
Author: Nami
Why does Cloud Message Queue Kafka version need to do codeless dump?
Cloud Message Queue Kafka version itself is a distributed stream processing platform with the characteristics of high throughput, low latency and scalability. It is widely used in real-time data processing and streaming data transmission scenarios. However, in order to integrate Cloud Message Queue Kafka version with other data sources and data destinations, additional development/components are required to achieve data transmission and synchronization, and customers require a large amount of investment in R&D, operation and maintenance, etc.
In order to improve research and development efficiency, Cloud Message Queue Kafka version cooperates with Alibaba Cloud products to support code-free, fully managed, and serverless features, and supports dumping from Cloud Message Queue Kafka version to OSS. The advantages of this feature are:
- Simple
<!---->
-
- Agile development, simple configuration can support this capability
- Easily dump OSS data of different applications
- No complex software and infrastructure required
<!---->
- Fully managed
<!---->
-
- Provide serverless computing capabilities
- Free operation and maintenance
- Mature functions
<!---->
- low cost
<!---->
-
- There is no additional charge for the Kafka version of Cloud Message Queue itself, and the underlying dependency function calculation is charged based on volume.
- Function Compute is deeply optimized for this scenario and combined with the architecture to achieve low cost: the introduction of CDN caching mechanism, dynamic calculation and derivative copy storage costs
- Certain fee reductions for product integration links
Cloud message queue Kafka version + OSS main application scenarios
-
Data backup and archiving
OSS provides data backup and archiving functions. Customers can choose to back up important data to OSS to provide data disaster recovery capabilities. OSS provides guarantees of data durability and reliability, ensuring data security and availability. At the same time, OSS also provides archive storage functions for long-term storage of infrequently accessed data. Customers can archive data into the archive storage category of OSS to save storage costs and perform data recovery as needed.
-
big data analysis
Alibaba Cloud's object storage OSS can be used as a storage platform for big data. Customers can store various types of big data files (such as log files, sensor data, user behavior data, etc.) in OSS for subsequent tasks such as data analysis, data mining, and machine learning. Customers can complete big data storage, processing and analysis tasks on Alibaba Cloud, achieving elastic expansion and high-performance big data processing.
-
Cache of FC calculation results
Alibaba Cloud Function Compute (FC) is an event-driven serverless computing service that helps users run code at lower costs and with higher elasticity. Alibaba Cloud Object Storage OSS is a cloud data storage service that provides secure, stable, and highly scalable cloud storage capabilities. FC is a stateless computing service and does not provide persistent local storage. Therefore, if you need to store and access data during function execution, you can store the data in OSS by combining it with OSS. This can achieve persistent storage of data and ensure that data will not be lost due to the transient nature of function calculations.
Introduction to code dump product capabilities

1. 0 Code Development: Dumps/Connector provides integration capabilities with various data sources and data destinations. By using the Cloud Message Queue Kafka version dump/Connector capability, developers do not need to write complex data integration code. They only need to configure the corresponding Connector to achieve data transmission and synchronization, which greatly simplifies the data integration process.
2. Configuration support: Users can flexibly configure forwarding rules and storage strategies according to their own needs and business scenarios. Whether it is forwarding based on dimensions such as time, keywords, topics, etc., or supporting storage based on dimensions such as folders, file names, etc., it can be implemented through simple configuration to meet personalized needs.
3. High reliability and fault tolerance: Dump/Connector ensures high reliability and fault tolerance of data. During data transmission, the Connector automatically handles data redundancy and fault recovery to ensure that data will not be lost or damaged. In this way, users do not need to pay attention to the details of data transmission and exception handling, and can focus more on the development of business logic.
4. Serverless: Computing resources can be automatically expanded and reduced according to the requested load. Compared with traditional pre-allocated servers, serverless can more flexibly adapt to actual needs and reduce resource waste and costs. The component is responsible for managing and maintaining the underlying infrastructure, and customers do not need to care about server configuration and management.
