We know that JavaCC is a compiler development tool mainly used to parse input text and generate a syntax tree corresponding to its syntax structure. The syntax tree generated by JavaCC is a lower-level abstraction that requires developers to define and implement its processing and operations. JJTree is an extension of JavaCC, providing a higher level of abstraction. Compared with JavaCC, the syntax tree nodes generated by JJTree contain attributes and methods, which make it easier to build and process syntax trees, especially for complex syntax structures and syntax tree node operation requirements.
Let’s look at the following example first:
PARSER_BEGIN(Eg1)
package com.github.gambo.javacc.jjtree.eg1;
/** An Arithmetic Grammar. */
public class Eg1 {
/** Main entry point. */
public static void main(String args[]) {
System.out.println("Reading from standard input...");
Eg1 t = new Eg1(System.in);
try {
SimpleNode n = t.Start();
n.dump("");
System.out.println("Thank you.");
} catch (Exception e) {
System.out.println("Oops.");
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}
PARSER_END(Eg1)
SKIP :
{
" "
| "\t"
| "\n"
| "\r"
| <"//" (~["\n","\r"])* ("\n"|"\r"|"\r\n")>
| <"/*" (~["*"])* "*" (~["/"] (~["*"])* "*")* "/">
}
TOKEN : /* LITERALS */
{
< INTEGER_LITERAL:
<DECIMAL_LITERAL> (["l","L"])?
| <HEX_LITERAL> (["l","L"])?
| <OCTAL_LITERAL> (["l","L"])?
>
|
< #DECIMAL_LITERAL: ["1"-"9"] (["0"-"9"])* >
|
< #HEX_LITERAL: "0" ["x","X"] (["0"-"9","a"-"f","A"-"F"])+ >
|
< #OCTAL_LITERAL: "0" (["0"-"7"])* >
}
TOKEN : /* IDENTIFIERS */
{
< IDENTIFIER: <LETTER> (<LETTER>|<DIGIT>)* >
|
< #LETTER: ["_","a"-"z","A"-"Z"] >
|
< #DIGIT: ["0"-"9"] >
}
/** Main production. */
SimpleNode Start() : {}
{
Expression() ";"
{ return jjtThis; }
}
/** An Expression. */
void Expression() : {}
{
AdditiveExpression()
}
/** An Additive Expression. */
void AdditiveExpression() : {}
{
MultiplicativeExpression() ( ( "+" | "-" ) MultiplicativeExpression() )*
}
/** A Multiplicative Expression. */
void MultiplicativeExpression() : {}
{
UnaryExpression() ( ( "*" | "/" | "%" ) UnaryExpression() )*
}
/** A Unary Expression. */
void UnaryExpression() : {}
{
"(" Expression() ")" | Identifier() | Integer()
}
/** An Identifier. */
void Identifier() : {}
{
<IDENTIFIER>
}
/** An Integer. */
void Integer() : {}
{
<INTEGER_LITERAL>
}This is a grammar file for parsing arithmetic expressions. Compared with the previous javacc grammar file, it adds a hierarchical structure for printing the syntax tree through the dump method of SimpleNode.
We can take a look at the ant build configuration: |
<target name="eg1" description="Builds example 'eg1'">
<delete dir="${build.home}/jjtree"/>
<mkdir dir="${build.home}/jjtree"/>
<copy file="eg1.jjt" todir="${build.home}/jjtree"/>
<jjtree target="eg1.jjt" outputdirectory="${build.home}/jjtree" javacchome="${javacc.home}"/>
<javacc target="${build.home}/jjtree/eg1.jj" outputdirectory="${build.home}/jjtree" javacchome="${javacc.home}"/>
<javac deprecation="false" srcdir="${build.home}/jjtree" destdir="${build.class.home}" includeantruntime='false'/>
<echo message="*******"/>
<echo message="******* Now cd into the eg1 directory and run 'java Eg1' ******"/>
<echo message="*******"/>
</target>You can see that the xxx.jj file is first generated through the jjtree command, and then the java code is generated through the javacc command. The final generated file is as follows:
Run the main method of Eg1 and enter (a + b) * (c + 1); note that you must enter a semicolon. The running result is:
Reading from standard input...
(a + b) * (c + 1);
Start
Expression
AdditiveExpression
MultiplicativeExpression
UnaryExpression
Expression
AdditiveExpression
MultiplicativeExpression
UnaryExpression
Identifier
MultiplicativeExpression
UnaryExpression
Identifier
UnaryExpression
Expression
AdditiveExpression
MultiplicativeExpression
UnaryExpression
Identifier
MultiplicativeExpression
UnaryExpression
Integer
Thank you.You can see that it generates a hierarchical structure according to the order in which the productions are called.
