Introduction to DataBend

Databend is an open source, cloud-native, and real-time analytics modern data warehouse designed to provide efficient data storage and processing capabilities. It is developed in Rust language and supports Apache Arrow format for high-performance columnar storage and query processing.
main feature:
- Cloud-native design : Databend is built on Kubernetes and has elastic scaling and horizontal expansion capabilities, and can be easily deployed in public cloud or private cloud environments.
- SQL support : Databend has complete SQL query functions and is compatible with the MySQL protocol, allowing users to use familiar SQL syntax for data query and processing.
- Performance optimization : Databend enables fast reading and analysis of large-scale data sets through a vectorized query execution engine and columnar storage technology.
- Object storage integration : Databend can store data on various object storage services, such as AWS S3, Azure Blob Storage, Google Cloud Storage, etc., to achieve low-cost large-scale storage.
- Real-time analysis : Databend supports real-time data ingestion and instant query response, and is suitable for application scenarios such as BI analysis, log analysis, and real-time reports.
- Community-driven : As an open source project, Databend is maintained and contributed by an active community of developers, and is continuously iteratively updated to add new features and improve existing features.
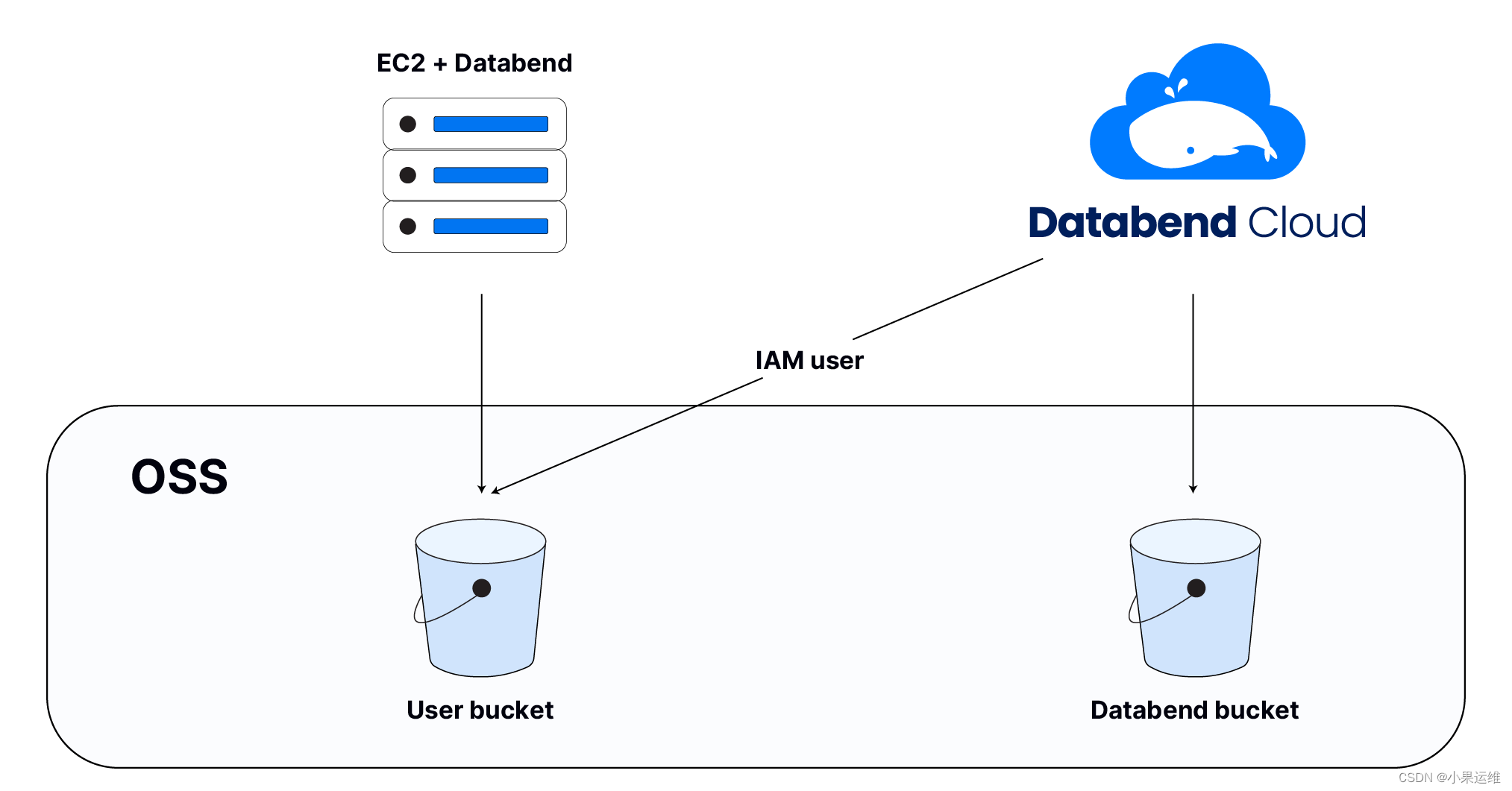
Example of usage scenario:
- Data analysts can use Databend to perform complex data queries and data analysis.
- Developers can build real-time data pipelines, write streaming data to Databend and query and analyze it immediately.
- Data scientists can combine Databend and other tools (such as Python or R) to perform data preprocessing before training the machine learning model.
Deployment and usage steps:
- Download or clone Databend's source code or binary package.
- Configure the required environment variables and service parameters according to the official documentation, such as database URL, connection credentials, and object storage access information.
- Start the Databend service. Start, stop and management operations can usually be completed through command line tools.
- Use a MySQL client or an application that supports the MySQL protocol to connect to the Databend database and start creating tables, inserting data, and executing SQL queries.