Instructions for use
Prerequisites
1. Cloud Message Queue Kafka version instance preparation [ 1]
- Dependencies are open, please see the creation premise [ 2]
Step 1: Create target service resources
Create a storage space (Bucket) in the object storage OSS console. For detailed steps, see Creating a Storage Space on the Console [ 3] .
This article takes the oss-sink-connector-bucket Bucket as an example.
Step 2: Create OSS Sink Connector and start it
Log in to the Cloud Message Queue Kafka version console [ 4] , and select a region in the resource distribution area of the overview page.
In the left navigation bar, select Connector Ecosystem Integration > Message Outflow (Sink).
On the message outflow (Sink) page, click Create task.
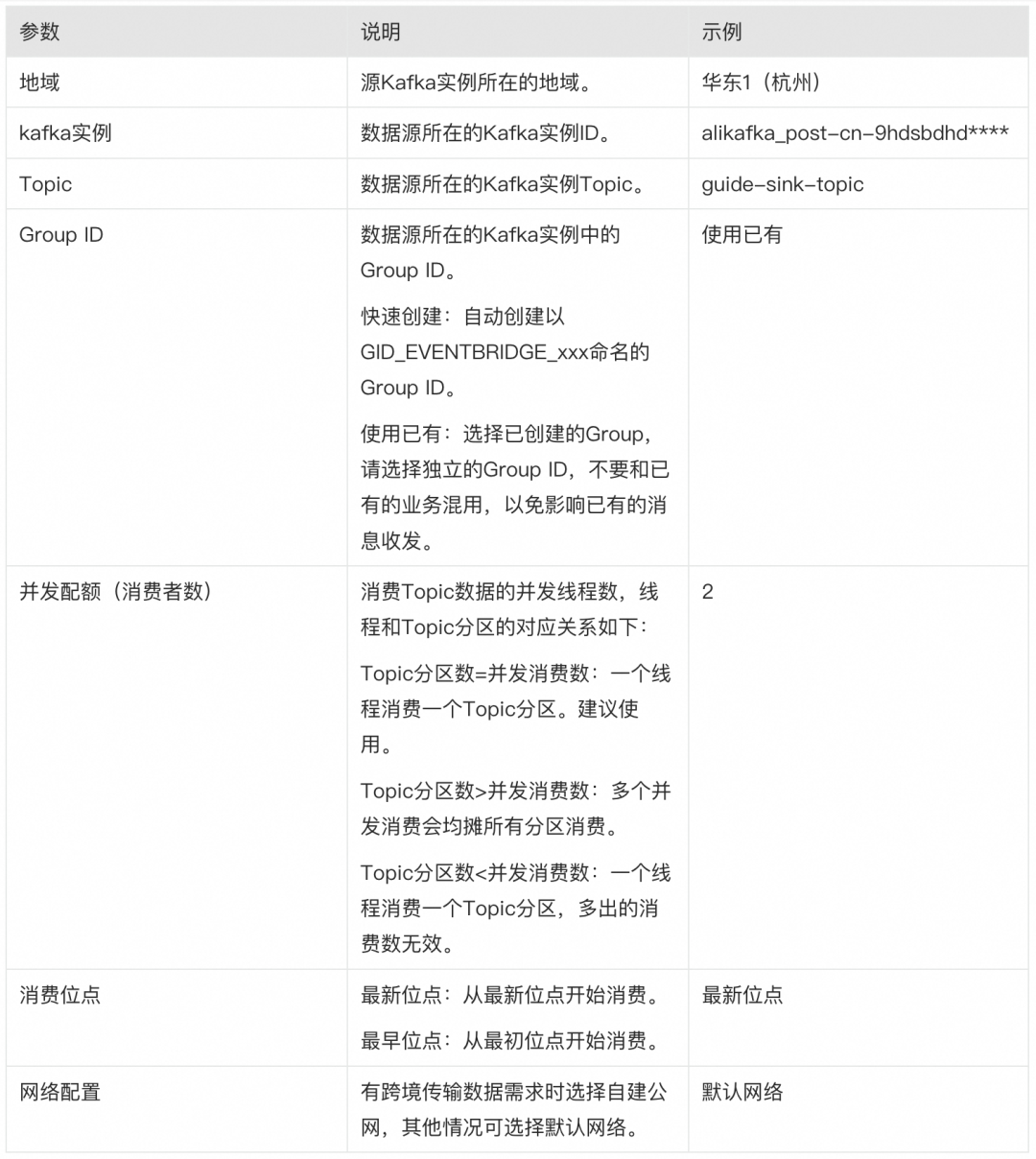
In the message outflow creation panel, configure the following parameters and click OK.