Node
By default, JJTree generates code to construct a parse tree node for each nonterminal symbol. We can also modify this behavior so that certain nonterminal symbols do not generate nodes, or are part of the nodes of production expansion.
JJTree defines a Java interface `Node` that all parse tree nodes must implement. This interface provides some methods: add a parent node to the current node, and add child nodes and retrieve them. There is another interface named Node in the code we generated, and its structure is as follows:
public interface Node {
// 此方法在节点成为当前节点后调用。它表明当前节点现在可以添加子节点。
public void jjtOpen();
// 子节点添加完毕后,将调用此方法。
public void jjtClose();
//这对方法分别用于设置节点的父节点和获取节点的父节点
public void jjtSetParent(Node n);
public Node jjtGetParent();
//方法将指定的节点添加到当前节点的子节点列表中
public void jjtAddChild(Node n, int i);
//获取指定索引的子节点
public Node jjtGetChild(int i);
//获取子节点的数量
public int jjtGetNumChildren();
public int getId();
}We can implement a SimpleNode.class that implements the Node interface, and we can implement it ourselves. If it does not exist, it will be automatically generated by JJTree. We can use this class as a template or parent class for node implementation, or we can modify it. SimpleNode also provides a basic mechanism for recursively dumping nodes and their children. We can observe the dump method of the generated SimpleNode.
public void dump(String prefix) {
System.out.println(toString(prefix));
if (children != null) {
for (int i = 0; i < children.length; ++i) {
SimpleNode n = (SimpleNode)children[i];
if (n != null) {
n.dump(prefix + " ");
}
}
}
}This is why we print the hierarchical structure after executing the dump method in the main function.
Define node names and conditions
Let's observe the above running results. A simple arithmetic expression generates more than 20 nodes. In fact, many intermediate transition nodes are unnecessary, such as UnaryExpression, express, etc. We hope to only generate those directly related to arithmetic expressions. node. Moreover, the node names are all named after production names. It is impossible to intuitively tell which is the plus node and which is the multiplication node. Generally speaking, the readability is not high.
Let’s improve the above example:
options {
MULTI=true;
KEEP_LINE_COLUMN = false;
}
PARSER_BEGIN(Eg2)
package com.github.gambo.javacc.jjtree.eg2;
/** An Arithmetic Grammar. */
public class Eg2 {
/** Main entry point. */
public static void main(String args[]) {
System.out.println("Reading from standard input...");
Eg2 t = new Eg2(System.in);
try {
ASTStart n = t.Start();
n.dump("");
System.out.println("Thank you.");
} catch (Exception e) {
System.out.println("Oops.");
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}
PARSER_END(Eg2)
SKIP :
{
" "
| "\t"
| "\n"
| "\r"
| <"//" (~["\n","\r"])* ("\n"|"\r"|"\r\n")>
| <"/*" (~["*"])* "*" (~["/"] (~["*"])* "*")* "/">
}
TOKEN : /* LITERALS */
{
< INTEGER_LITERAL:
<DECIMAL_LITERAL> (["l","L"])?
| <HEX_LITERAL> (["l","L"])?
| <OCTAL_LITERAL> (["l","L"])?
>
|
< #DECIMAL_LITERAL: ["1"-"9"] (["0"-"9"])* >
|
< #HEX_LITERAL: "0" ["x","X"] (["0"-"9","a"-"f","A"-"F"])+ >
|
< #OCTAL_LITERAL: "0" (["0"-"7"])* >
}
TOKEN : /* IDENTIFIERS */
{
< IDENTIFIER: <LETTER> (<LETTER>|<DIGIT>)* >
|
< #LETTER: ["_","a"-"z","A"-"Z"] >
|
< #DIGIT: ["0"-"9"] >
}
/** Main production. */
ASTStart Start() : {}
{
Expression() ";"
{ return jjtThis; }
}
/** An Expression. */
void Expression() #void : {}
{
AdditiveExpression()
}
/** An Additive Expression. */
void AdditiveExpression() #void : {}
{
(
MultiplicativeExpression() ( ( "+" | "-" ) MultiplicativeExpression() )*
) #Add(>1)
}
/** A Multiplicative Expression. */
void MultiplicativeExpression() #void : {}
{
(
UnaryExpression() ( ( "*" | "/" | "%" ) UnaryExpression() )*
) #Mult(>1)
}
/** A Unary Expression. */
void UnaryExpression() #void : {}
{
"(" Expression() ")" | MyID() | Integer()
}
/** An Identifier. */
void MyID() :
{
Token t;
}
{
t=<IDENTIFIER>
{
jjtThis.setName(t.image);
}
}
/** An Integer. */
void Integer() : {}
{
<INTEGER_LITERAL>
}
Enter the same expression (a + b) * (c + 1); the results are as follows:
Reading from standard input...