Databend Cloud - Open Source Cloud Data Warehouse Alternative to Snowflake | Databend Cloud
Databend installation
The following is a simplified Databend installation and configuration step. The specific details may be adjusted according to the actual situation. Please refer to the latest official documents for operation.
1. Environment preparation
Make sure the Rust toolchain (Rustup) and Docker are installed on your machine. If it is not installed yet, please refer to the following link to install it:
2. Install Databend
Compile and install Databend using the Rust toolchain:
# 克隆 Databend 仓库
git clone https://github.com/datafuselabs/databend.git
cd databend
# 使用 nightly 版本的 Rust 编译器构建 Databend
rustup default nightly
cargo build --release
# 创建 Databend 的数据存储目录(例如 /var/lib/databend)
sudo mkdir -p /var/lib/databend
sudo chown $(id -u):$(id -g) /var/lib/databend3. Configure and run Databend
Databend provides deployment methods in stand-alone mode and distributed mode. Here we first introduce the configuration and startup in stand-alone mode:
# 运行一个单节点的 Databend 服务
./target/release/databend-server --config-path=config.toml.example
# 或者如果你想在后台运行(daemon mode),可以加上 `--log-file` 参数指定日志文件
./target/release/databend-server --config-path=config.toml.example --log-file=/var/log/databend/server.log &The above command config.toml.example is a sample configuration file, you need to modify it according to actual needs. For example, set the listening address, port, data directory and other information.
4. Configure database connection
By default, after Databend is started, it will listen on the local 3307 port as the SQL query interface. You can connect to Databend through any client that supports the MySQL protocol.
mysql -h localhost -P 3307 -u root5. Configure persistent storage (optional)
If you want to store data persistently in a certain location (such as S3 or MinIO), you need to add the corresponding storage backend in the configuration file and provide the corresponding access credentials.
6. Distributed deployment
For production environments or large-scale testing, you may need to deploy a multi-node cluster. Please refer to Databend's Kubernetes Helm Chart or Docker Compose file to build a distributed cluster.
Precautions:
- In a production environment, please ensure that security-related options, such as password encryption, access control, etc., are configured correctly.