In the basic information area, set the task name and select the outflow type as OSS.
In the resource configuration area, set the following parameters.

After completing the above configuration, on the message outflow (Sink) page, find the newly created OSS Sink Connector task and click Start in the operation column on the right. When the status bar changes from starting to running, the Connector is created successfully.
Step 3: Test the OSS Sink Connector
On the message outflow (Sink) page, click the source topic in the event source column of the OSS Sink Connector task.
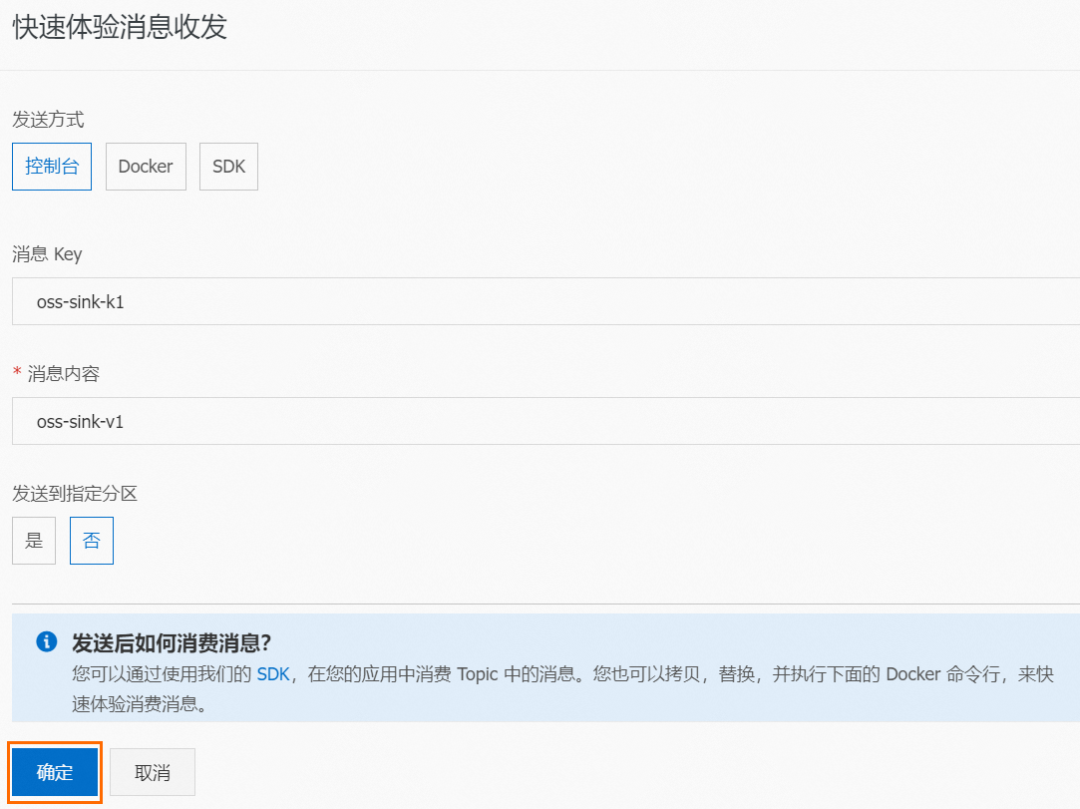
On the Topic details page, click Experience to send a message.
In the quick experience messaging panel, configure the message content as shown below, and then click OK.