(a + b) * (c + 1);
Start
Mult
Add
Identifier: a
Identifier: b
Add
Identifier: c
Integer
Thank you.Compared with the previous jjtree grammar file, the changes here are not big. Let’s take a look at them one by one:
void Expression() #void : {}
{
AdditiveExpression()
}There is one more #void here than before. If you want to prevent the current production from generating a node, you can use this syntax.
void AdditiveExpression() #void : {}
{
(
MultiplicativeExpression() ( ( "+" | "-" ) MultiplicativeExpression() )*
) #Add(>1)
}This production represents the addition and subtraction of several multiplication expressions. #Add here acts as a postfix operator, and its scope is the immediately preceding expansion unit (here it represents the expression in the preceding parentheses).
#Add(>1) is the way to write a conditional node. If and only if the condition evaluates to 'true', the current node and its child nodes will be constructed. If the calculation result is 'false', the current node and its child nodes will not be constructed. child node. If there is no condition after #Add, it means #Add(true), and #Add(>1) is the abbreviation of #Add(jjtree.arity() > 1), and jjtree.arity() represents and obtains the current node range. The number of nodes pushed into the node stack can be simply understood as whether the Add node has child nodes generated. We will add the class structure of jjtree later.
void MyID() :
{
Token t;
}
{
t=<IDENTIFIER>
{
jjtThis.setName(t.image);
}
}Here is an application of custom nodes, which is used to print out the parsed token characters as node names. jjtThis.setName(t.image); represents setting the name of the current node. Here you can see how to expand SimpleNode.
package com.github.gambo.javacc.jjtree;
/**
* An ID.
*/
public class ASTMyID extends SimpleNode {
private String name;
/**
* Constructor.
* @param id the id
*/
public ASTMyID(int id) {
super(id);
}
/**
* Set the name.
* @param n the name
*/
public void setName(String n) {
name = n;
}
/**
* {@inheritDoc}
* @see org.javacc.examples.jjtree.eg2.SimpleNode#toString()
*/
public String toString() {
return "Identifier: " + name;
}
}Comparing the printing of the node tree above, the usage is clear at a glance! Note that the class name of the custom node is prefixed with AST, and our reference name to this node in the grammar file is ASTxxx, with xxx as the node reference.
In the above example, we added #void after several productions to avoid the generation of nodes. In fact, such an action can be configured as the default behavior. We can add configuration in the options area of the file header.
NODE_DEFAULT_VOID=true
In this way, all productions will not generate nodes. If you need some productions to generate nodes, add #xxx at the end. The specific code is as follows:
options {
MULTI=true;
NODE_DEFAULT_VOID=true;
}
PARSER_BEGIN(Eg)
package com.github.gambo.javacc.jjtree;
/** An Arithmetic Grammar. */
public class Eg {
/** Main entry point. */
public static void main(String args[]) {
System.out.println("Reading from standard input...");
Eg t = new Eg(System.in);
try {
ASTStart n = t.Start();
n.dump("");
System.out.println("Thank you.");
} catch (Exception e) {
System.out.println("Oops.");
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}
PARSER_END(Eg)
SKIP :
{
" "
| "\t"
| "\n"
| "\r"
| <"//" (~["\n","\r"])* ("\n"|"\r"|"\r\n")>
| <"/*" (~["*"])* "*" (~["/"] (~["*"])* "*")* "/">
}
TOKEN : /* LITERALS */
{
< INTEGER_LITERAL:
<DECIMAL_LITERAL> (["l","L"])?
| <HEX_LITERAL> (["l","L"])?
| <OCTAL_LITERAL> (["l","L"])?