- For persistent storage support, Databend can be configured to use various object storage services, including but not limited to AWS S3, MinIO, Google Cloud Storage, etc.
Please consult the latest version of the Databend documentation for detailed guidance and best practices: Databend - The Future of Cloud Data Analytics. | Databend
Installation and configuration based on Docker
atabend provides Docker images, allowing users to quickly deploy and run Databend databases through Docker containers. The following is a detailed configuration step for installing Databend using Docker:
1. Pull the Databend Docker image
First, make sure Docker is installed and execute the following command in the terminal to pull the latest Databend Docker image. Please note that the actual image name may change with version updates, please refer to the official documentation for the latest version.
docker pull databend-docker:databend-query # 查询引擎(databend-query)
docker pull databend-docker:databend-meta # 元数据服务(databend-meta)2. Create a directory for persistent storage (optional)
In order to retain data after the container is restarted, you can create a directory on the local host for persistent storage of metadata and service data:
mkdir -p /path/to/databend/meta-data
mkdir -p /path/to/databend/query-data3. Run the Databend Meta service
docker run -d --name databend-meta \
-v /path/to/databend/meta-data:/var/lib/databend-meta \
-e "DATABEND_QUERY_HTTP_PORT=8001" \
databend-docker:databend-metaHere, -v the parameters map directories on the host to /var/lib/databend-meta directories inside the container.
4. Run the Databend Query engine
docker run -d --name databend-query \
--link databend-meta:databend-meta \
-v /path/to/databend/query-data:/var/lib/databend-query \
-p 8080:8080 \
databend-docker:databend-queryThe parameters here --link are used to connect the query engine and the metadata service container so that the query engine can access the metadata service. At the same time, -p the parameters are used to map the HTTP port of the query engine to the host.
5. Configure environment variables (optional)
As needed, you can set other environment variables to configure the behavior of the database, such as log level, listening address, etc. Consult the Databend documentation for a list of available environment variables.
6. Access and test Databend
After starting the container, you can access the Databend query engine in the following ways:
- HTTP API : accessed in the browser or Postman
http://localhost:8080/(if the local port is mapped). - SQL Client : Connect to Databend through MySQL client tools such as MySQL Workbench or command line tools. The port is usually
3307. The user name and password may require viewing specific documentation or environment variable configuration.
Please always refer to the latest official documentation, as specific parameters and configurations may change over time. The above examples are given based on an assumed default configuration.
Installation and use under Centos 9
The general steps for installing Databend on CentOS 9 system (subject to the latest official documents):
1. Make sure the environment is ready
- The CentOS 9 system has already installed the necessary development tools and dependent libraries.
- The Rust programming language environment is installed.
# 更新系统并安装必要软件包
sudo dnf update -y
sudo dnf install -y curl git make gcc-c++ zlib-devel openssl-devel
# 安装Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source $HOME/.cargo/env2. Install Databend
- Use Rust's Cargo to build and install the server part of Databend (metasrv and databend-query).
# 克隆Databend源代码
git clone https://github.com/datafuselabs/databend.git
cd databend
# 构建并安装
cargo build --release --bin metasrv
cargo build --release --bin databend-query
# 创建用于存放运行时数据的目录
mkdir -p /var/lib/databend/meta /var/lib/databend/data3. Configure and start the service
- Configure Databend's metadata storage, log path and other parameters, and start the service.
# 编写配置文件(这里仅提供示例配置)
cat << EOF > /etc/databend/config.toml
[meta_service]
listen = "127.0.0.1:9191"
data_dir = "/var/lib/databend/meta"
[databend_query]
http_server_address = "0.0.0.0:8000"
query_pool_size = 4
local_data_path = "/var/lib/databend/data"
EOF
# 启动metasrv服务
./target/release/metasrv --config /etc/databend/config.toml &
# 启动databend-query服务
./target/release/databend-query --config /etc/databend/config.toml &4. Verify installation
- Verify by connecting to the Databend Query API port locally or over the network.