On the message outflow (Sink) page, click the target bucket in the event target column of the OSS Sink Connector task.
On the Bucket page, select File Management > File List in the left navigation bar, and then enter the deepest path of the Bucket.
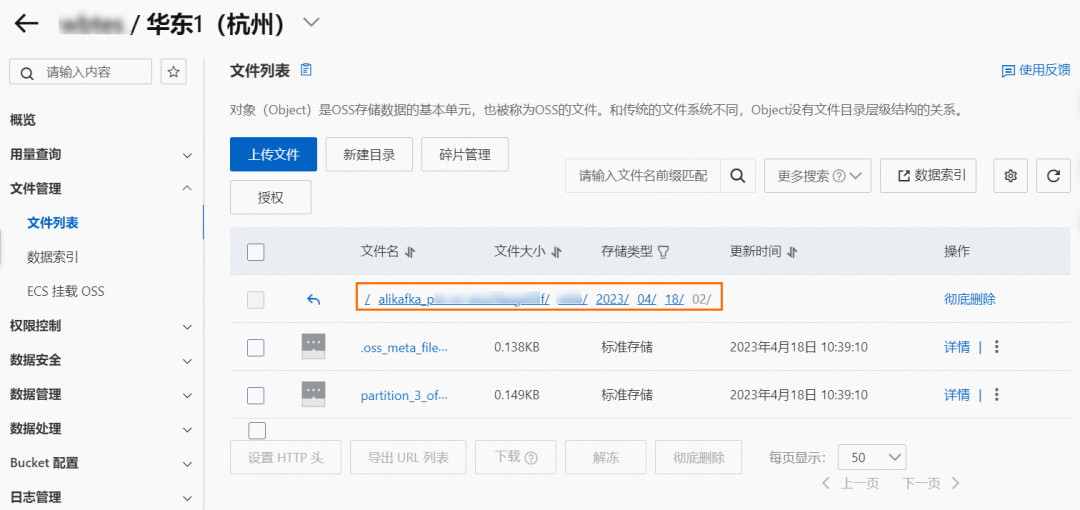
You can see that there are the following two types of Objects in this path:
- System meta file: The format is .oss_meta_file_partition_{partitionID}. The number of files is the same as the number of Partitions of the upstream topic. It is used to record batch information. You do not need to pay attention to it.
- Data file: The format is partition_{partitionID} offset {offset}_{8-bit Random string}. If multiple messages of a Partition are aggregated in an Object, the Offset in the Object name is the minimum Offset value in this batch of messages.
In the operation column to the right of the corresponding Object, select  > Download.
> Download.
Open the downloaded file to view the message content.

As shown in the figure, multiple messages are separated by newlines.
Related Links:
[1] Cloud Message Queue Kafka version instance preparation
https://help.aliyun.com/zh/apsaramq-for-kafka/getting-started/getting-started-overview
[2] Create premise
https://help.aliyun.com/zh/apsaramq-for-kafka/user-guide/prerequisites#concept-2323967
[3] Console creates storage space
https://help.aliyun.com/zh/oss/getting-started/console-quick-start#task-u3p-3n4-tdb
[4] Cloud Message Queue Kafka version console
Click here , the cloud message queue Kafka version V3 public beta is officially launched!
Bilibili crashed twice, Tencent’s “3.29” first-level accident... Taking stock of the top ten downtime accidents in 2023 Vue 3.4 “Slam Dunk” released MySQL 5.7, Moqu, Li Tiaotiao… Taking stock of the “stop” in 2023 More” (open source) projects and websites look back on the IDE of 30 years ago: only TUI, bright background color... Vim 9.1 is released, dedicated to Bram Moolenaar, the father of Redis, "Rapid Review" LLM Programming: Omniscient and Omnipotent&& Stupid "Post-Open Source "The era has come: the license has expired and cannot serve the general public. China Unicom Broadband suddenly limited the upload speed, and a large number of users complained. Windows executives promised improvements: Make the Start Menu great again. Niklaus Wirth, the father of Pascal, passed away.