>
|
< #DECIMAL_LITERAL: ["1"-"9"] (["0"-"9"])* >
|
< #HEX_LITERAL: "0" ["x","X"] (["0"-"9","a"-"f","A"-"F"])+ >
|
< #OCTAL_LITERAL: "0" (["0"-"7"])* >
}
TOKEN : /* IDENTIFIERS */
{
< IDENTIFIER: <LETTER> (<LETTER>|<DIGIT>)* >
|
< #LETTER: ["_","a"-"z","A"-"Z"] >
|
< #DIGIT: ["0"-"9"] >
}
/** Main production. */
ASTStart Start() #Start : {}
{
Expression() ";"
{ return jjtThis; }
}
/** An Expression. */
void Expression() : {}
{
AdditiveExpression()
}
/** An Additive Expression. */
void AdditiveExpression() : {}
{
(
MultiplicativeExpression() ( ( "+" | "-" ) MultiplicativeExpression() )*
) #Add(>1)
}
/** A Multiplicative Expression. */
void MultiplicativeExpression() : {}
{
(
UnaryExpression() ( ( "*" | "/" | "%" ) UnaryExpression() )*
) #Mult(>1)
}
/** A Unary Expression. */
void UnaryExpression() : {}
{
"(" Expression() ")" | Identifier() | Integer()
}
/** An Identifier. */
void Identifier() #MyID :
{
Token t;
}
{
t=<IDENTIFIER>
{
jjtThis.setName(t.image);
}
}
/** An Integer. */
void Integer() #Integer : {}
{
<INTEGER_LITERAL>
}
Visitor
In the previous example, we used the dump method in simpleNode to print the node tree, and modified the toString method of the relevant node to output the name of the corresponding node. However, this is not an elegant approach. A good program design should have single responsibilities and separated operations. For the examples in this chapter, no matter what kind of node it is, its node class should focus more on its own business logic. Access to the node tree should be separated from the node itself and defined externally. The Visitor provided by jjtree can meet this requirement.
The Visitor pattern allows developers to define a visitor object that can traverse nodes in the syntax tree and add new operations or functions without modifying the original node code.
Let’s make some modifications to the above code:
options {
MULTI=true;
VISITOR=true;
NODE_DEFAULT_VOID=true;
}
PARSER_BEGIN(Eg2)
package com.github.gambo.javacc.jjtree;
/** An Arithmetic Grammar. */
public class Eg2 {
/** Main entry point. */
public static void main(String args[]) {
System.out.println("Reading from standard input...");
Eg2 t = new Eg2(System.in);
try {
ASTStart n = t.Start();
Eg2Visitor v = new Eg2DumpVisitor();
n.jjtAccept(v, null);
System.out.println("Thank you.");
} catch (Exception e) {
System.out.println("Oops.");
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}
PARSER_END(Eg2)
SKIP :
{
" "
| "\t"
| "\n"
| "\r"
| <"//" (~["\n","\r"])* ("\n"|"\r"|"\r\n")>
| <"/*" (~["*"])* "*" (~["/"] (~["*"])* "*")* "/">
}
TOKEN : /* LITERALS */
{
< INTEGER_LITERAL:
<DECIMAL_LITERAL> (["l","L"])?
| <HEX_LITERAL> (["l","L"])?
| <OCTAL_LITERAL> (["l","L"])?
>
|
< #DECIMAL_LITERAL: ["1"-"9"] (["0"-"9"])* >
|
< #HEX_LITERAL: "0" ["x","X"] (["0"-"9","a"-"f","A"-"F"])+ >
|
< #OCTAL_LITERAL: "0" (["0"-"7"])* >
}
TOKEN : /* IDENTIFIERS */
{
< IDENTIFIER: <LETTER> (<LETTER>|<DIGIT>)* >
|
< #LETTER: ["_","a"-"z","A"-"Z"] >
|
< #DIGIT: ["0"-"9"] >
}
/** Main production. */
ASTStart Start() #Start : {}
{
Expression() ";"
{ return jjtThis; }
}
/** An Expression. */
void Expression() : {}
{
AdditiveExpression()
}
/** An Additive Expression. */
void AdditiveExpression() : {}
{
(
MultiplicativeExpression() ( ( "+" | "-" ) MultiplicativeExpression() )*
) #Add(>1)
}
/** A Multiplicative Expression. */
void MultiplicativeExpression() : {}
{
(
UnaryExpression() ( ( "*" | "/" | "%" ) UnaryExpression() )*
) #Mult(>1)
}
/** A Unary Expression. */
void UnaryExpression() : {}
{
"(" Expression() ")" | Identifier() | Integer()
}
/** An Identifier. */
void Identifier() #MyOtherID :
{
Token t;
}
{
t=<IDENTIFIER>
{
jjtThis.setName(t.image);
}
}
/** An Integer. */
void Integer() #Integer : {}
{
<INTEGER_LITERAL>
}
First, VISITOR=true; in the option area means turning on the visitor mode. At this time, JJTree will insert a 'jjtAccept()' method into all node classes it generates, and generate a visitor interface that can be implemented and passed to the node for acceptance. . We can take a look at the generated code.