# 如果是在本地机器上安装,可以尝试执行一个简单的查询
curl -G "http://localhost:8000/v1/query" --data-urlencode 'sql=SELECT version()'
# 应该返回类似如下信息:
{"results":[{"meta":{"columns":[{"name":"version","type":5}],"rows":[["nightly"]]},"stats":{"elapsed_time":...}}]}Precautions:
- In actual deployment, you may need to set up persistent storage for Databend, such as mounting appropriate disk partitions or using cloud storage services.
- In the production environment, please make sure to use the stable version instead of the nightly version, and configure and manage it according to the officially recommended best practices.
- Databend also supports deployment through Docker containers. For production deployment, it is more convenient and easier to maintain using Docker Compose or Kubernetes.
Please always consult the latest version of Databend official documentation for detailed installation instructions: https://docs.databend.rs/
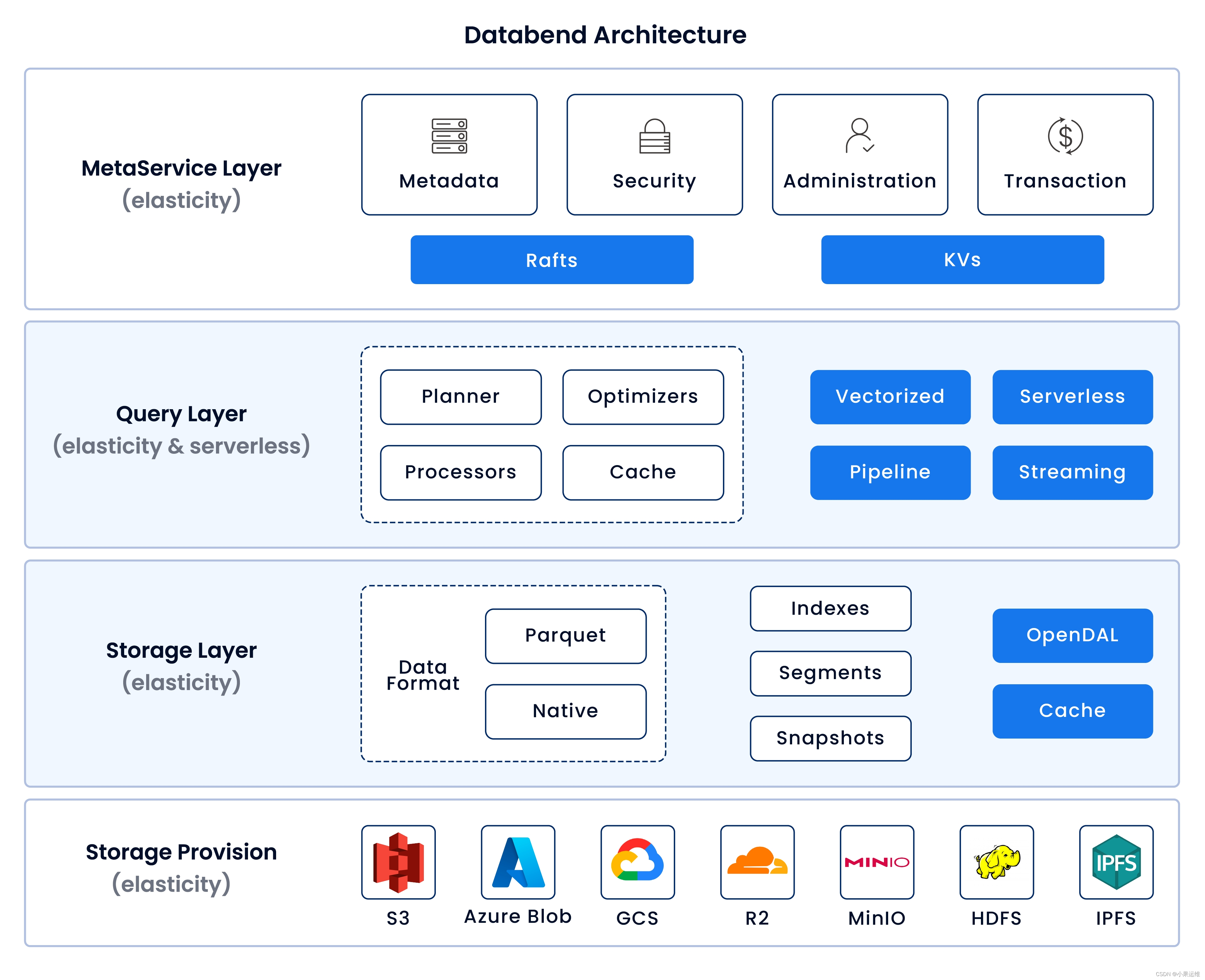
Combination of Databend, lakeFS and MinIO
Function introduction of Databend, lakeFS and MinIO:
-
Data bend:
- Databend is an open source real-time analytical data warehouse built on Rust and compatible with the Apache Arrow format.
