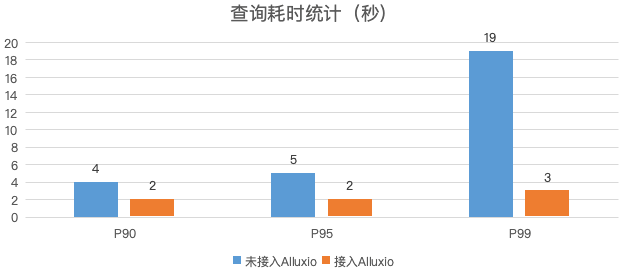
图5 日志查询性能对比
-
转存程序
-
落地效果
-
存储空间 :日志的物理存储空间降低30%,考虑到ElasticSearch集群的磁盘存储空间利用率较低,实际存储空间降低50%以上。 -
计算资源 :Trino使用的CPU核数相比于ElasticSearch减少80%,转存程序资源消耗降低70%。 -
稳定性提升:迁移到数据湖后,故障数降低了85%,大幅节省运维人力。
06
总结与规划
-
Iceberg+Trino的数据湖架构支持的查询并发较低,我们将尝试使用Bloomfilter、Zorder等轻量级索引提升查询性能,提高查询并发,满足更多的实时分析的需求。 -
目前Venus存储了近万个业务日志流,日新增日志超过500TB。计划引入基于数据热度的日志生命周期管理机制,及时下线不再使用的日志,进一步节省资源。 -
如图1所示,Venus同时也承载了大数据分析链路的Pingback用户数据的采集与处理,该链路与日志数据链路比较类似,参考日志入湖经验,我们对Pingback数据的处理环节进行基于数据湖的流批一体化改造。目前已完成一期开发与上线,应用于直播监控、QOS、DWD湖仓等场景,后续将继续推广至更多的湖仓场景。详细技术细节将在后续的数据湖系列文章中介绍。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。