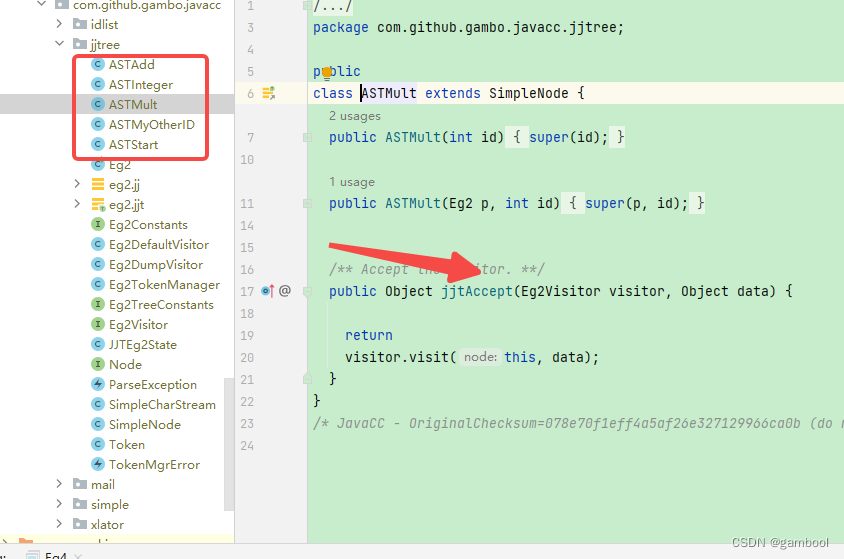
The generated Visitor interface is as follows:
package com.github.gambo.javacc.jjtree;
public interface Eg2Visitor
{
public Object visit(SimpleNode node, Object data);
public Object visit(ASTStart node, Object data);
public Object visit(ASTAdd node, Object data);
public Object visit(ASTMult node, Object data);
public Object visit(ASTMyOtherID node, Object data);
public Object visit(ASTInteger node, Object data);
}You can see that corresponding visit methods are generated for all non-#voild nodes. Next, let's take a look at the implementation of Visitor:
package com.github.gambo.javacc.jjtree;
public class Eg2DumpVisitor implements Eg2Visitor
{
private int indent = 0;
private String indentString() {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < indent; ++i) {
sb.append(' ');
}
return sb.toString();
}
public Object visit(SimpleNode node, Object data) {
System.out.println(indentString() + node +
": acceptor not unimplemented in subclass?");
++indent;
data = node.childrenAccept(this, data);
--indent;
return data;
}
public Object visit(ASTStart node, Object data) {
System.out.println(indentString() + node);
++indent;
data = node.childrenAccept(this, data);
--indent;
return data;
}
public Object visit(ASTAdd node, Object data) {
System.out.println(indentString() + node);
++indent;
data = node.childrenAccept(this, data);
--indent;
return data;
}
public Object visit(ASTMult node, Object data) {
System.out.println(indentString() + node);
++indent;
data = node.childrenAccept(this, data);
--indent;
return data;
}
public Object visit(ASTMyOtherID node, Object data) {
System.out.println(indentString() +"Identifier:"+ node.getName());
++indent;
data = node.childrenAccept(this, data);
--indent;
return data;
}
public Object visit(ASTInteger node, Object data) {
System.out.println(indentString() + node);
++indent;
data = node.childrenAccept(this, data);
--indent;
return data;
}
}
/*end*/
You can see that the current node tree printing is implemented in the visit method of each node.
data = node.childrenAccept(this, data); This line of code represents the method of calling the jjAccept method of the current node's child node to trigger the child node's visit:
public Object jjtAccept(Eg2Visitor visitor, Object data){
return visitor.visit(this, data);
}
/** Accept the visitor. **/
public Object childrenAccept(Eg2Visitor visitor, Object data){
if (children != null) {
for (int i = 0; i < children.length; ++i) {
children[i].jjtAccept(visitor, data);
}
}
return data;
}The introductory example of this article is adapted from the example in the source code. In subsequent chapters, we will use jjtree to demonstrate some more in-depth cases.
Sample code in the article: GitHub - ziyiyu/javacc-tutorial: javacc tutorial