- It provides a cloud-native architecture similar to Snowflake, supporting high-concurrency queries and near-real-time data insertion and updates.
- Supports SQL query language, can process PB-level data and provide an interactive analysis experience with sub-second latency.
- It integrates multiple data sources and can connect various BI tools through JDBC/ODBC for data analysis.
-
lakeFS:
- lakeFS is an object storage management tool based on Git-like branch model, suitable for AWS S3 or other S3-compatible storage services (such as MinIO).
- It provides version control functions for data lakes, allowing users to create branches, merges, rollbacks and other operations on data sets stored in object storage.
- Users can conduct data development, testing and production processes on different branches, which enhances data asset management capabilities and simplifies the governance and auditing of data pipelines.
-
MinIO :
- MinIO is a high-performance, distributed object storage system that is fully compatible with Amazon S3 API.
- It can be deployed locally or in the cloud for large-scale unstructured data storage, including raw data, backup and archive data required for big data analysis.
- Provides high availability, scalability and security, and is suitable for use as an object storage solution within an enterprise or in a hybrid cloud environment.
Methods and examples of combining the three:
Suppose you want to use MinIO as the underlying storage, use lakeFS to perform version management and branch operations on the data on it, and use Databend to query and analyze the data. The following are the general configuration steps and usage:
Configuration steps:
-
Deploy MinIO :
- Install and start MinIO on a server cluster or a single machine, making sure it is network reachable and has the appropriate access and private keys configured.
-
Configure lakeFS
-
lakectl init <lakefs-server-url> my-repo s3://<minio-bucket-name>
-
-
Upload data to lakeFS
-
lakectl cp local-data.csv lakefs://my-repo/main/data.csv lakectl branch create my-repo/dev --parent main lakectl cp local-data-dev.csv lakefs://my-repo/dev/data.csv
-
-
Configure Databend data source :
- Set an S3 data source in Databend to point to one of the branches of lakeFS (such as the main branch), so that Databend can read the data under this branch for analysis.
- Update the catalog configuration file of Databend, add S3 storage connection information, and specify the bucket name (here will be the bucket virtualized by lakeFS) and the correct endpoint URL (lakeFS server address).
-
Execute queries in Databend
-
SELECT * FROM "s3://my-repo/main/data.csv" (format CSV);
-
Example scenario:
-
Data development stage :
- Development team members perform operations such as data cleaning and conversion on the dev branch on lakeFS, and submit the changes after completion.
-
Code review and merge :
- Merge changes from the dev branch to the main branch through the merge function of lakeFS.
-
Data verification and analysis :
- The data analyst selects the main branch as the data source in Databend and runs SQL queries to verify the data quality and analysis results.
-
Troubleshooting and rollback :
- If a problem is found with the main branch data, you can roll back to a specific version through lakeFS and merge it into the main branch after repair; Databend automatically obtains the latest version data for query and analysis.
Please note that actual integration requires detailed configuration of parameters according to respective official documents, and additional adaptation layers or middleware may be required to ensure seamless connection between components. Since the interfaces may change between projects, please check the latest documentation and guides.